

A universal deep-learning model for zinc finger design enables transcription factor reprogramming
- PMID: 36702896
- PMCID: PMC10421740
- DOI: 10.1038/s41587-022-01624-4
A universal deep-learning model for zinc finger design enables transcription factor reprogramming
Abstract
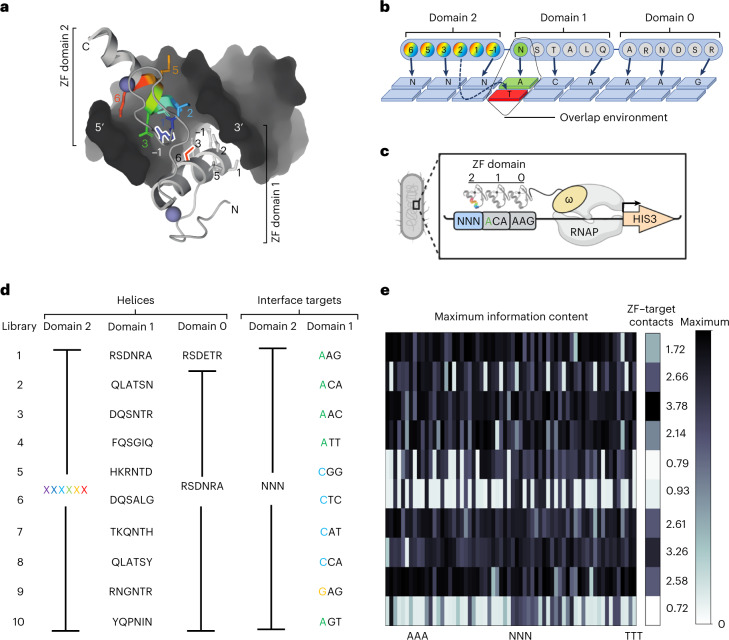
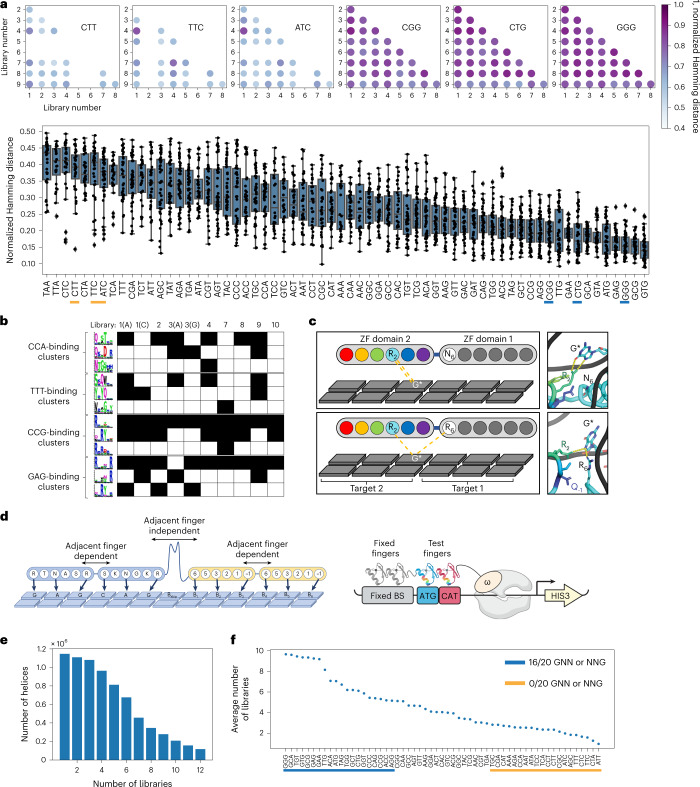
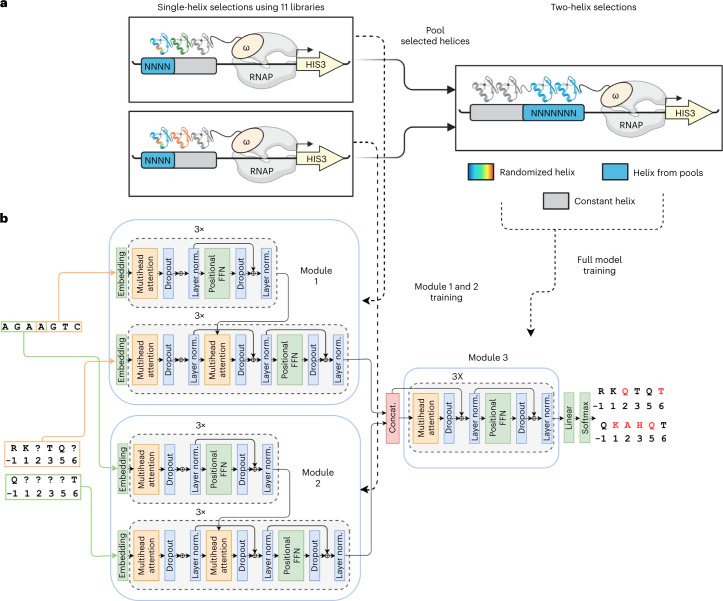
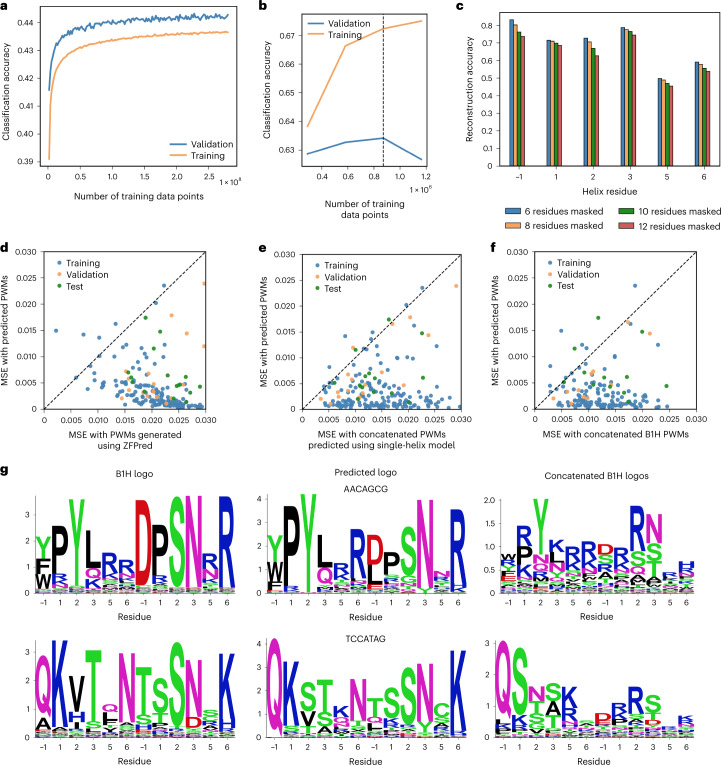
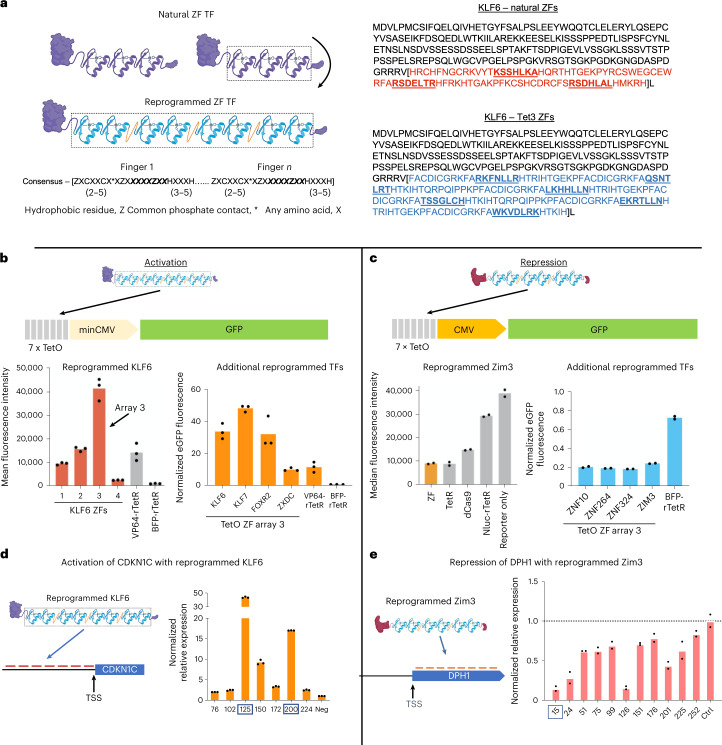
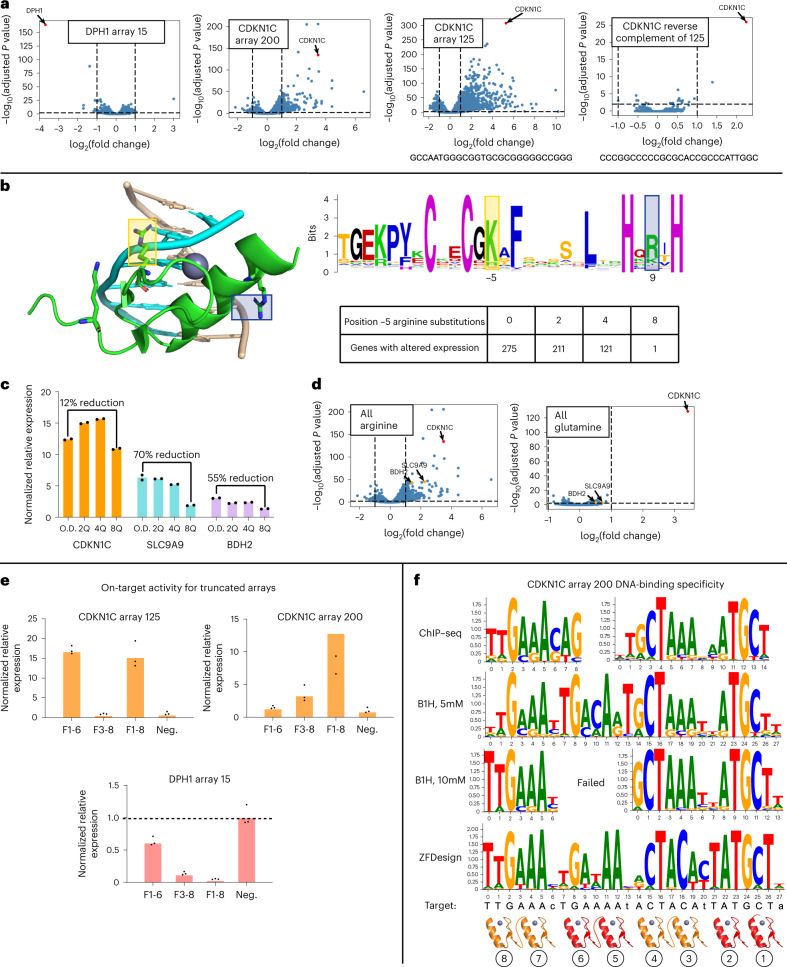
Cys2His2 zinc finger (ZF) domains engineered to bind specific target sequences in the genome provide an effective strategy for programmable regulation of gene expression, with many potential therapeutic applications. However, the structurally intricate engagement of ZF domains with DNA has made their design challenging. Here we describe the screening of 49 billion protein-DNA interactions and the development of a deep-learning model, ZFDesign, that solves ZF design for any genomic target. ZFDesign is a modern machine learning method that models global and target-specific differences induced by a range of library environments and specifically takes into account compatibility of neighboring fingers using a novel hierarchical transformer architecture. We demonstrate the versatility of designed ZFs as nucleases as well as activators and repressors by seamless reprogramming of human transcription factors. These factors could be used to upregulate an allele of haploinsufficiency, downregulate a gain-of-function mutation or test the consequence of regulation of a single gene as opposed to the many genes that a transcription factor would normally influence.
© 2023. The Author(s).
Conflict of interest statement
M.T., P.M.K. and M.B.N. are founders of TBG Therapeutics. Intellectual property has been filed on the method for generation of ZFs, the design model and the method to reprogram TFs. The remaining authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
