

The conserved domain database in 2023
- PMID: 36477806
- PMCID: PMC9825596
- DOI: 10.1093/nar/gkac1096
The conserved domain database in 2023
Abstract
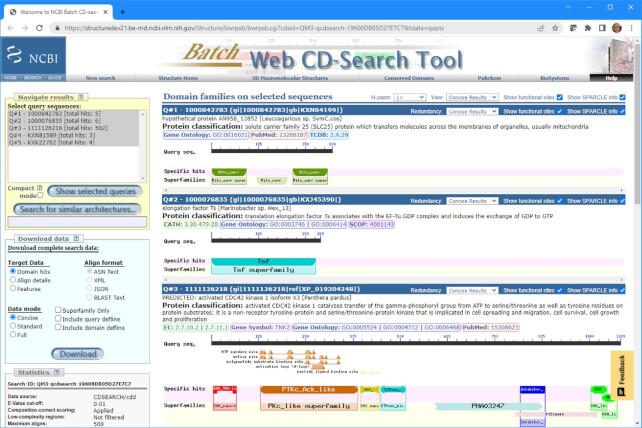
NLM's conserved domain database (CDD) is a collection of protein domain and protein family models constructed as multiple sequence alignments. Its main purpose is to provide annotation for protein and translated nucleotide sequences with the location of domain footprints and associated functional sites, and to define protein domain architecture as a basis for assigning gene product names and putative/predicted function. CDD has been available publicly for over 20 years and has grown substantially during that time. Maintaining an archive of pre-computed annotation continues to be a challenge and has slowed down the cadence of CDD releases. CDD curation staff builds hierarchical classifications of large protein domain families, adds models for novel domain families via surveillance of the protein 'dark matter' that currently lacks annotation, and now spends considerable effort on providing names and attribution for conserved domain architectures. CDD can be accessed at https://www.ncbi.nlm.nih.gov/Structure/cdd/cdd.shtml.
Published by Oxford University Press on behalf of Nucleic Acids Research 2022.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
