

Semi-supervised adversarial discriminative domain adaptation
- PMID: 36466775
- PMCID: PMC9707164
- DOI: 10.1007/s10489-022-04288-4
Semi-supervised adversarial discriminative domain adaptation
Abstract
Domain adaptation is a potential method to train a powerful deep neural network across various datasets. More precisely, domain adaptation methods train the model on training data and test that model on a completely separate dataset. The adversarial-based adaptation method became popular among other domain adaptation methods. Relying on the idea of GAN, the adversarial-based domain adaptation tries to minimize the distribution between the training and testing dataset based on the adversarial learning process. We observe that the semi-supervised learning approach can combine with the adversarial-based method to solve the domain adaptation problem. In this paper, we propose an improved adversarial domain adaptation method called Semi-Supervised Adversarial Discriminative Domain Adaptation (SADDA), which can outperform other prior domain adaptation methods. We also show that SADDA has a wide range of applications and illustrate the promise of our method for image classification and sentiment classification problems.
Keywords: Domain adaptation; Semi-supervised adversarial discriminative domain adaptation; Semi-supervised domain adaptation.
© The Author(s), under exclusive licence to Springer Science+Business Media, LLC, part of Springer Nature 2022. Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Figures

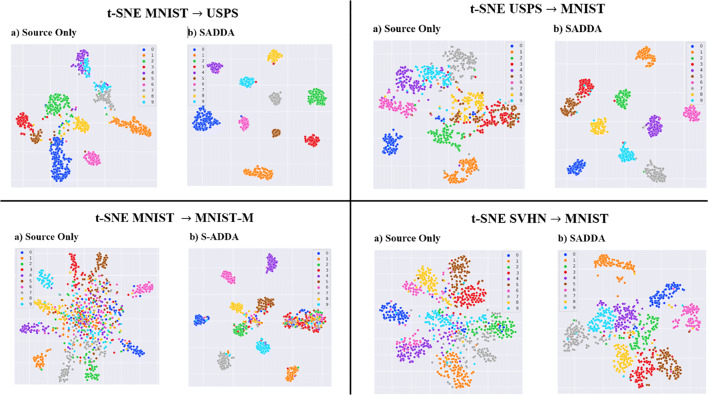
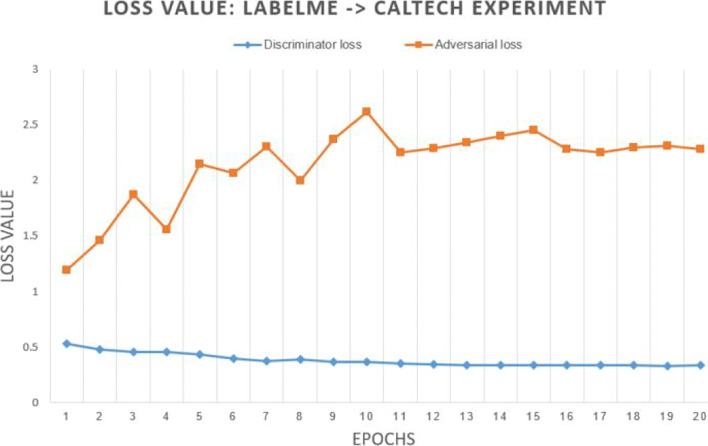

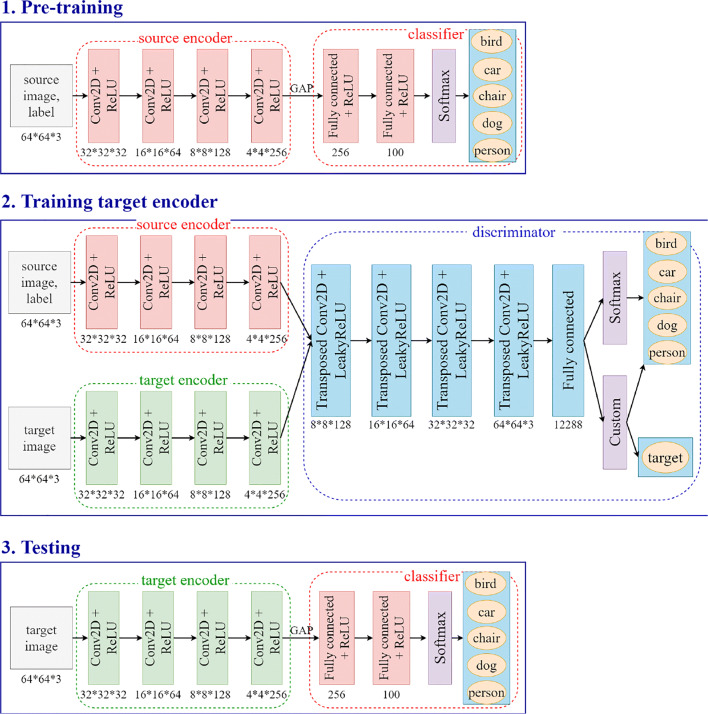

References
-
- Gretton A, Smola A, Huang J, Schmittfull M, Borgwardt K, Schölkopf B (2009) Covariate shift and local learning by distribution matching, pp 131–160. Cambridge, MA USA: MIT Press
-
- Long M, Cao Y, Wang J, Jordan MI (2015) Learning transferable features with deep adaptation networks. arXiv:1502.02791 - PubMed
-
- Nguyen A, Nguyen N, Tran K, Tjiputra E, Tran QD (2020) Autonomous navigation in complex environments with deep multimodal fusion network. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS)
-
- Donahue J, Jia Y, Vinyals O, Hoffman J, Zhang N, Tzeng E, Darrell T (2013) Decaf: A deep convolutional activation feature for generic visual recognition
-
- Lecun Y, Bottou L, Bengio Y, Haffner P. Gradient-based learning applied to document recognition. Proc IEEE. 1998;86(11):2278–2324. doi: 10.1109/5.726791. - DOI
LinkOut - more resources
Full Text Sources