

Distinct replay signatures for prospective decision-making and memory preservation
- PMID: 36719914
- PMCID: PMC9963918
- DOI: 10.1073/pnas.2205211120
Distinct replay signatures for prospective decision-making and memory preservation
Abstract
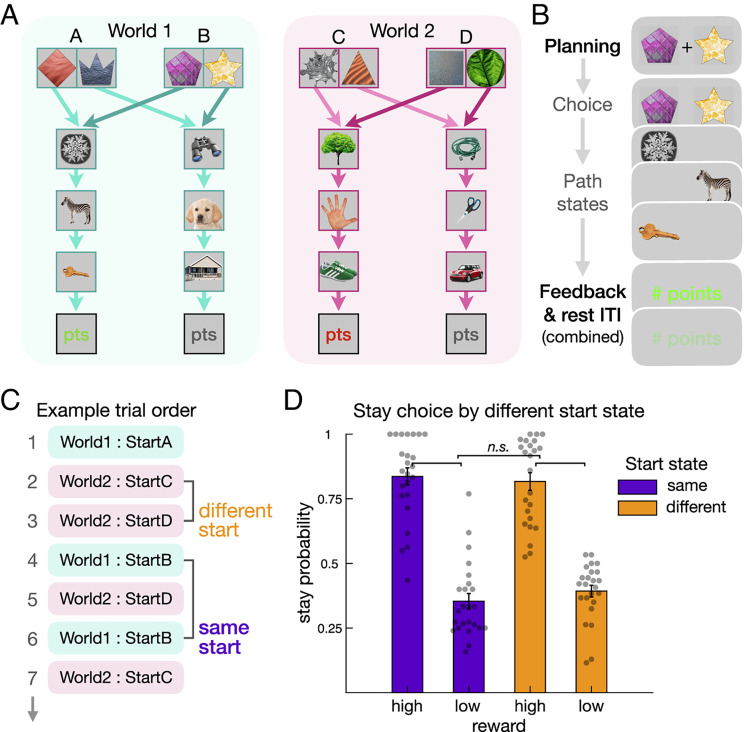
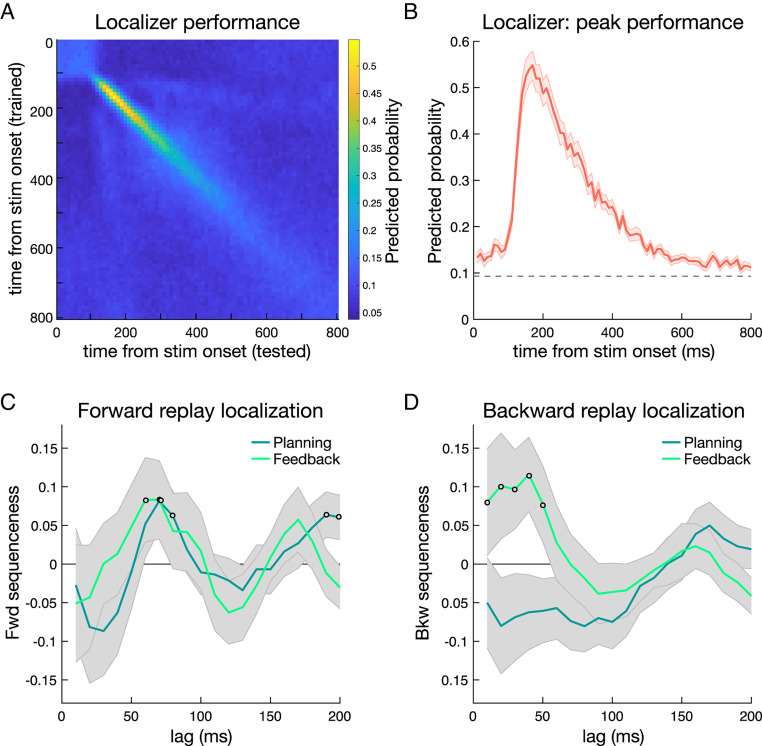
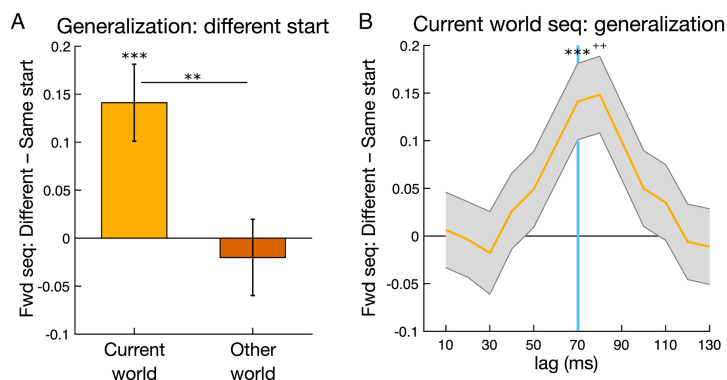
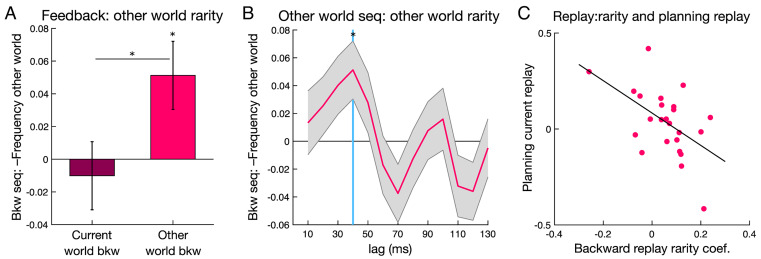
Theories of neural replay propose that it supports a range of functions, most prominently planning and memory consolidation. Here, we test the hypothesis that distinct signatures of replay in the same task are related to model-based decision-making ("planning") and memory preservation. We designed a reward learning task wherein participants utilized structure knowledge for model-based evaluation, while at the same time had to maintain knowledge of two independent and randomly alternating task environments. Using magnetoencephalography and multivariate analysis, we first identified temporally compressed sequential reactivation, or replay, both prior to choice and following reward feedback. Before choice, prospective replay strength was enhanced for the current task-relevant environment when a model-based planning strategy was beneficial. Following reward receipt, and consistent with a memory preservation role, replay for the alternative distal task environment was enhanced as a function of decreasing recency of experience with that environment. Critically, these planning and memory preservation relationships were selective to pre-choice and post-feedback periods, respectively. Our results provide support for key theoretical proposals regarding the functional role of replay and demonstrate that the relative strength of planning and memory-related signals are modulated by ongoing computational and task demands.
Keywords: decision-making; hippocampus; memory; planning; replay.
Conflict of interest statement
The authors declare no competing interest.
Figures
Similar articles
-
The roles of online and offline replay in planning.Elife. 2020 Jun 17;9:e56911. doi: 10.7554/eLife.56911. Elife. 2020. PMID: 32553110 Free PMC article.
