

That was not what I was aiming at! Differentiating human intent and outcome in a physically dynamic throwing task
- PMID: 36530466
- PMCID: PMC9735099
- DOI: 10.1007/s10514-022-10074-5
That was not what I was aiming at! Differentiating human intent and outcome in a physically dynamic throwing task
Abstract
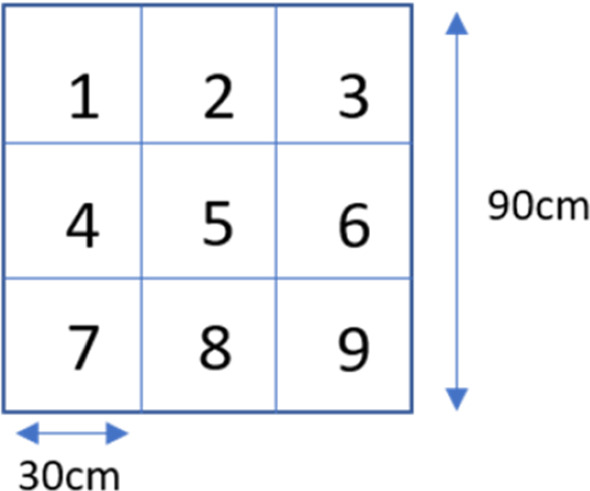
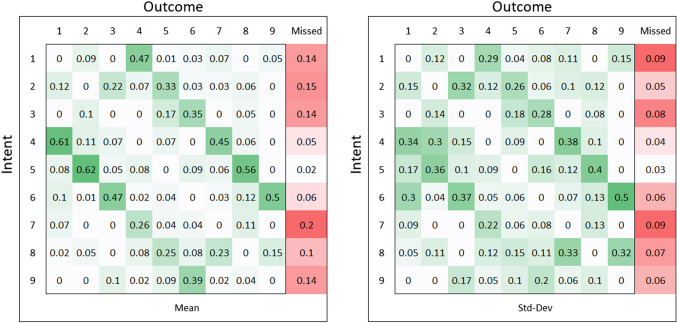
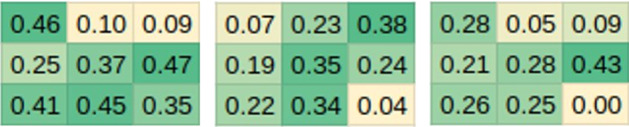
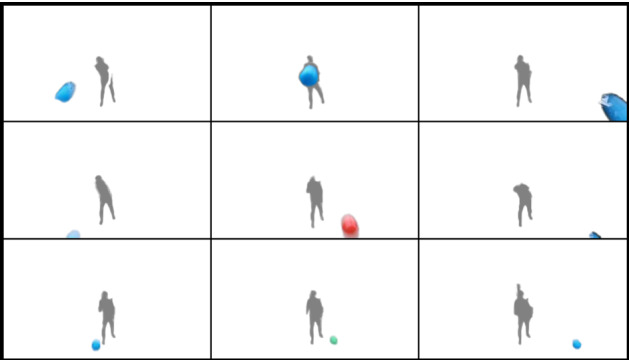
Recognising intent in collaborative human robot tasks can improve team performance and human perception of robots. Intent can differ from the observed outcome in the presence of mistakes which are likely in physically dynamic tasks. We created a dataset of 1227 throws of a ball at a target from 10 participants and observed that 47% of throws were mistakes with 16% completely missing the target. Our research leverages facial images capturing the person's reaction to the outcome of a throw to predict when the resulting throw is a mistake and then we determine the actual intent of the throw. The approach we propose for outcome prediction performs 38% better than the two-stream architecture used previously for this task on front-on videos. In addition, we propose a 1D-CNN model which is used in conjunction with priors learned from the frequency of mistakes to provide an end-to-end pipeline for outcome and intent recognition in this throwing task.
Keywords: Computer vision; Human robot interaction; Intent recognition; Surface cues.
© The Author(s), under exclusive licence to Springer Science+Business Media, LLC, part of Springer Nature 2022, Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Conflict of interest statement
Conflict of interestThe authors declare that they have no affiliations with or involvement in any organization or entity with any conflict of interest regarding the subject matter or materials discussed in this manuscript.
Figures





References
-
- Akilan T, Wu QJ, Safaei A, Huo J, Yang Y. A 3D CNN-LSTM-based image-to-image foreground segmentation. IEEE Transactions on Intelligent Transportation Systems. 2019;21(3):959–971. doi: 10.1109/TITS.2019.2900426. - DOI
-
- Alikhani, M., Khalid, B., Shome, R., Mitash, C., Bekris, K. E., & Stone, M. (2020). That and there: Judging the intent of pointing actions with robotic arms. In AAAI (pp. 10343–10351).
-
- Arriaga, O., Valdenegro-Toro, M., & Plöger, P. (2017). Real-time convolutional neural networks for emotion and gender classification. Preprint arXiv:1710.07557
-
- Cheuk T. Can AI be racist? Color-evasiveness in the application of machine learning to science assessments. Science Education. 2021;105(5):825–836. doi: 10.1002/sce.21671. - DOI
LinkOut - more resources
Full Text Sources