

A method for comparing multiple imputation techniques: A case study on the U.S. national COVID cohort collaborative
- PMID: 36716983
- PMCID: PMC10683778
- DOI: 10.1016/j.jbi.2023.104295
A method for comparing multiple imputation techniques: A case study on the U.S. national COVID cohort collaborative
Abstract
Healthcare datasets obtained from Electronic Health Records have proven to be extremely useful for assessing associations between patients' predictors and outcomes of interest. However, these datasets often suffer from missing values in a high proportion of cases, whose removal may introduce severe bias. Several multiple imputation algorithms have been proposed to attempt to recover the missing information under an assumed missingness mechanism. Each algorithm presents strengths and weaknesses, and there is currently no consensus on which multiple imputation algorithm works best in a given scenario. Furthermore, the selection of each algorithm's parameters and data-related modeling choices are also both crucial and challenging. In this paper we propose a novel framework to numerically evaluate strategies for handling missing data in the context of statistical analysis, with a particular focus on multiple imputation techniques. We demonstrate the feasibility of our approach on a large cohort of type-2 diabetes patients provided by the National COVID Cohort Collaborative (N3C) Enclave, where we explored the influence of various patient characteristics on outcomes related to COVID-19. Our analysis included classic multiple imputation techniques as well as simple complete-case Inverse Probability Weighted models. Extensive experiments show that our approach can effectively highlight the most promising and performant missing-data handling strategy for our case study. Moreover, our methodology allowed a better understanding of the behavior of the different models and of how it changed as we modified their parameters. Our method is general and can be applied to different research fields and on datasets containing heterogeneous types.
Keywords: COVID-19 severity assessment; Clinical informatics; Diabetic patients; Evaluation framework; Multiple Imputation.
Copyright © 2023. Published by Elsevier Inc.
Conflict of interest statement
Declaration of Competing Interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures
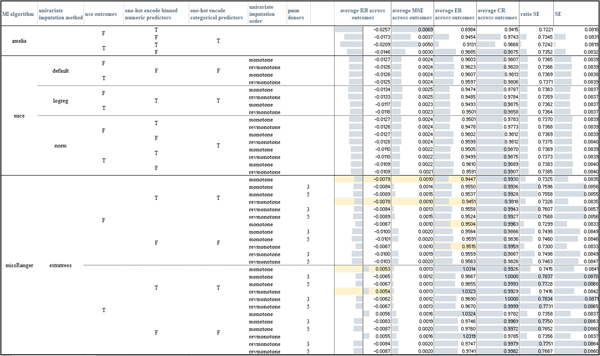
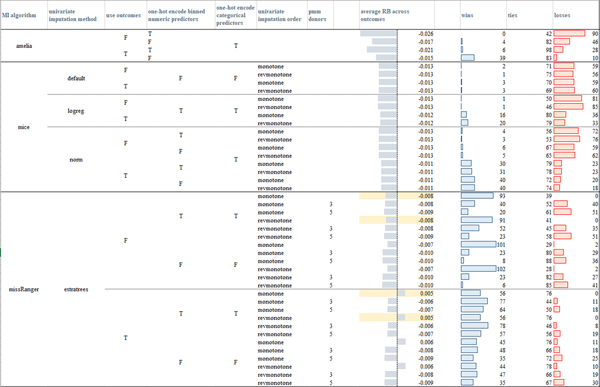
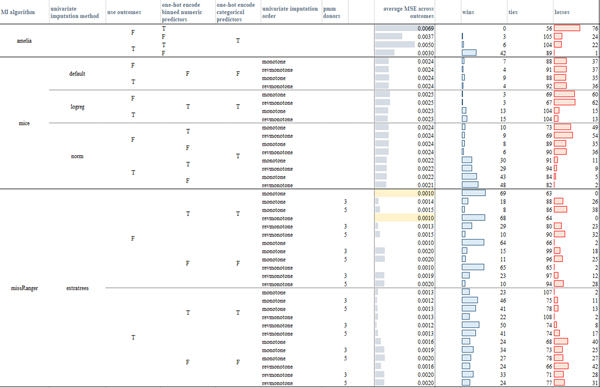
References
-
- Haneuse S, Arterburn D, & Daniels MJ (2021). Assessing missing data assumptions in EHR-based studies: a complex and underappreciated task. JAMA Network Open, 4(2), e210184-e210184. - PubMed
-
- Rubin DB (1987). Multiple Imputation for Nonresponse in Surveys. New York: John Wiley & Sons.
