

Pallidal neuromodulation of the explore/exploit trade-off in decision-making
- PMID: 36727860
- PMCID: PMC9940911
- DOI: 10.7554/eLife.79642
Pallidal neuromodulation of the explore/exploit trade-off in decision-making
Abstract
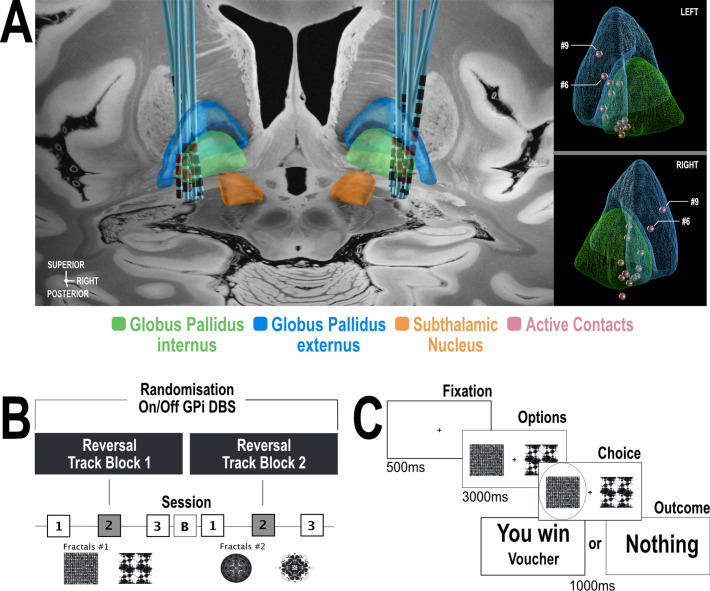
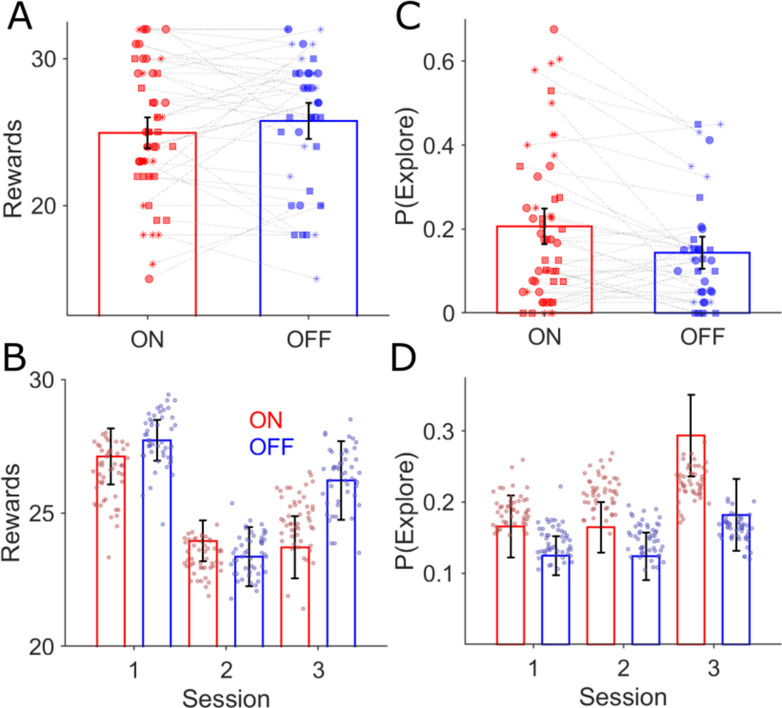
Every decision that we make involves a conflict between exploiting our current knowledge of an action's value or exploring alternative courses of action that might lead to a better, or worse outcome. The sub-cortical nuclei that make up the basal ganglia have been proposed as a neural circuit that may contribute to resolving this explore-exploit 'dilemma'. To test this hypothesis, we examined the effects of neuromodulating the basal ganglia's output nucleus, the globus pallidus interna, in patients who had undergone deep brain stimulation (DBS) for isolated dystonia. Neuromodulation enhanced the number of exploratory choices to the lower value option in a two-armed bandit probabilistic reversal-learning task. Enhanced exploration was explained by a reduction in the rate of evidence accumulation (drift rate) in a reinforcement learning drift diffusion model. We estimated the functional connectivity profile between the stimulating DBS electrode and the rest of the brain using a normative functional connectome derived from heathy controls. Variation in the extent of neuromodulation induced exploration between patients was associated with functional connectivity from the stimulation electrode site to a distributed brain functional network. We conclude that the basal ganglia's output nucleus, the globus pallidus interna, can adaptively modify decision choice when faced with the dilemma to explore or exploit.
Keywords: basal ganglia; deep brain stimulation; drift diffusion model; explore-exploit; globus pallidus interna; human; neuromodulation; neuroscience.
© 2023, de A Marcelino et al.
Conflict of interest statement
Ad, OG, BA, WG, JD, TG No competing interests declared, AK has received from honoraria from Boston Scientific, Medtronic and Teva
Figures











References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
