

Transformer-based deep learning for predicting protein properties in the life sciences
- PMID: 36651724
- PMCID: PMC9848389
- DOI: 10.7554/eLife.82819
Transformer-based deep learning for predicting protein properties in the life sciences
Abstract
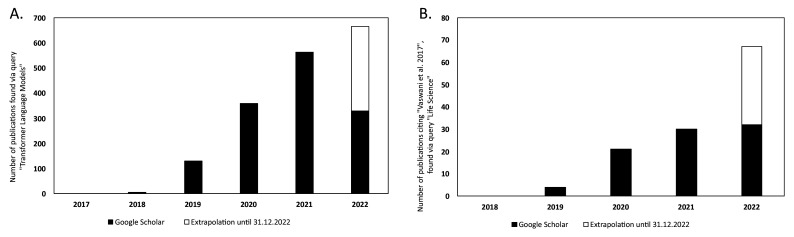
Recent developments in deep learning, coupled with an increasing number of sequenced proteins, have led to a breakthrough in life science applications, in particular in protein property prediction. There is hope that deep learning can close the gap between the number of sequenced proteins and proteins with known properties based on lab experiments. Language models from the field of natural language processing have gained popularity for protein property predictions and have led to a new computational revolution in biology, where old prediction results are being improved regularly. Such models can learn useful multipurpose representations of proteins from large open repositories of protein sequences and can be used, for instance, to predict protein properties. The field of natural language processing is growing quickly because of developments in a class of models based on a particular model-the Transformer model. We review recent developments and the use of large-scale Transformer models in applications for predicting protein characteristics and how such models can be used to predict, for example, post-translational modifications. We review shortcomings of other deep learning models and explain how the Transformer models have quickly proven to be a very promising way to unravel information hidden in the sequences of amino acids.
Keywords: computational biology; deep learning; life sciences; machine learning; protein property prediction; systems biology; transformers.
© 2023, Chandra et al.
Conflict of interest statement
AC, LT, TL, RG No competing interests declared
Figures






References
-
- Abdi H, Williams LJ. Principal component analysis. Wiley Interdisciplinary Reviews: Computational Statistics. 2010;2:433–459. doi: 10.1098/rsta.2015.0202. - DOI
-
- Albawi S, Mohammed TA, Al-Zawi S. Understanding of a convolutional neural network. 2017 International Conference on Engineering and Technology (ICET; 2017. - DOI
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