-
Offline replay supports planning in human reinforcement learning.Elife. 2018 Dec 14;7:e32548. doi: 10.7554/eLife.32548. Elife. 2018. PMID: 30547886 Free PMC article.
-
Hippocampal Reactivation Extends for Several Hours Following Novel Experience.J Neurosci. 2019 Jan 30;39(5):866-875. doi: 10.1523/JNEUROSCI.1950-18.2018. Epub 2018 Dec 10. J Neurosci. 2019. PMID: 30530857 Free PMC article.
-
How our understanding of memory replay evolves.J Neurophysiol. 2023 Mar 1;129(3):552-580. doi: 10.1152/jn.00454.2022. Epub 2023 Feb 8. J Neurophysiol. 2023. PMID: 36752404 Free PMC article. Review.
-
The Role of Hippocampal Replay in Memory and Planning.Curr Biol. 2018 Jan 8;28(1):R37-R50. doi: 10.1016/j.cub.2017.10.073. Curr Biol. 2018. PMID: 29316421 Free PMC article. Review.
Cited by
-
Replay-triggered brain-wide activation in humans.Nat Commun. 2024 Aug 21;15(1):7185. doi: 10.1038/s41467-024-51582-5. Nat Commun. 2024. PMID: 39169063 Free PMC article.
-
Context changes retrieval of prospective outcomes during decision deliberation.Cereb Cortex. 2024 Dec 3;34(12):bhae483. doi: 10.1093/cercor/bhae483. Cereb Cortex. 2024. PMID: 39710609 Free PMC article.
-
Revisiting the role of computational neuroimaging in the era of integrative neuroscience.Neuropsychopharmacology. 2024 Nov;50(1):103-113. doi: 10.1038/s41386-024-01946-8. Epub 2024 Sep 6. Neuropsychopharmacology. 2024. PMID: 39242921 Free PMC article. Review.
-
The role of the human hippocampus in decision-making under uncertainty.Nat Hum Behav. 2024 Jul;8(7):1366-1382. doi: 10.1038/s41562-024-01855-2. Epub 2024 Apr 29. Nat Hum Behav. 2024. PMID: 38684870 Free PMC article.
-
Paradoxical replay can protect contextual task representations from destructive interference when experience is unbalanced.bioRxiv [Preprint]. 2024 May 9:2024.05.09.593332. doi: 10.1101/2024.05.09.593332. bioRxiv. 2024. PMID: 38766204 Free PMC article. Preprint.
References
-
- Foster D. J., Replay comes of age. Annu. Rev. Neurosci. 40, 581–602 (2017). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
