

Proteomics separates adult-type diffuse high-grade gliomas in metabolic subgroups independent of 1p/19q codeletion and across IDH mutational status
- PMID: 36584682
- PMCID: PMC9873829
- DOI: 10.1016/j.xcrm.2022.100877
Proteomics separates adult-type diffuse high-grade gliomas in metabolic subgroups independent of 1p/19q codeletion and across IDH mutational status
Abstract
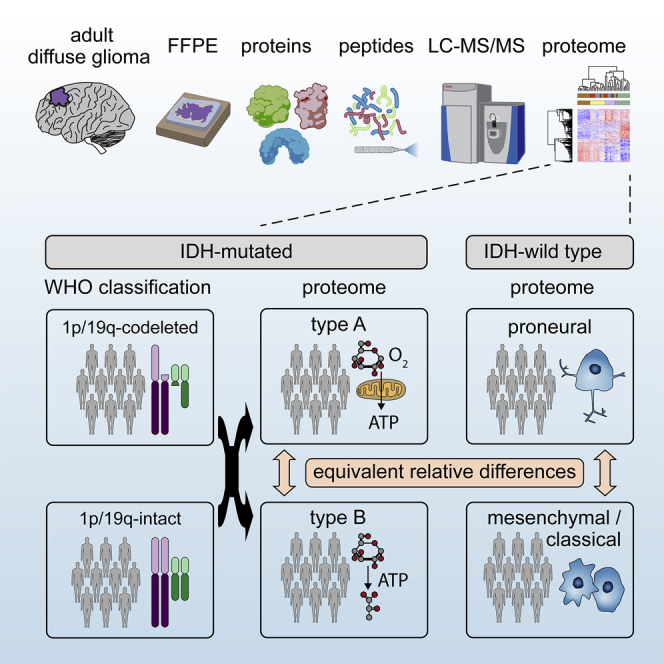
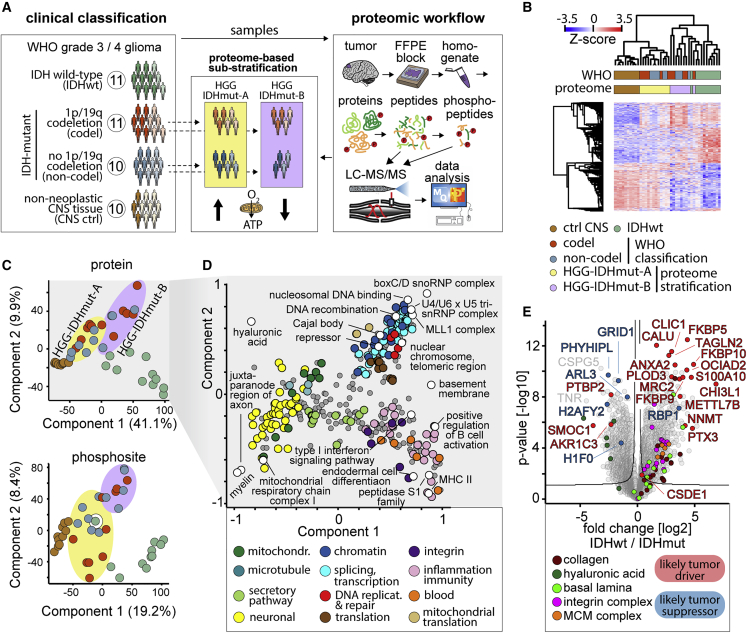
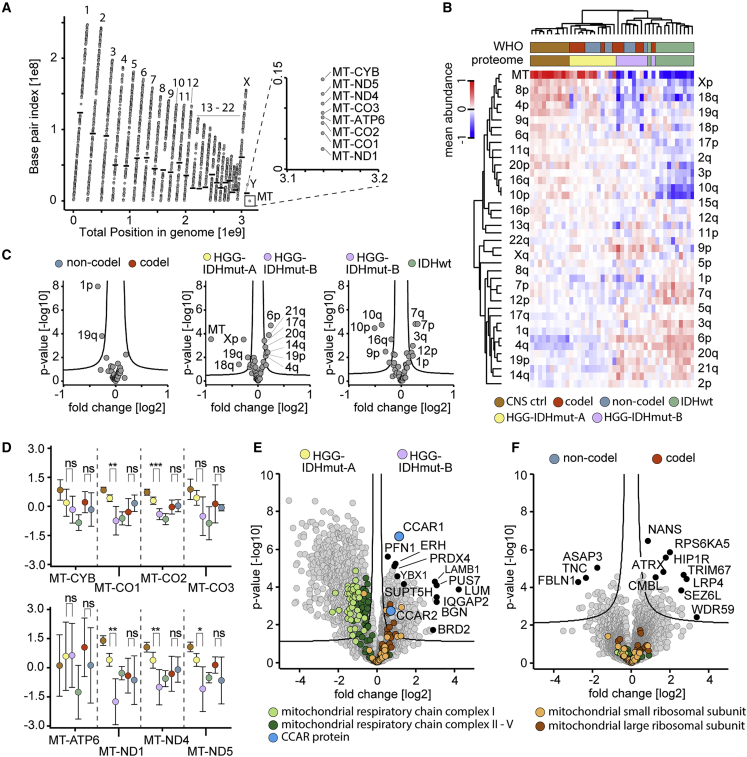
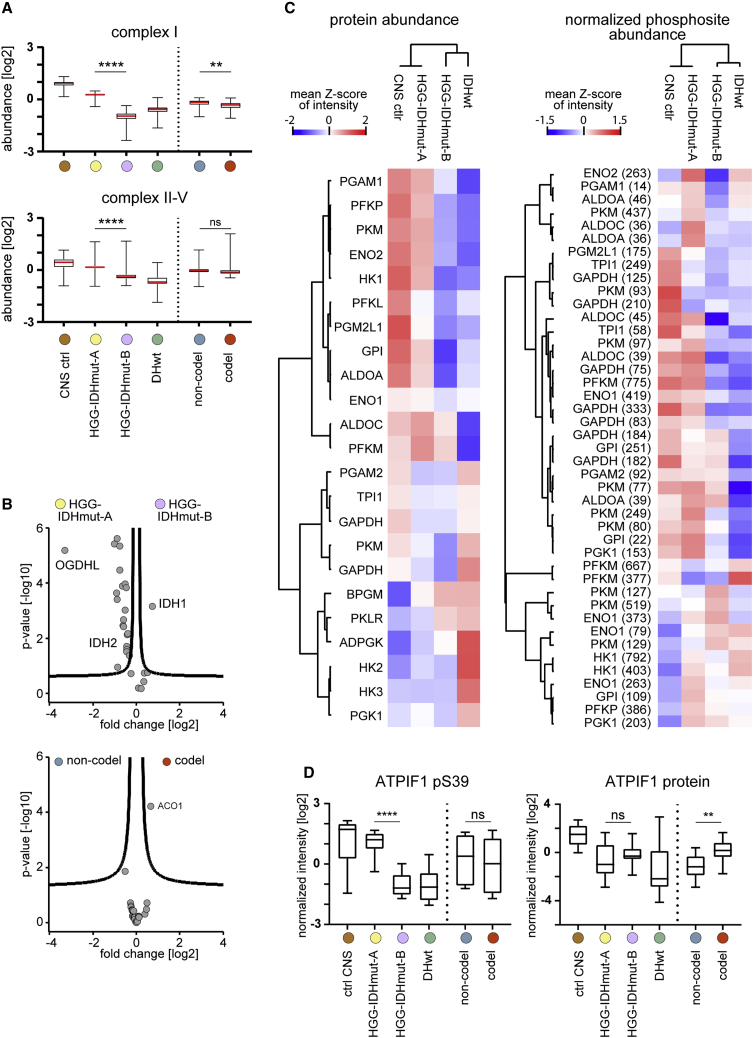
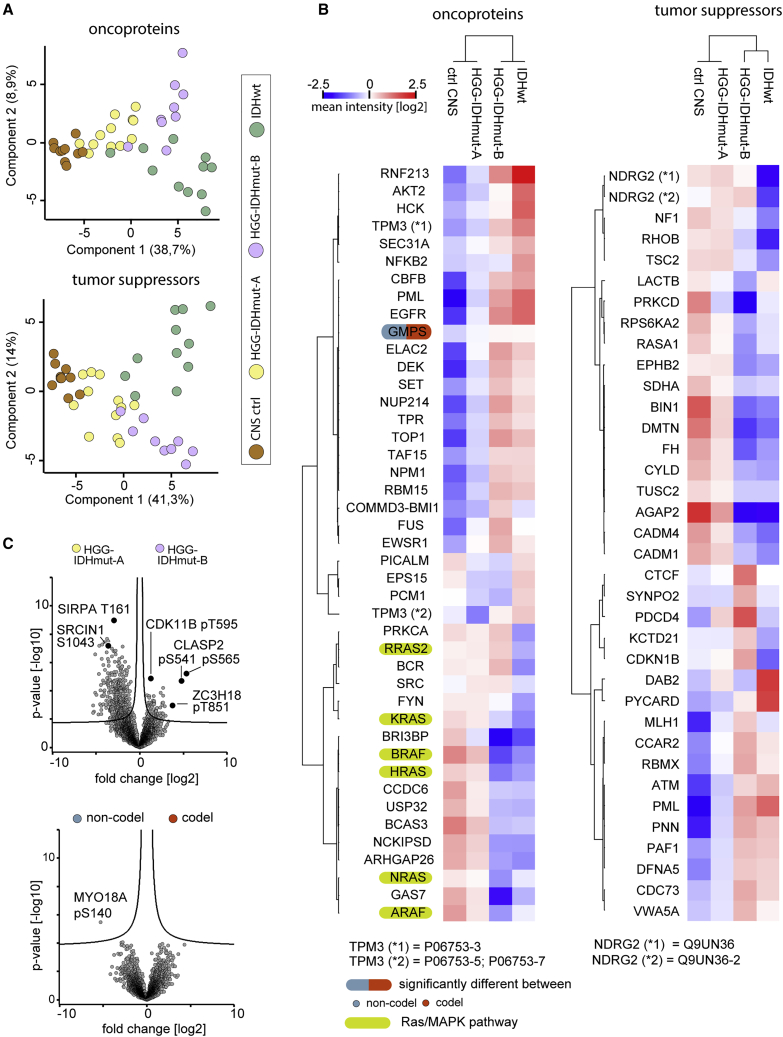
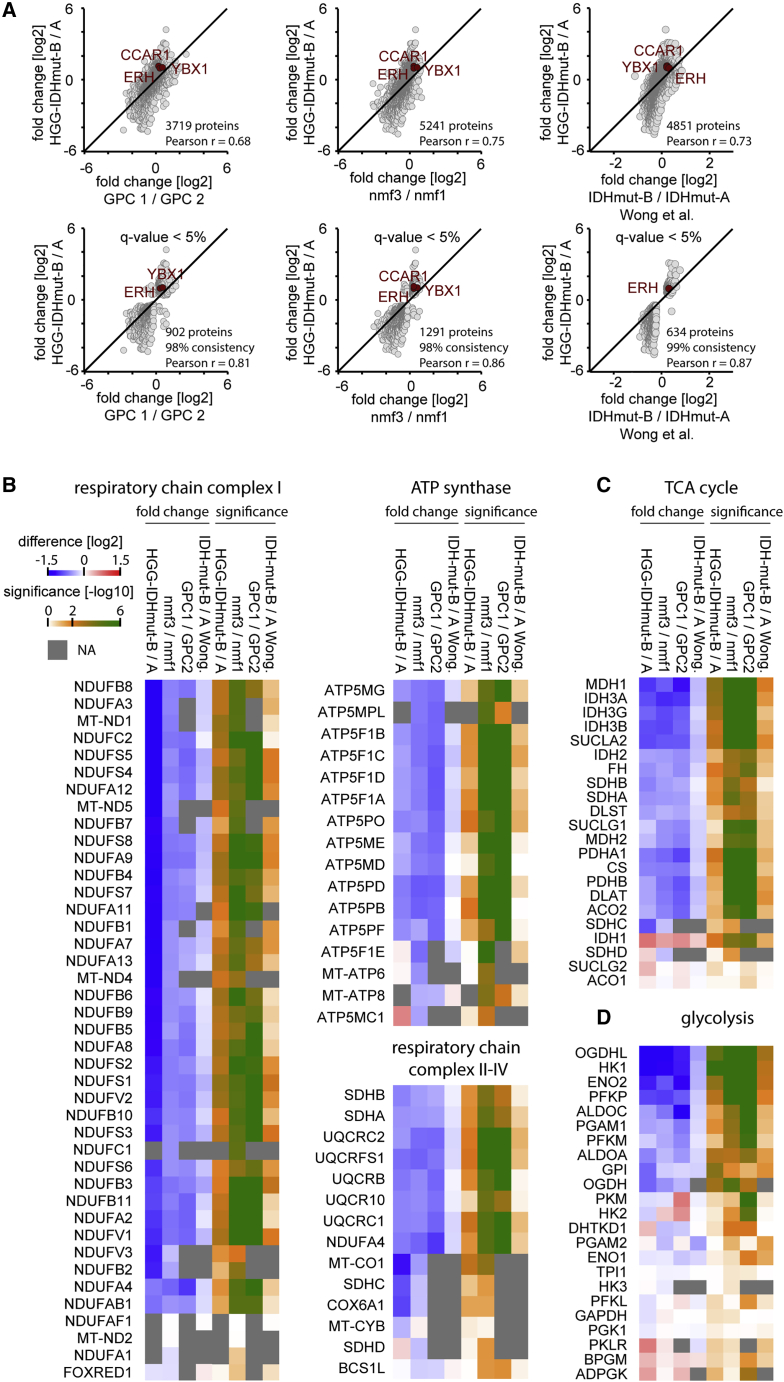
High-grade adult-type diffuse gliomas are malignant neuroepithelial tumors with poor survival rates in combined chemoradiotherapy. The