

A value-based deep reinforcement learning model with human expertise in optimal treatment of sepsis
- PMID: 36732666
- PMCID: PMC9894526
- DOI: 10.1038/s41746-023-00755-5
A value-based deep reinforcement learning model with human expertise in optimal treatment of sepsis
Abstract
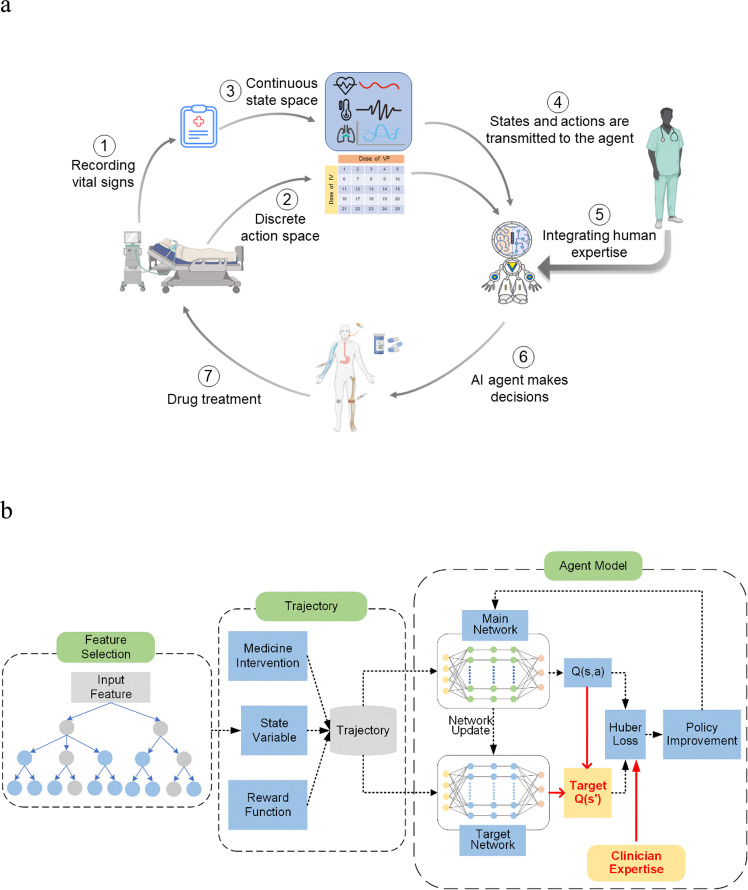
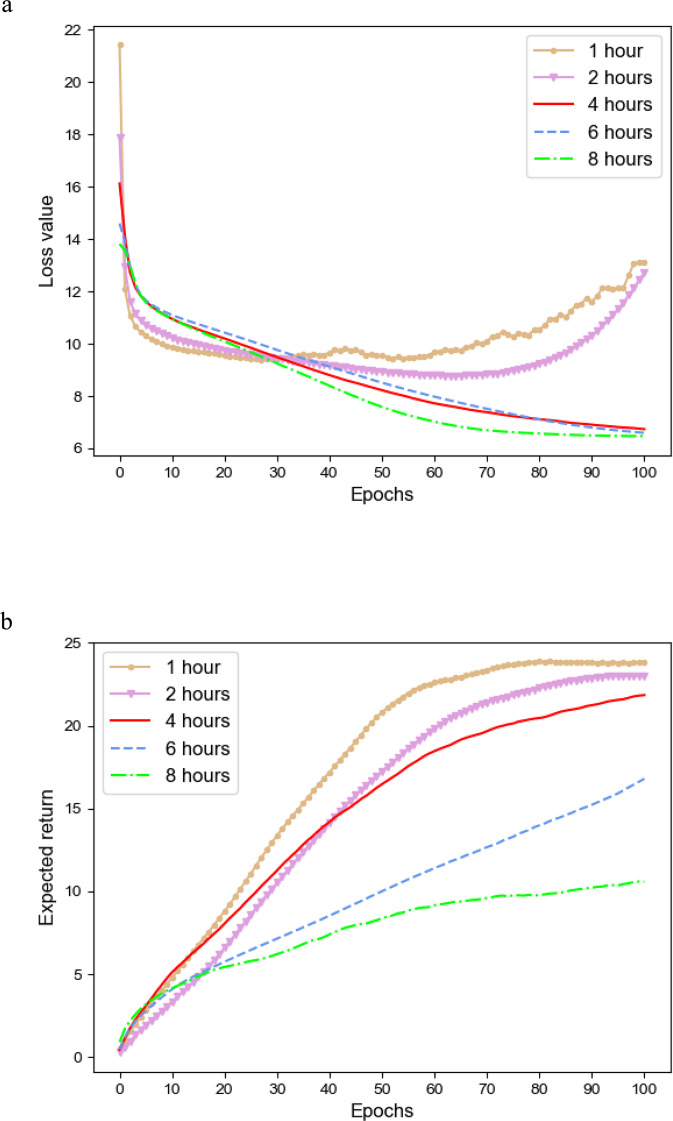
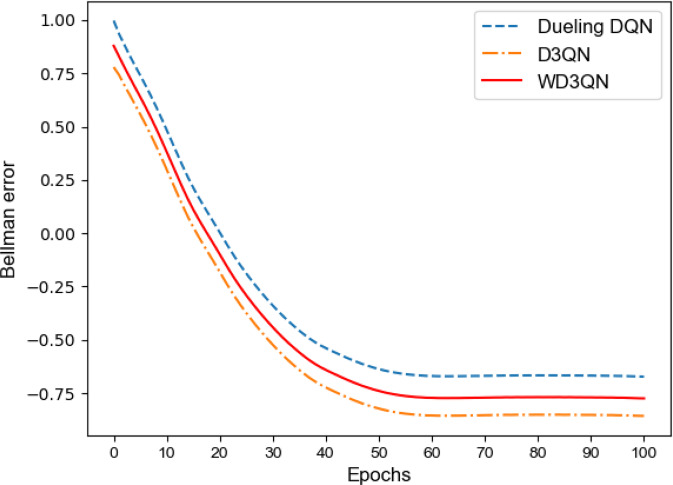
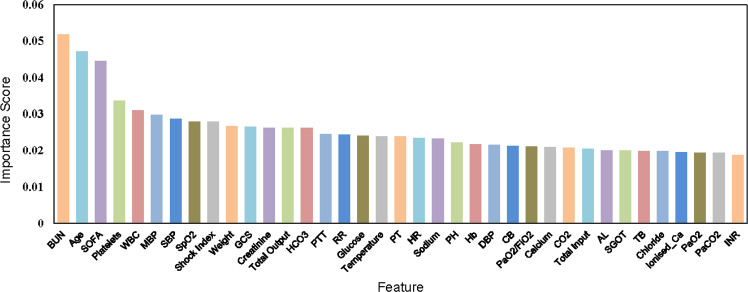
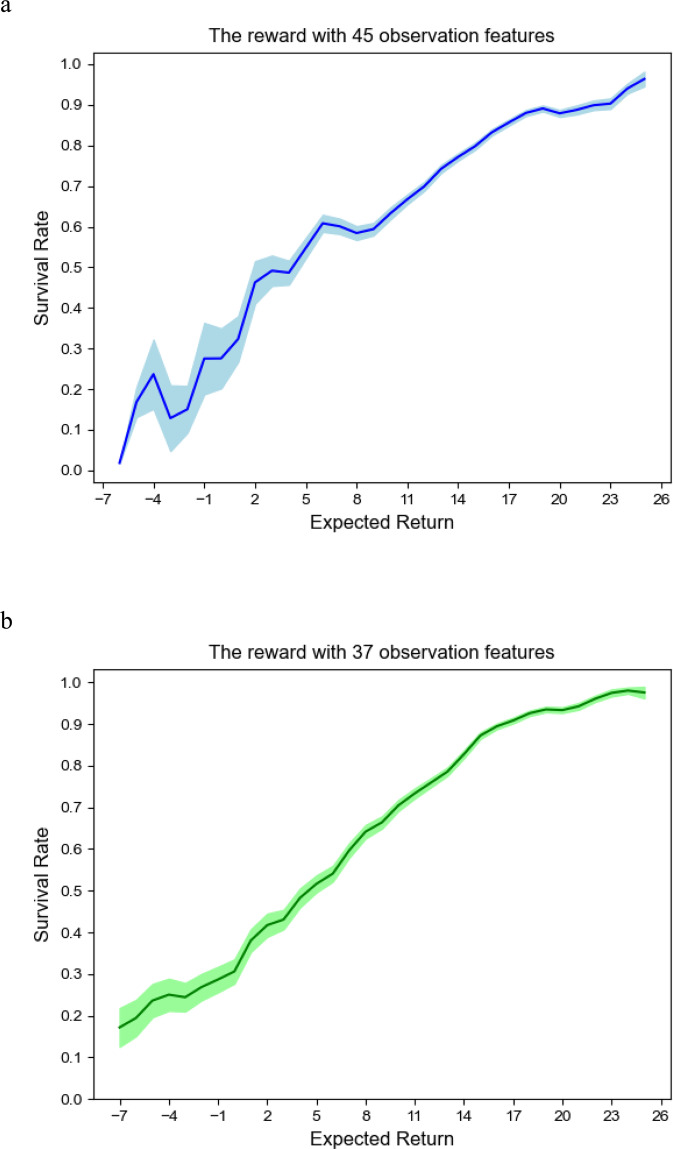
Deep Reinforcement Learning (DRL) has been increasingly attempted in assisting clinicians for real-time treatment of sepsis. While a value function quantifies the performance of policies in such decision-making processes, most value-based DRL algorithms cannot evaluate the target value function precisely and are not as safe as clinical experts. In this study, we propose a Weighted Dueling Double Deep Q-Network with embedded human Expertise (WD3QNE). A target Q value function with adaptive dynamic weight is designed to improve the estimate accuracy and human expertise in decision-making is leveraged. In addition, the random forest algorithm is employed for feature selection to improve model interpretability. We test our algorithm against state-of-the-art value function methods in terms of expected return, survival rate, action distribution and external validation. The results demonstrate that WD3QNE obtains the highest survival rate of 97.81% in MIMIC-III dataset. Our proposed method is capable of providing reliable treatment decisions with embedded clinician expertise.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures


References
-
- Kallfelz, M. et al. MIMIC-IV demo data in the OMOP Common Data Model (version 0.9). PhysioNet. 10.13026/p1f5-7x35 (2021).
LinkOut - more resources
Full Text Sources
Other Literature Sources
