

Future Pose Prediction from 3D Human Skeleton Sequence with Surrounding Situation
- PMID: 36679673
- PMCID: PMC9866287
- DOI: 10.3390/s23020876
Future Pose Prediction from 3D Human Skeleton Sequence with Surrounding Situation
Abstract
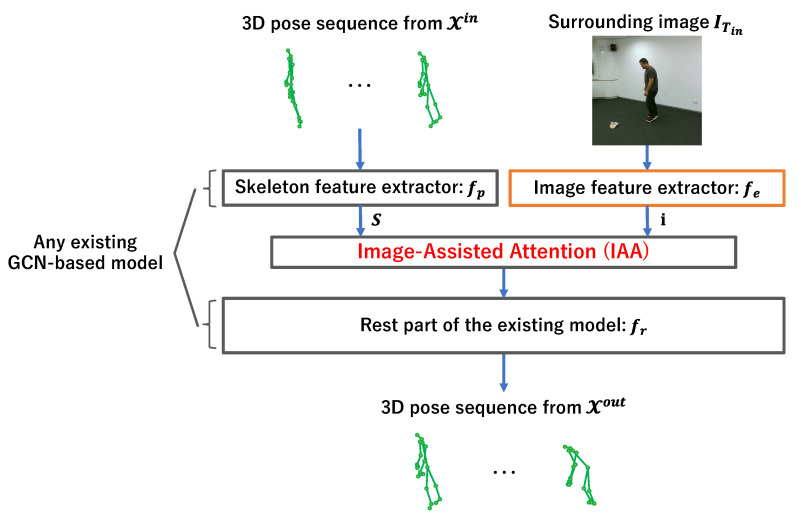
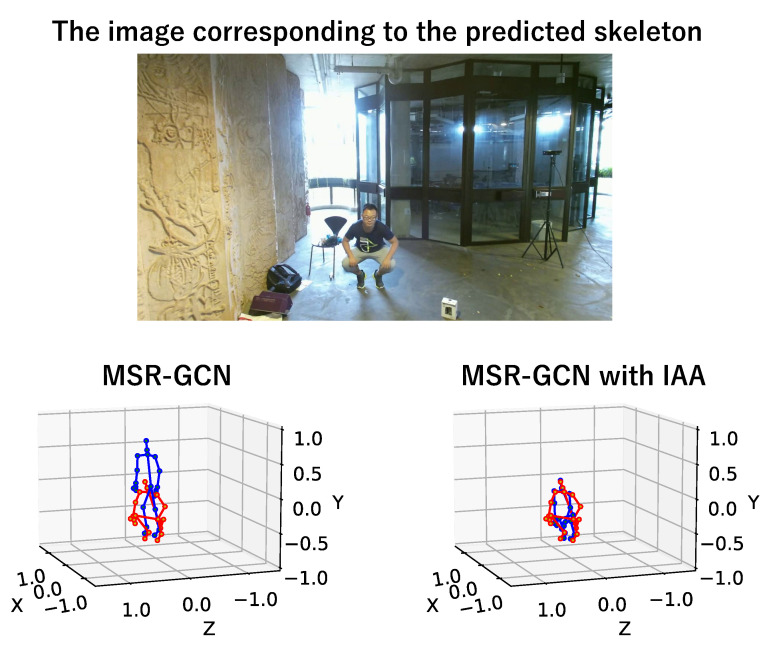
Human pose prediction is vital for robot applications such as human-robot interaction and autonomous control of robots. Recent prediction methods often use deep learning and are based on a 3D human skeleton sequence to predict future poses. Even if the starting motions of 3D human skeleton sequences are very similar, their future poses will have variety. It makes it difficult to predict future poses only from a given human skeleton sequence. Meanwhile, when carefully observing human motions, we can find that human motions are often affected by objects or other people around the target person. We consider that the presence of surrounding objects is an important clue for the prediction. This paper proposes a method for predicting the future skeleton sequence by incorporating the surrounding situation into the prediction model. The proposed method uses a feature of an image around the target person as the surrounding information. We confirmed the performance improvement of the proposed method through evaluations on publicly available datasets. As a result, the prediction accuracy was improved for object-related and human-related motions.
Keywords: 3D skeleton sequence; pose prediction; surrounding information.
Conflict of interest statement
The authors declare no conflict of interest.
Figures








References
-
- Foka A., Trahanias P. Probabilistic Autonomous Robot Navigation in Dynamic Environments with Human Motion Prediction. Int. J. Soc. Robot. 2010;2:79–94. doi: 10.1007/s12369-009-0037-z. - DOI
-
- Koppula H.S., Saxena A. Anticipating human activities for reactive robotic response; Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems; Tokyo, Japan. 3–7 November 2013; p. 2071. - DOI
-
- Gong H., Sim J., Likhachev M., Shi J. Multi-hypothesis motion planning for visual object tracking; Proceedings of the 2011 International Conference on Computer Vision; Barcelona, Spain. 6–13 November 2011; pp. 619–626. - DOI
-
- Liu H., Wang L. Human motion prediction for human-robot collaboration. J. Manuf. Syst. 2017;44:287–294. doi: 10.1016/j.jmsy.2017.04.009. - DOI
-
- Gui L.Y., Zhang K., Wang Y.X., Liang X., Moura J.M.F., Veloso M. Teaching Robots to Predict Human Motion; Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); Madrid, Spain. 1–5 October 2018; pp. 562–567. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
