

Joint-Based Action Progress Prediction
- PMID: 36617115
- PMCID: PMC9824535
- DOI: 10.3390/s23010520
Joint-Based Action Progress Prediction
Abstract
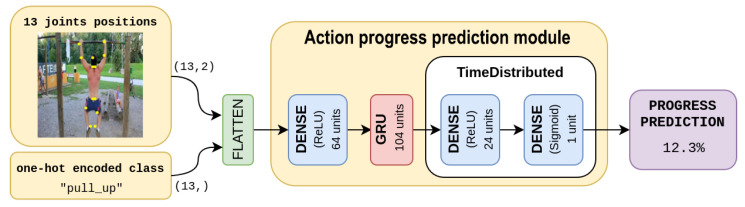
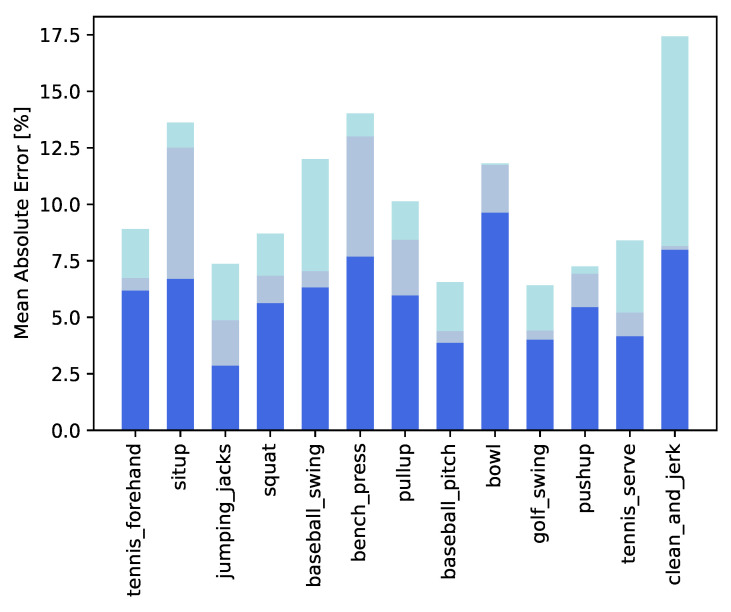
Action understanding is a fundamental computer vision branch for several applications, ranging from surveillance to robotics. Most works deal with localizing and recognizing the action in both time and space, without providing a characterization of its evolution. Recent works have addressed the prediction of action progress, which is an estimate of how far the action has advanced as it is performed. In this paper, we propose to predict action progress using a different modality compared to previous methods: body joints. Human body joints carry very precise information about human poses, which we believe are a much more lightweight and effective way of characterizing actions and therefore their execution. Estimating action progress can in fact be determined based on the understanding of how key poses follow each other during the development of an activity. We show how an action progress prediction model can exploit body joints and integrate it with modules providing keypoint and action information in order to be run directly from raw pixels. The proposed method is experimentally validated on the Penn Action Dataset.
Keywords: action progress prediction; body joints; body pose.
Conflict of interest statement
The authors declare no conflict of interest.
Figures






References
-
- Mabrouk A.B., Zagrouba E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Syst. Appl. 2018;91:480–491. doi: 10.1016/j.eswa.2017.09.029. - DOI
-
- Han Y., Zhang P., Zhuo T., Huang W., Zhang Y. Going deeper with two-stream ConvNets for action recognition in video surveillance. Pattern Recognit. Lett. 2018;107:83–90. doi: 10.1016/j.patrec.2017.08.015. - DOI
-
- Le Q.V., Zou W.Y., Yeung S.Y., Ng A.Y. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis; Proceedings of the CVPR 2011; Colorado Springs, CO, USA. 20–25 June 2011; pp. 3361–3368.
-
- Turchini F., Seidenari L., Del Bimbo A. Understanding and localizing activities from correspondences of clustered trajectories. Comput. Vis. Image Underst. 2017;159:128–142. doi: 10.1016/j.cviu.2016.11.007. - DOI
-
- Yuan H., Ni D., Wang M. Spatio-temporal dynamic inference network for group activity recognition; Proceedings of the IEEE/CVF International Conference on Computer Vision; Montreal, BC, Canada. 11–17 October 2021; pp. 7476–7485.
LinkOut - more resources
Full Text Sources
