

Towards Single Camera Human 3D-Kinematics
- PMID: 36616937
- PMCID: PMC9823525
- DOI: 10.3390/s23010341
Towards Single Camera Human 3D-Kinematics
Abstract
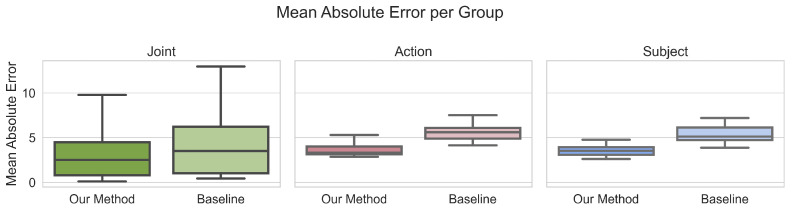
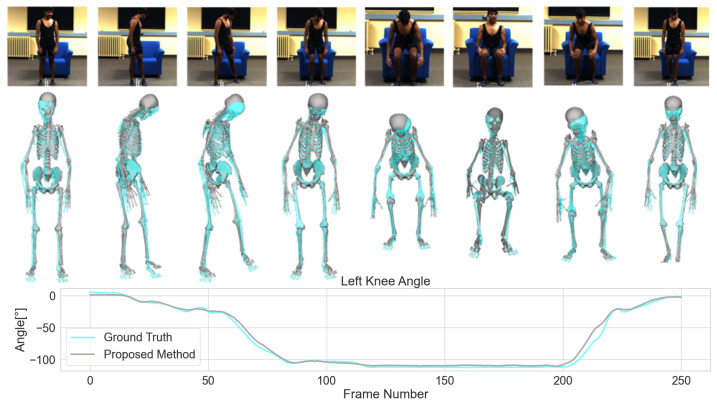
Markerless estimation of 3D Kinematics has the great potential to clinically diagnose and monitor movement disorders without referrals to expensive motion capture labs; however, current approaches are limited by performing multiple de-coupled steps to estimate the kinematics of a person from videos. Most current techniques work in a multi-step approach by first detecting the pose of the body and then fitting a musculoskeletal model to the data for accurate kinematic estimation. Errors in training data of the pose detection algorithms, model scaling, as well the requirement of multiple cameras limit the use of these techniques in a clinical setting. Our goal is to pave the way toward fast, easily applicable and accurate 3D kinematic estimation. To this end, we propose a novel approach for direct 3D human kinematic estimation D3KE from videos using deep neural networks. Our experiments demonstrate that the proposed end-to-end training is robust and outperforms 2D and 3D markerless motion capture based kinematic estimation pipelines in terms of joint angles error by a large margin (35% from 5.44 to 3.54 degrees). We show that D3KE is superior to the multi-step approach and can run at video framerate speeds. This technology shows the potential for clinical analysis from mobile devices in the future.
Keywords: 3D-kinematic estimation; 3D-kinematics; OpenSim; markerless motioncapture; musculoskeletal modelling; pose estimation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures




References
-
- Kanko R.M., Laende E.K., Strutzenberger G., Brown M., Selbie W.S., DePaul V., Scott S.H., Deluzio K.J. Assessment of spatiotemporal gait parameters using a deep learning algorithm-based markerless motion capture system. J. Biomech. 2021;122:110414. doi: 10.1016/j.jbiomech.2021.110414. - DOI - PubMed
-
- Gu X., Deligianni F., Lo B., Chen W., Yang G. Markerless gait analysis based on a single RGB camera; Proceedings of the 2018 IEEE 15th International Conference on Wearable and Implantable Body Sensor Networks (BSN); Las Vegas, NV, USA. 4–7 March 2018; pp. 42–45. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
