

Model-based prioritization for acquiring protection
- PMID: 36534704
- PMCID: PMC9810162
- DOI: 10.1371/journal.pcbi.1010805
Model-based prioritization for acquiring protection
Abstract
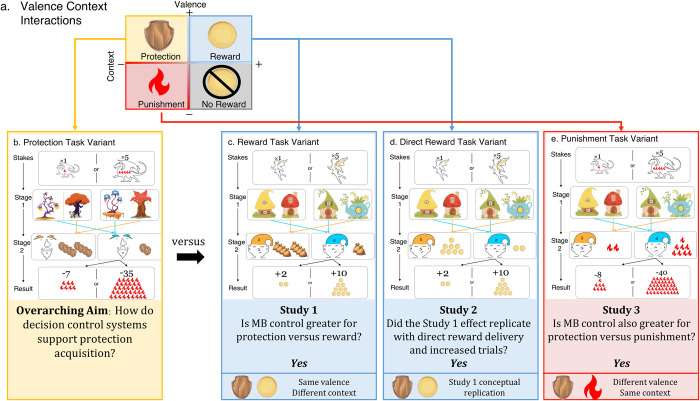
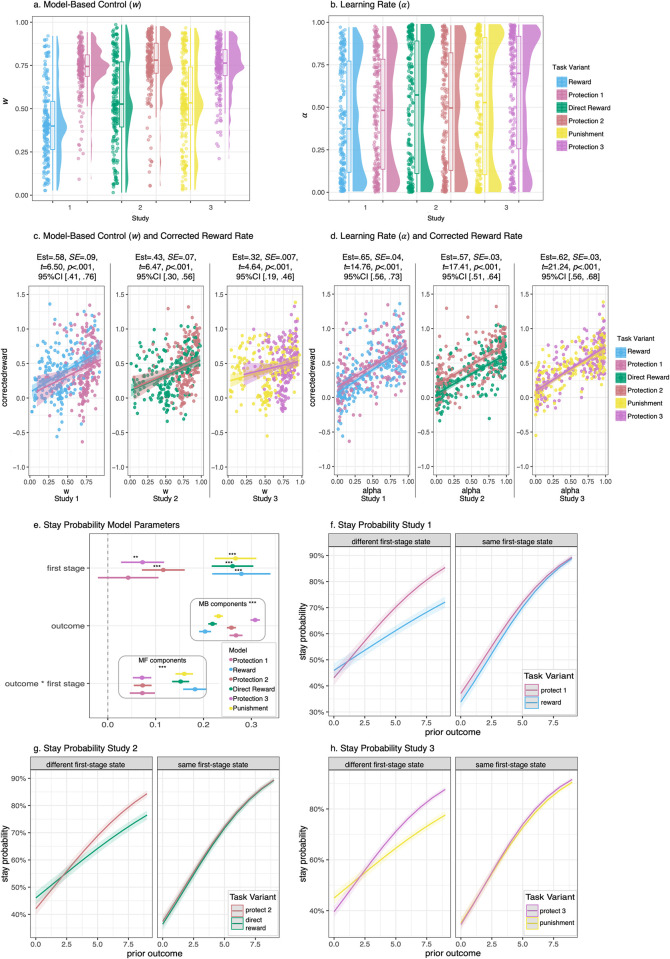
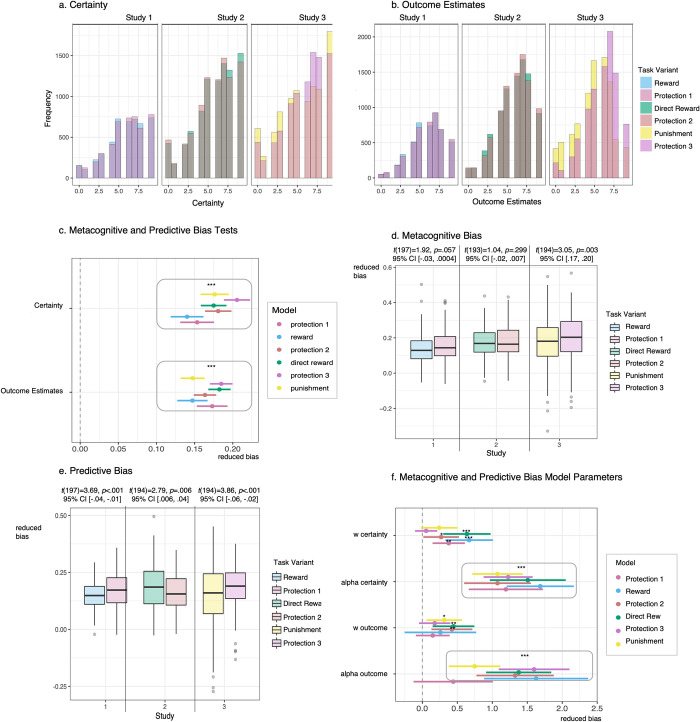
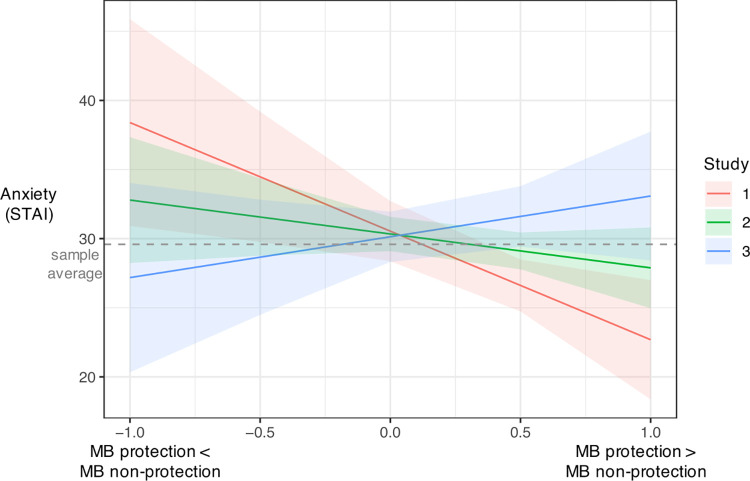
Protection often involves the capacity to prospectively plan the actions needed to mitigate harm. The computational architecture of decisions involving protection remains unclear, as well as whether these decisions differ from other beneficial prospective actions such as reward acquisition. Here we compare protection acquisition to reward acquisition and punishment avoidance to examine overlapping and distinct features across the three action types. Protection acquisition is positively valenced similar to reward. For both protection and reward, the more the actor gains, the more benefit. However, reward and protection occur in different contexts, with protection existing in aversive contexts. Punishment avoidance also occurs in aversive contexts, but differs from protection because punishment is negatively valenced and motivates avoidance. Across three independent studies (Total N = 600) we applied computational modeling to examine model-based reinforcement learning for protection, reward, and punishment in humans. Decisions motivated by acquiring protection evoked a higher degree of model-based control than acquiring reward or avoiding punishment, with no significant differences in learning rate. The context-valence asymmetry characteristic of protection increased deployment of flexible decision strategies, suggesting model-based control depends on the context in which outcomes are encountered as well as the valence of the outcome.
Copyright: © 2022 Tashjian et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
