

A large-scale neural network training framework for generalized estimation of single-trial population dynamics
- PMID: 36443486
- PMCID: PMC9825111
- DOI: 10.1038/s41592-022-01675-0
A large-scale neural network training framework for generalized estimation of single-trial population dynamics
Abstract
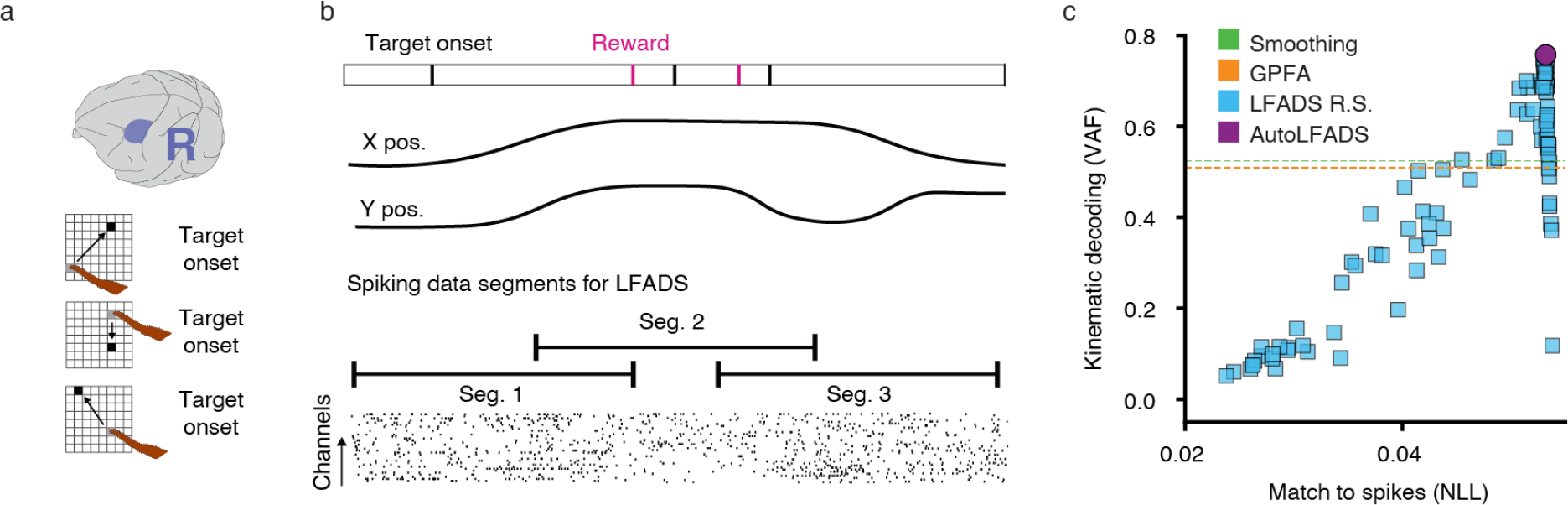
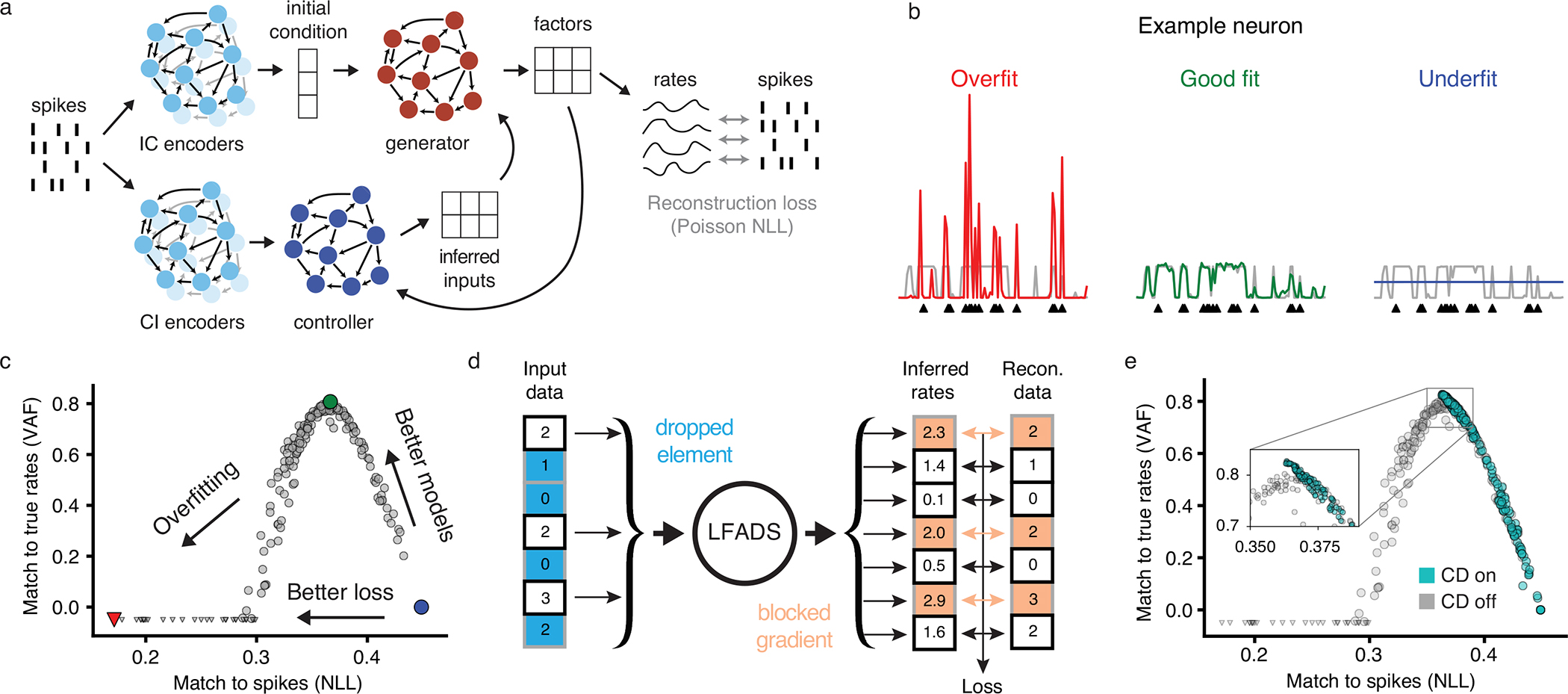
Achieving state-of-the-art performance with deep neural population dynamics models requires extensive hyperparameter tuning for each dataset. AutoLFADS is a model-tuning framework that automatically produces high-performing autoencoding models on data from a variety of brain areas and tasks, without behavioral or task information. We demonstrate its broad applicability on several rhesus macaque datasets: from motor cortex during free-paced reaching, somatosensory cortex during reaching with perturbations, and dorsomedial frontal cortex during a cognitive timing task.
© 2022. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
Competing Interests
CP is a consultant to Synchron and Meta (Reality Labs). These entities did not support this work, have a role in the study, or have any financial interests related to this work.
Figures






References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
