

Improving the accuracy of single-trial fMRI response estimates using GLMsingle
- PMID: 36444984
- PMCID: PMC9708069
- DOI: 10.7554/eLife.77599
Improving the accuracy of single-trial fMRI response estimates using GLMsingle
Abstract
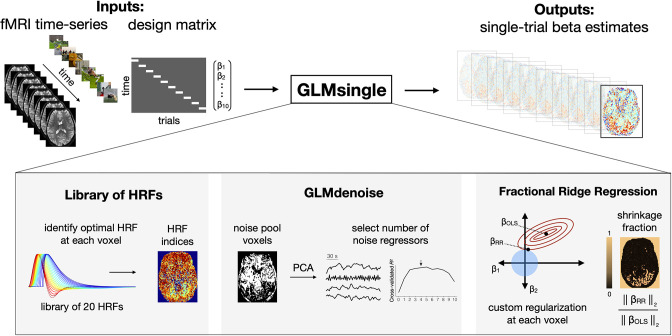
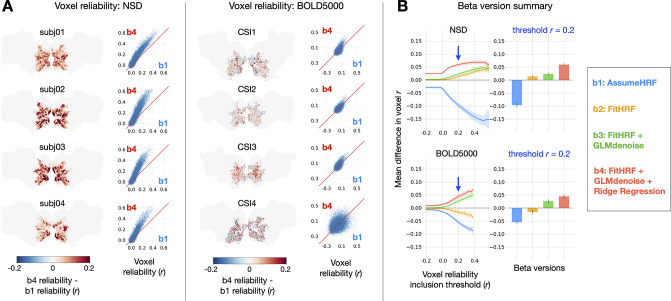
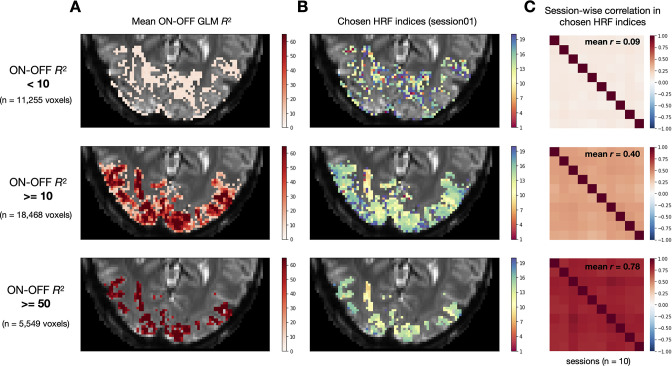
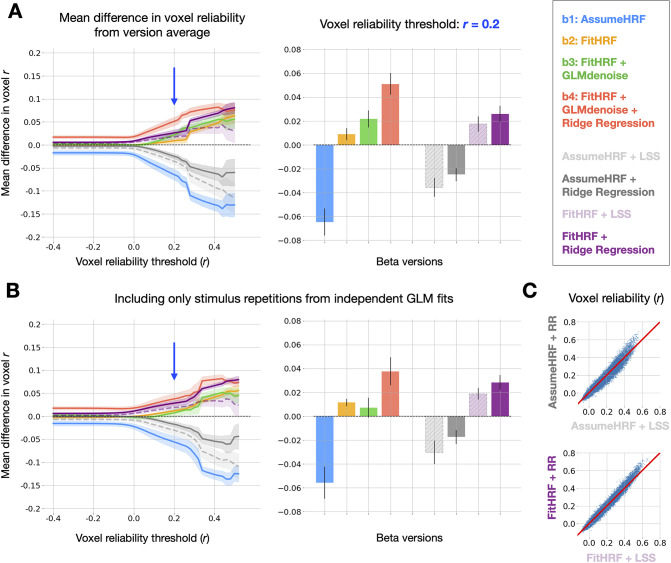
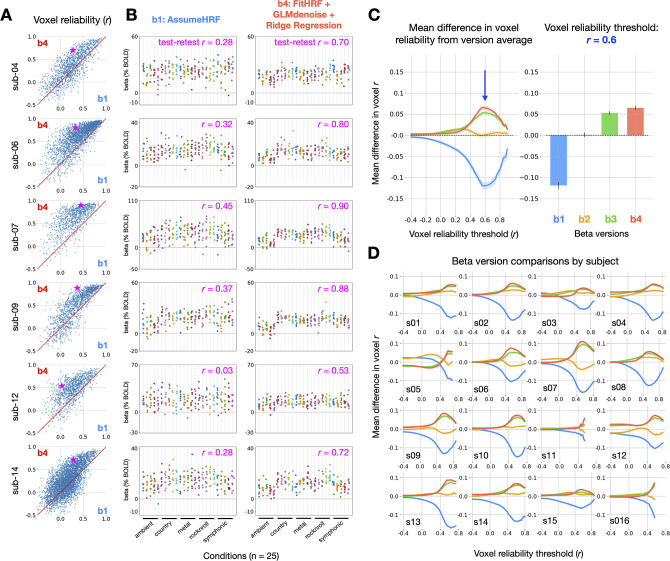
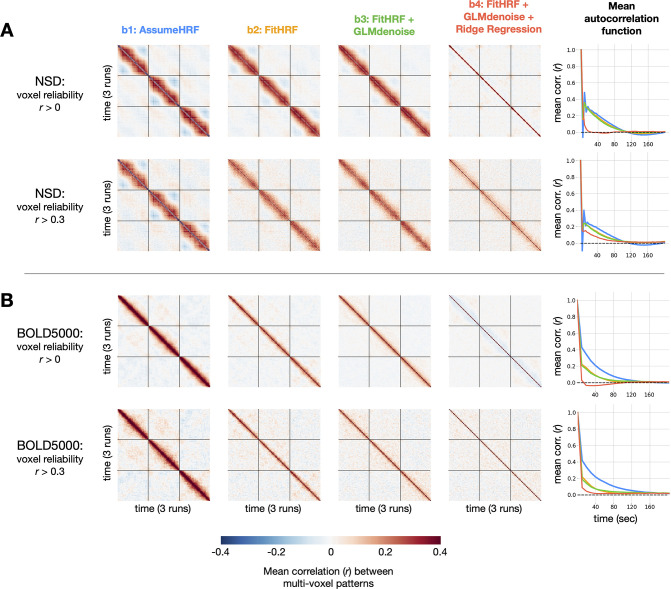
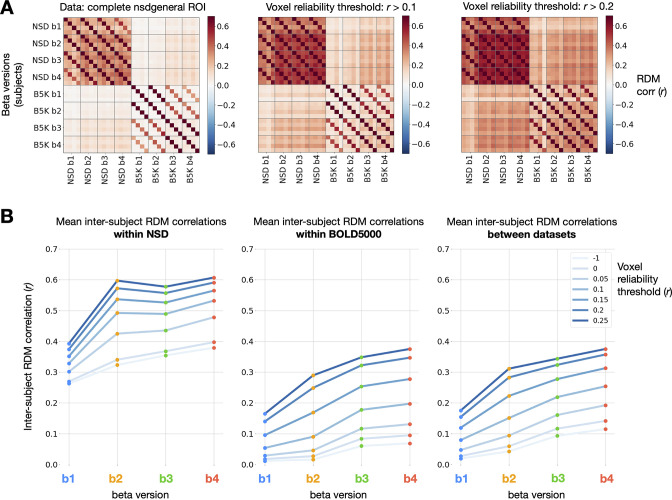
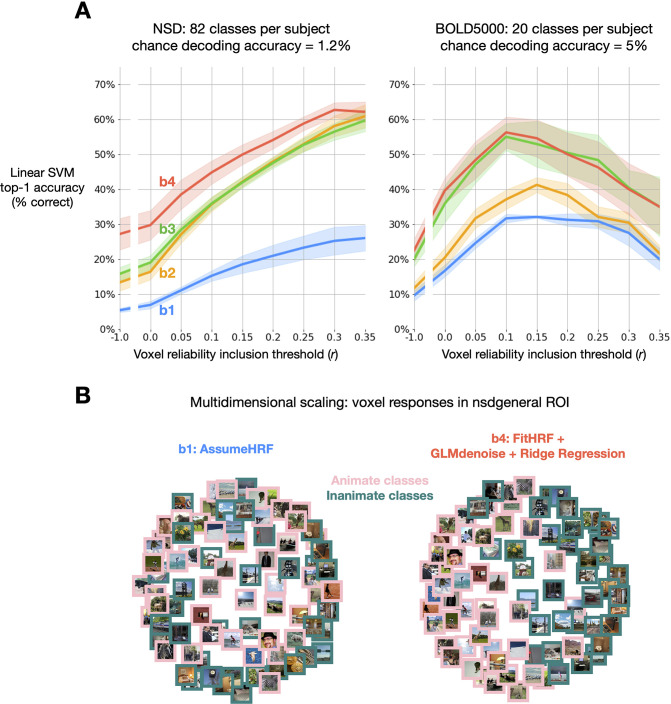
Advances in artificial intelligence have inspired a paradigm shift in human neuroscience, yielding large-scale functional magnetic resonance imaging (fMRI) datasets that provide high-resolution brain responses to thousands of naturalistic visual stimuli. Because such experiments necessarily involve brief stimulus durations and few repetitions of each stimulus, achieving sufficient signal-to-noise ratio can be a major challenge. We address this challenge by introducing GLMsingle, a scalable, user-friendly toolbox available in MATLAB and Python that enables accurate estimation of single-trial