

Predicting prime editing efficiency and product purity by deep learning
- PMID: 36646933
- PMCID: PMC7614945
- DOI: 10.1038/s41587-022-01613-7
Predicting prime editing efficiency and product purity by deep learning
Abstract
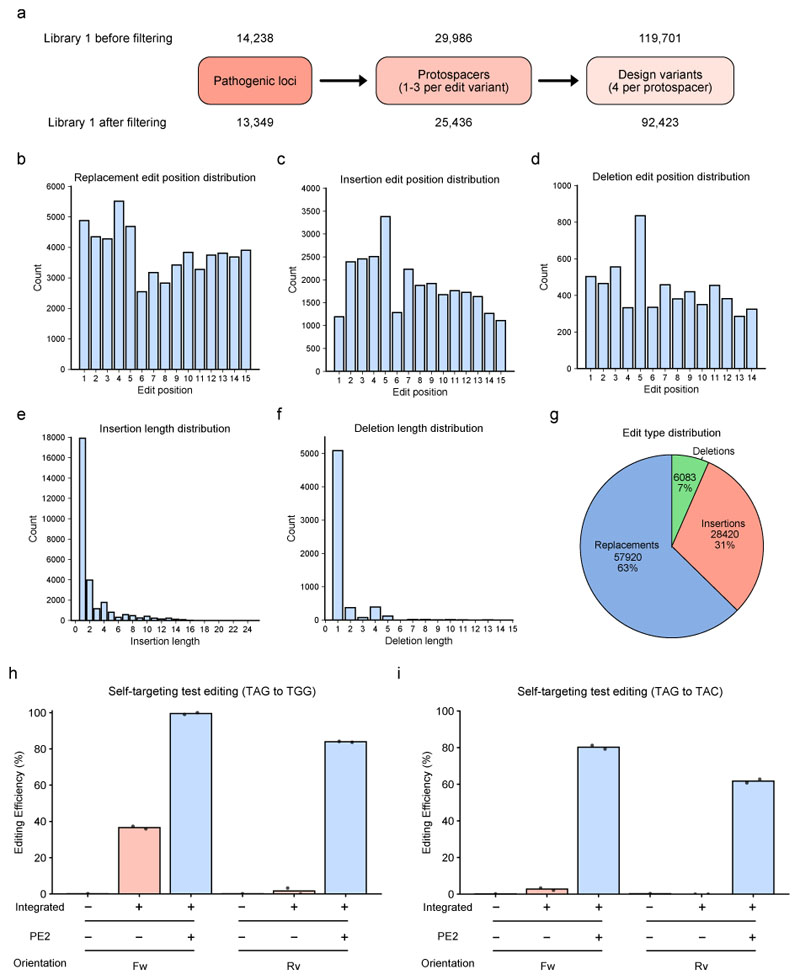
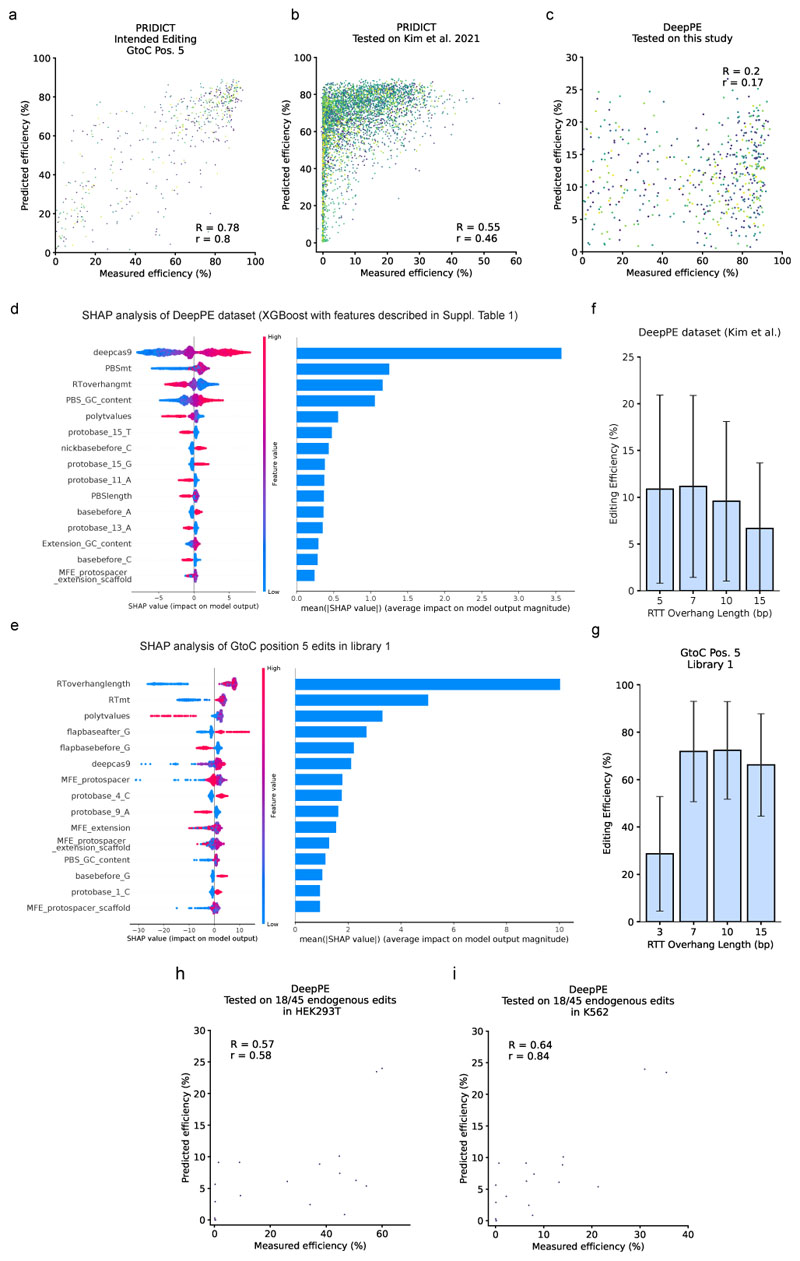
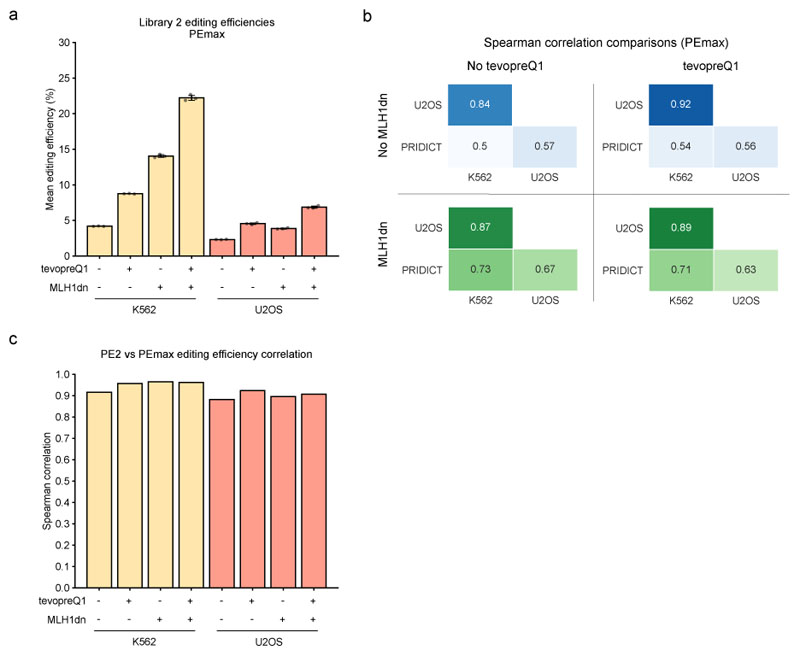
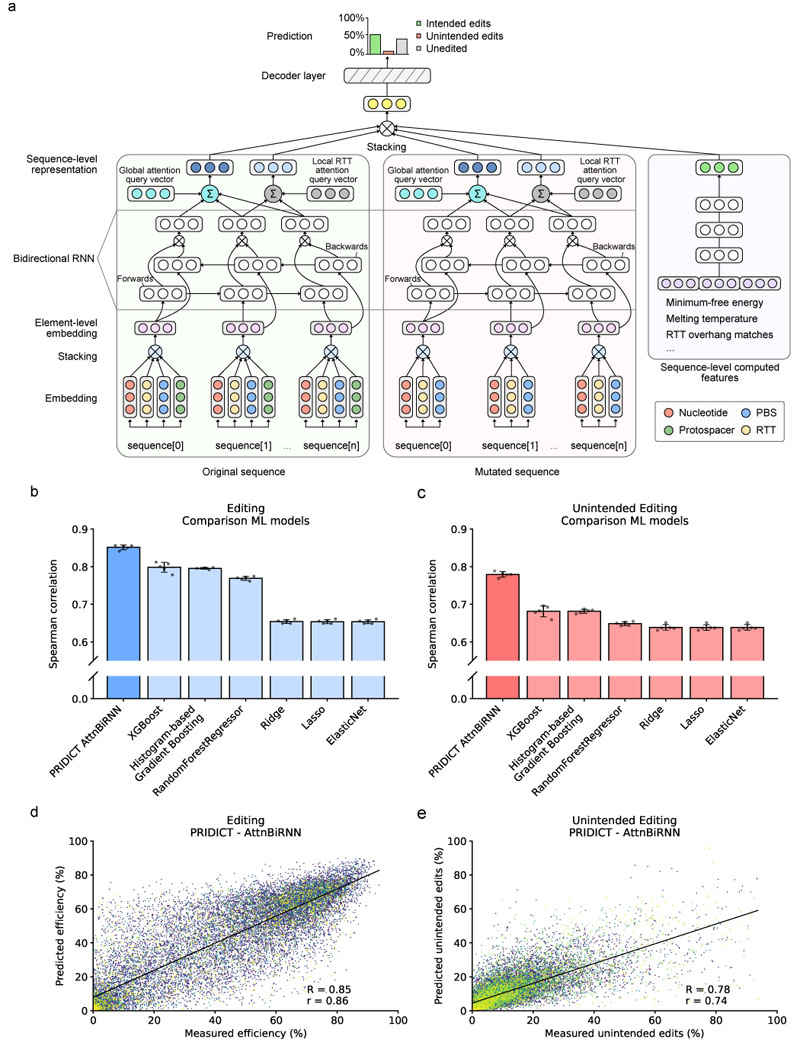
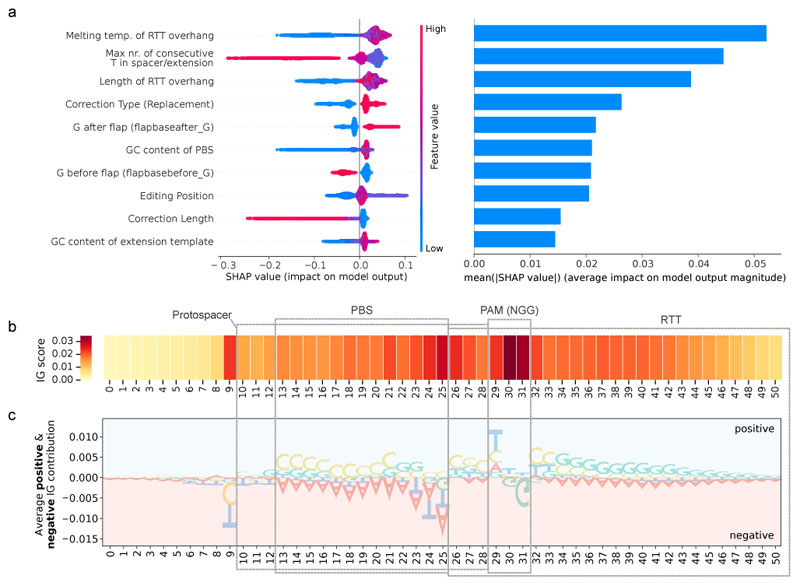
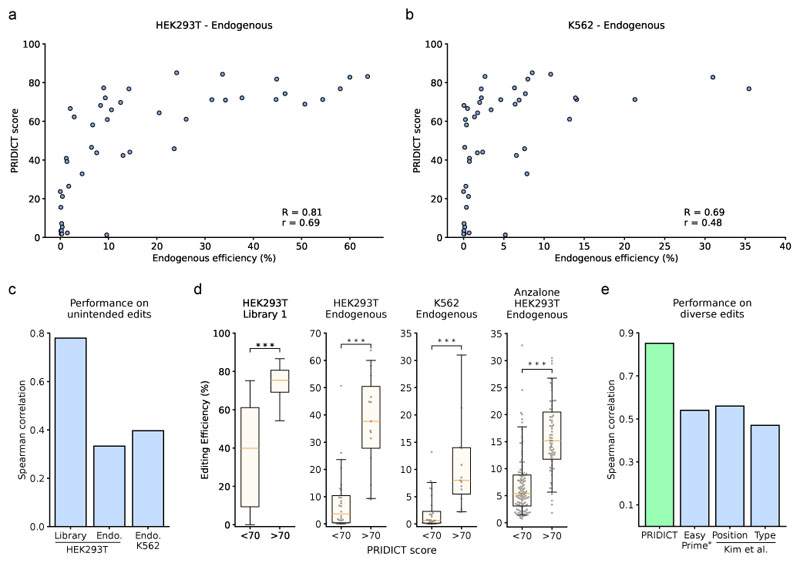