-
- Carlin JB (2014). Multiple Imputation: Perspective and Historical Overview. Chapter 12 of Handbook of Missing Data Methodology, Edited by Molenberghs G, Fitzmaurice GM, Kenward MG, Tsiatis A, Verbeke New York: Chapman & Hall/CRC. 10.1201/b17622 - DOI
Publication types
MeSH terms
Grants and funding
- UM1 TR004404/TR/NCATS NIH HHS/United States
- U54 GM104938/GM/NIGMS NIH HHS/United States
- UL1 TR002649/TR/NCATS NIH HHS/United States
- UL1 TR001422/TR/NCATS NIH HHS/United States
- UL1 TR001860/TR/NCATS NIH HHS/United States
- UL1 TR001427/TR/NCATS NIH HHS/United States
- U54 GM104942/GM/NIGMS NIH HHS/United States
- UL1 TR001420/TR/NCATS NIH HHS/United States
- UL1 TR001439/TR/NCATS NIH HHS/United States
- UL1 TR002243/TR/NCATS NIH HHS/United States
- BB/M025047/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- UL1 TR001445/TR/NCATS NIH HHS/United States
- UL1 TR003096/TR/NCATS NIH HHS/United States
- UL1 TR002537/TR/NCATS NIH HHS/United States
- UL1 TR001412/TR/NCATS NIH HHS/United States
- UL1 TR001872/TR/NCATS NIH HHS/United States
- UL1 TR001878/TR/NCATS NIH HHS/United States
- UL1 TR002529/TR/NCATS NIH HHS/United States
- UL1 TR001863/TR/NCATS NIH HHS/United States
- UL1 TR002494/TR/NCATS NIH HHS/United States
- UL1 TR002736/TR/NCATS NIH HHS/United States
- U54 GM115516/GM/NIGMS NIH HHS/United States
- UL1 TR002369/TR/NCATS NIH HHS/United States
- UL1 TR002541/TR/NCATS NIH HHS/United States
- U54 GM115371/GM/NIGMS NIH HHS/United States
- UL1 TR002001/TR/NCATS NIH HHS/United States
- UL1 TR002538/TR/NCATS NIH HHS/United States
- U54 GM115458/GM/NIGMS NIH HHS/United States
- UL1 TR001442/TR/NCATS NIH HHS/United States
- UL1 TR002535/TR/NCATS NIH HHS/United States
- UL1 TR001866/TR/NCATS NIH HHS/United States
- UL1 TR003167/TR/NCATS NIH HHS/United States
- UL1 TR001409/TR/NCATS NIH HHS/United States
- UL1 TR001449/TR/NCATS NIH HHS/United States
- UL1 TR001453/TR/NCATS NIH HHS/United States
- UL1 TR002489/TR/NCATS NIH HHS/United States
- U54 GM104940/GM/NIGMS NIH HHS/United States
- UL1 TR003107/TR/NCATS NIH HHS/United States
- MR/T001070/1/MRC_/Medical Research Council/United Kingdom
- UL1 TR003015/TR/NCATS NIH HHS/United States
- UL1 TR002733/TR/NCATS NIH HHS/United States
- UL1 TR001433/TR/NCATS NIH HHS/United States
- BB/F00964X/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- U24 TR002306/TR/NCATS NIH HHS/United States
- UL1 TR002003/TR/NCATS NIH HHS/United States
- UL1 TR001876/TR/NCATS NIH HHS/United States
- UL1 TR001436/TR/NCATS NIH HHS/United States
- UL1 TR002378/TR/NCATS NIH HHS/United States
- UL1 TR002384/TR/NCATS NIH HHS/United States
- UL1 TR002553/TR/NCATS NIH HHS/United States
- BB/K004131/1/BB_/Biotechnology and Biological Sciences Research Council/United Kingdom
- UL1 TR002389/TR/NCATS NIH HHS/United States
- UL1 TR001414/TR/NCATS NIH HHS/United States
- U54 GM104941/GM/NIGMS NIH HHS/United States
- UL1 TR002014/TR/NCATS NIH HHS/United States
- UL1 TR002550/TR/NCATS NIH HHS/United States
- UL1 TR002319/TR/NCATS NIH HHS/United States
- UL1 TR001855/TR/NCATS NIH HHS/United States
- UL1 TR001425/TR/NCATS NIH HHS/United States
- UL1 TR002373/TR/NCATS NIH HHS/United States
- UL1 TR002240/TR/NCATS NIH HHS/United States
- UL1 TR002556/TR/NCATS NIH HHS/United States
- UL1 TR003017/TR/NCATS NIH HHS/United States
- UL1 TR001998/TR/NCATS NIH HHS/United States
- UL1 TR001873/TR/NCATS NIH HHS/United States
- P30 DK124723/DK/NIDDK NIH HHS/United States
- UL1 TR001881/TR/NCATS NIH HHS/United States
- UL1 TR002645/TR/NCATS NIH HHS/United States
- UL1 TR001450/TR/NCATS NIH HHS/United States
- UL1 TR002366/TR/NCATS NIH HHS/United States
- U54 GM115428/GM/NIGMS NIH HHS/United States
- UL1 TR002345/TR/NCATS NIH HHS/United States
- UL1 TR002377/TR/NCATS NIH HHS/United States
- U54 GM115677/GM/NIGMS NIH HHS/United States
- UL1 TR002544/TR/NCATS NIH HHS/United States
- UL1 TR003098/TR/NCATS NIH HHS/United States
- UL1 TR001430/TR/NCATS NIH HHS/United States
- UL1 TR003142/TR/NCATS NIH HHS/United States