fMRI responses (glmsingle.org). Requiring only fMRI time-series data and a design matrix as inputs, GLMsingle integrates three techniques for improving the accuracy of trial-wise general linear model (GLM) beta estimates. First, for each voxel, a custom hemodynamic response function (HRF) is identified from a library of candidate functions. Second, cross-validation is used to derive a set of noise regressors from voxels unrelated to the experiment. Third, to improve the stability of beta estimates for closely spaced trials, betas are regularized on a voxel-wise basis using ridge regression. Applying GLMsingle to the Natural Scenes Dataset and BOLD5000, we find that GLMsingle substantially improves the reliability of beta estimates across visually-responsive cortex in all subjects. Comparable improvements in reliability are also observed in a smaller-scale auditory dataset from the StudyForrest experiment. These improvements translate into tangible benefits for higher-level analyses relevant to systems and cognitive neuroscience. We demonstrate that GLMsingle: (i) helps decorrelate response estimates between trials nearby in time; (ii) enhances representational similarity between subjects within and across datasets; and (iii) boosts one-versus-many decoding of visual stimuli. GLMsingle is a publicly available tool that can significantly improve the quality of past, present, and future neuroimaging datasets sampling brain activity across many experimental conditions.
Keywords: GLM; MVPA; RSA; denoising; fMRI pre-processing; human; large-scale datasets; neuroscience; voxel reliability.
© 2022, Prince et al.
Conflict of interest statement
JP, IC, JK, JP, MT, KK No competing interests declared
Figures
References
-
- Allen EJ, St-Yves G, Wu Y, Breedlove JL, Prince JS, Dowdle LT, Nau M, Caron B, Pestilli F, Charest I, Hutchinson JB, Naselaris T, Kay K. A massive 7T fMRI dataset to bridge cognitive neuroscience and artificial intelligence. Nature Neuroscience. 2022;25:116–126. doi: 10.1038/s41593-021-00962-x. - DOI - PubMed
-
- Bai B, Kantor P. A shape-based finite impulse response model for functional brain images. 2007 4th IEEE International Symposium on Biomedical Imaging: From Nano to Macro; 2007. pp. 440–443. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