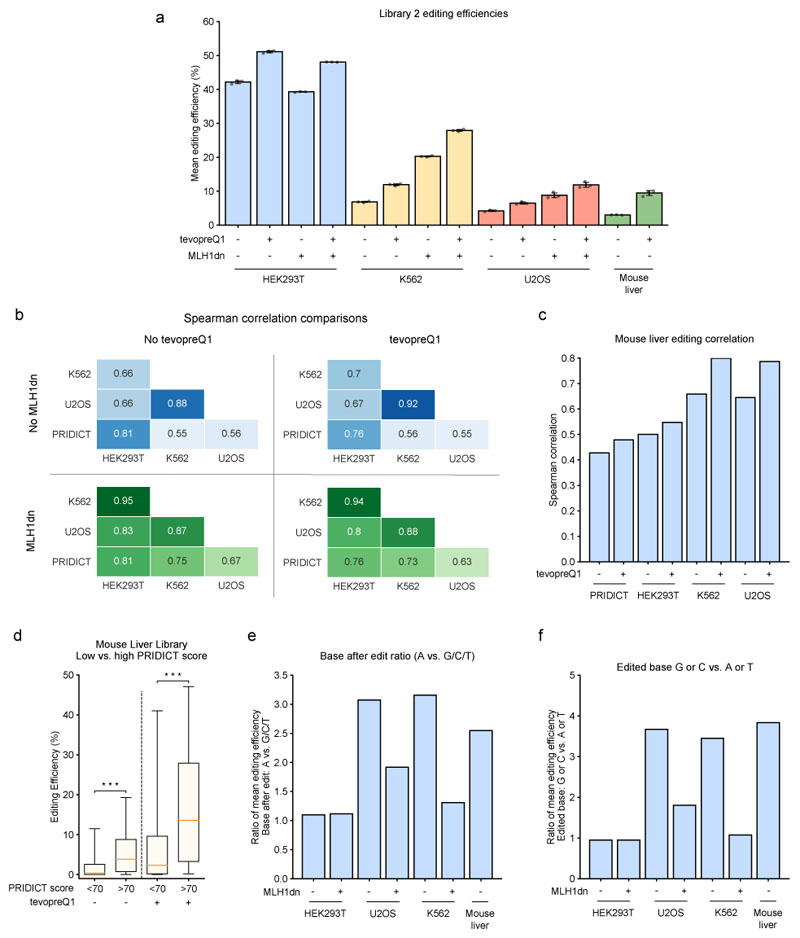
Prime editing is a versatile genome editing tool but requires experimental optimization of the prime editing guide RNA (pegRNA) to achieve high editing efficiency. Here we conducted a high-throughput screen to analyze prime editing outcomes of 92,423 pegRNAs on a highly diverse set of 13,349 human pathogenic mutations that include base substitutions, insertions and deletions. Based on this dataset, we identified sequence context features that influence prime editing and trained PRIDICT (prime editing guide prediction), an attention-based bidirectional recurrent neural network. PRIDICT reliably predicts editing rates for all small-sized genetic changes with a Spearman's R of 0.85 and 0.78 for intended and unintended edits, respectively. We validated PRIDICT on endogenous editing sites as well as an external dataset and showed that pegRNAs with high (>70) versus low (<70) PRIDICT scores showed substantially increased prime editing efficiencies in different cell types in vitro (12-fold) and in hepatocytes in vivo (tenfold), highlighting the value of PRIDICT for basic and for translational research applications.
© 2023. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Kim HK, et al. Predicting the efficiency of prime editing guide RNAs in human cells. Nat Biotechnol. 2021;39:198–206. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
