

Spontaneous behaviour is structured by reinforcement without explicit reward
- PMID: 36653449
- PMCID: PMC9892006
- DOI: 10.1038/s41586-022-05611-2
Spontaneous behaviour is structured by reinforcement without explicit reward
Abstract
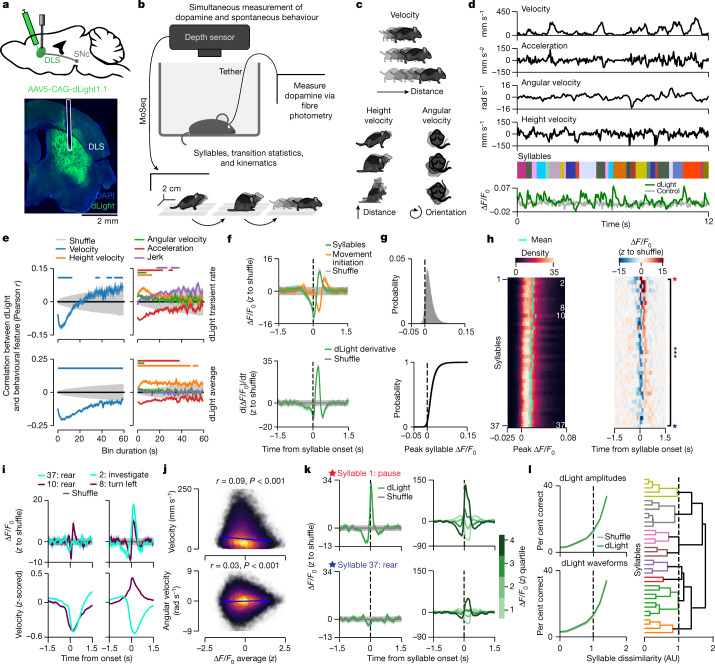
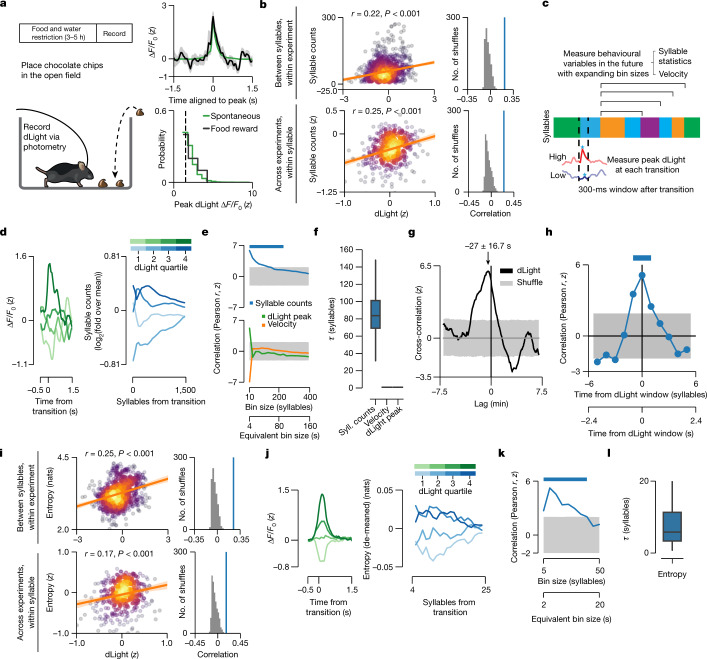
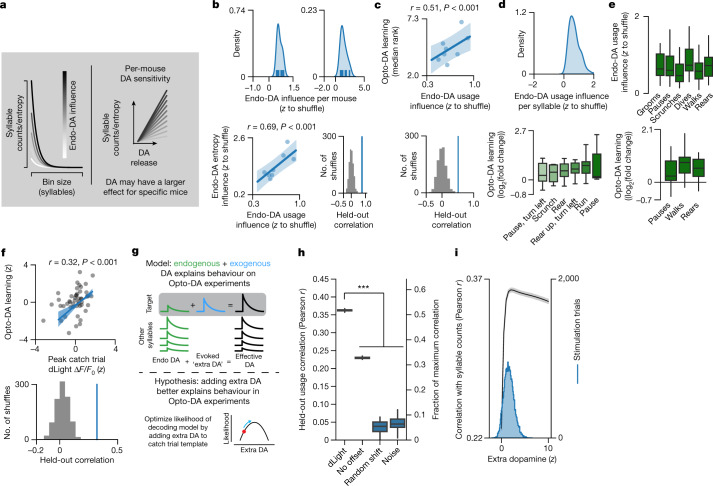
Spontaneous animal behaviour is built from action modules that are concatenated by the brain into sequences1,2. However, the neural mechanisms that guide the composition of naturalistic, self-motivated behaviour remain unknown. Here we show that dopamine systematically fluctuates in the dorsolateral striatum (DLS) as mice spontaneously express sub-second behavioural modules, despite the absence of task structure, sensory cues or exogenous reward. Photometric recordings and calibrated closed-loop optogenetic manipulations during open field behaviour demonstrate that DLS dopamine fluctuations increase sequence variation over seconds, reinforce the use of associated behavioural modules over minutes, and modulate the vigour with which modules are expressed, without directly influencing movement initiation or moment-to-moment kinematics. Although the reinforcing effects of optogenetic DLS dopamine manipulations vary across behavioural modules and individual mice, these differences are well predicted by observed variation in the relationships between endogenous dopamine and module use. Consistent with the possibility that DLS dopamine fluctuations act as a teaching signal, mice build sequences during exploration as if to maximize dopamine. Together, these findings suggest a model in which the same circuits and computations that govern action choices in structured tasks have a key role in sculpting the content of unconstrained, high-dimensional, spontaneous behaviour.
© 2023. The Author(s).
Conflict of interest statement
S.R.D. sits on the scientific advisory boards of Neumora and Gilgamesh Therapeutics, which have licensed or sub-licensed the MoSeq technology.
Figures












Comment in
-
Spontaneous behaviour is shaped by dopamine in two ways.Nature. 2023 Feb;614(7946):36-37. doi: 10.1038/d41586-023-00004-5. Nature. 2023. PMID: 36653602 No abstract available.
References
-
- Tinbergen, N. The Study of Instinct (Clarenden Press, 1951).
-
- Berridge KC, Fentress JC, Parr H. Natural syntax rules control action sequence of rats. Behav. Brain Res. 1987;23:59–68. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Research Materials