current WHO classification is based on IDH1/2 mutational and 1p/19q codeletion status. Glioma proteome alterations remain undercharacterized despite their promise for a better molecular patient stratification and therapeutic target identification. Here, we use mass spectrometry to characterize 42 formalin-fixed, paraffin-embedded (FFPE) samples from IDH-wild-type (IDHwt) gliomas, IDH-mutant (IDHmut) gliomas with and without 1p/19q codeletion, and non-neoplastic controls. Based on more than 5,500 quantified proteins and 5,000 phosphosites, gliomas separate by IDH1/2 mutational status but not by 1p/19q status. Instead, IDHmut gliomas split into two proteomic subtypes with widespread perturbations, including aerobic/anaerobic energy metabolism. Validations with three independent glioma proteome datasets confirm these subgroups and link the IDHmut subtypes to the established proneural and classic/mesenchymal subtypes in IDHwt glioma. This demonstrates common phenotypic subtypes across the IDH status with potential therapeutic implications for patients with IDHmut gliomas.
Keywords: 1p/19q codeletion; IDH; glioblastoma; glioma; isocitrate dehydrogenase; proteomics.
Copyright © 2022 The Authors. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests The authors declare no competing interests.
Figures
Comment in
-
Proteome-based insights for IDH-mutant glioma classification.Cell Rep Med. 2023 Jan 17;4(1):100909. doi: 10.1016/j.xcrm.2022.100909. Cell Rep Med. 2023. PMID: 36652918 Free PMC article.
References
-
- WHO Classification of Tumours Editorial Board . 5th ed. International Agency for Research on Cancer; 2021. World Health Organization Classification of Tumours of the Central Nervous System.
-
- Stupp R., Hegi M.E., Mason W.P., van den Bent M.J., Taphoorn M.J.B., Janzer R.C., Ludwin S.K., Allgeier A., Fisher B., Belanger K., et al. Effects of radiotherapy with concomitant and adjuvant temozolomide versus radiotherapy alone on survival in glioblastoma in a randomised phase III study: 5-year analysis of the EORTC-NCIC trial. Lancet Oncol. 2009;10:459–466. doi: 10.1016/S1470-2045(09)70025-7. - DOI - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Medical
Molecular Biology Databases
Miscellaneous
