

Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives
- PMID: 36738650
- PMCID: PMC10010286
- DOI: 10.1016/j.media.2023.102762
Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives
Abstract
Transformer, one of the latest technological advances of deep learning, has gained prevalence in natural language processing or computer vision. Since medical imaging bear some resemblance to computer vision, it is natural to inquire about the status quo of Transformers in medical imaging and ask the question: can the Transformer models transform medical imaging? In this paper, we attempt to make a response to the inquiry. After a brief introduction of the fundamentals of Transformers, especially in comparison with convolutional neural networks (CNNs), and highlighting key defining properties that characterize the Transformers, we offer a comprehensive review of the state-of-the-art Transformer-based approaches for medical imaging and exhibit current research progresses made in the areas of medical image segmentation, recognition, detection, registration, reconstruction, enhancement, etc. In particular, what distinguishes our review lies in its organization based on the Transformer's key defining properties, which are mostly derived from comparing the Transformer and CNN, and its type of architecture, which specifies the manner in which the Transformer and CNN are combined, all helping the readers to best understand the rationale behind the reviewed approaches. We conclude with discussions of future perspectives.
Keywords: Medical imaging; Survey; Transformer.
Copyright © 2023 Elsevier B.V. All rights reserved.
Conflict of interest statement
Declaration of Competing Interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures
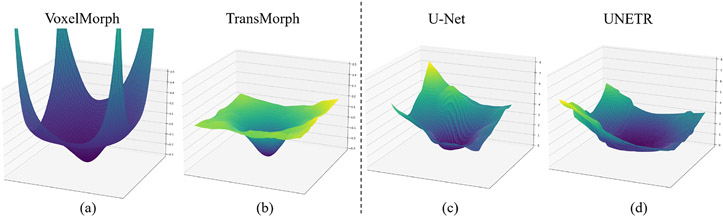
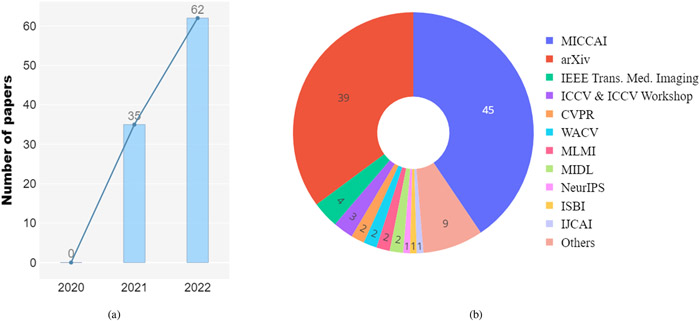
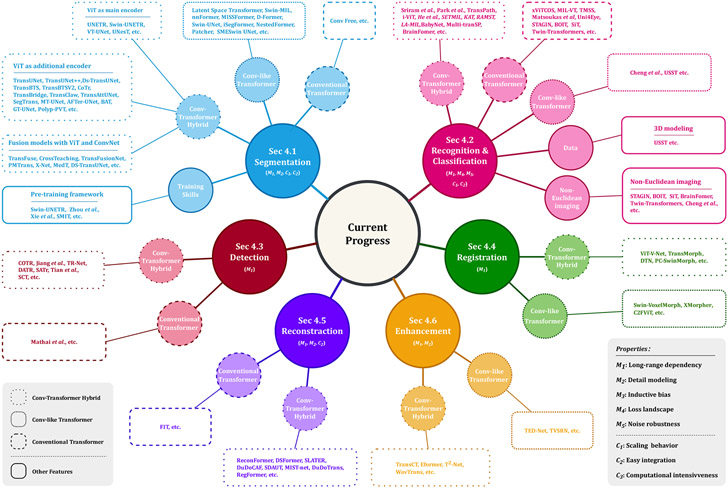
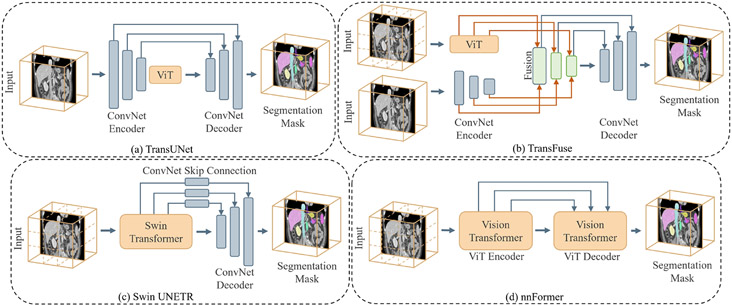
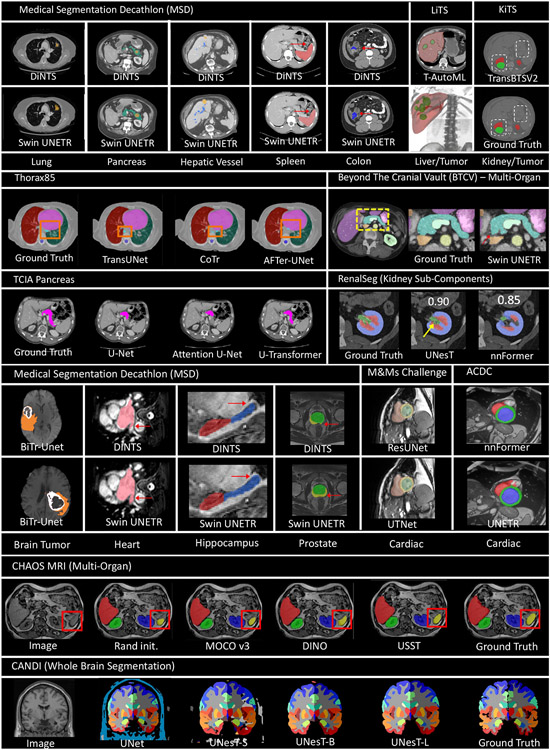
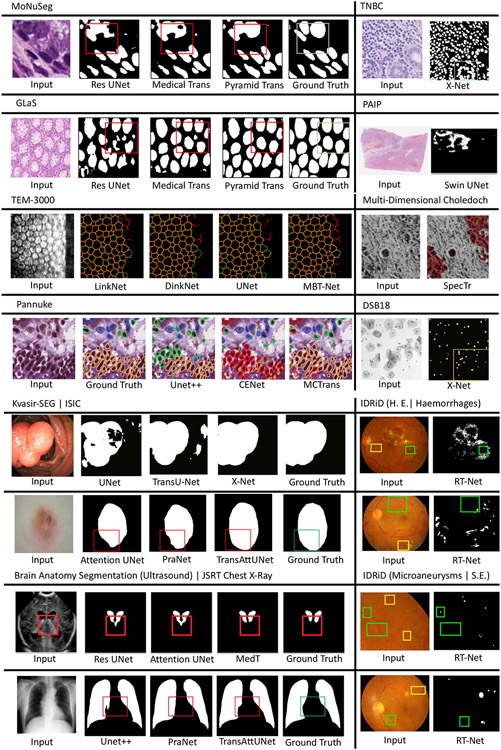
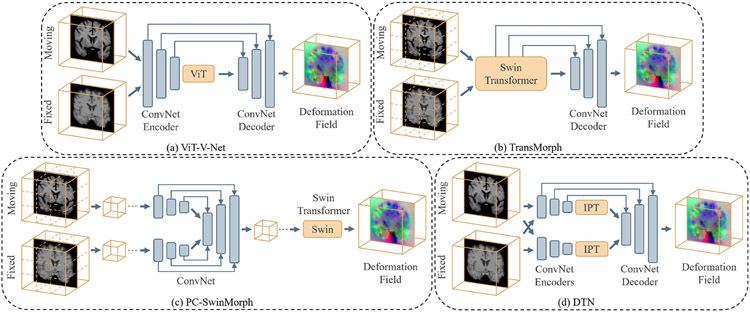
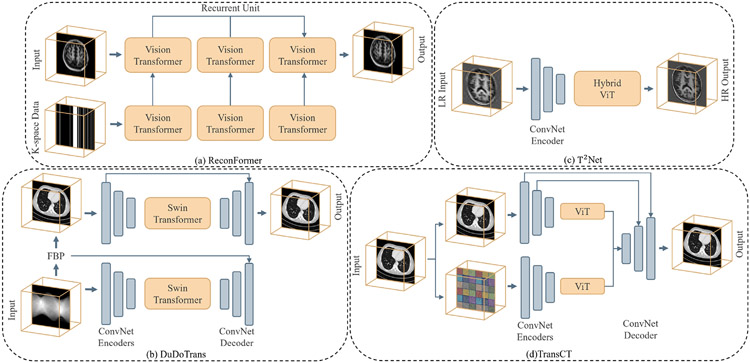
References
-
- Akhloufi MA, Chetoui M, 2021. Chest XR COVID-19 detection. https://cxr-covid19.grand-challenge.org/. Online; accessed September 2021.
-
- Alom MZ, Hasan M, Yakopcic C, Taha TM, Asari VK, 2018. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv preprint arXiv:1802.06955 .
-
- Ambellan F, Tack A, Ehlke M, Zachow S, 2019. Automated segmentation of knee bone and cartilage combining statistical shape knowledge and convolutional neural networks: Data from the osteoarthritis initiative. Medical image analysis 52, 109–118. - PubMed
-
- Anandarajah S, Tai T, de Lusignan S, Stevens P, O’Donoghue D, Walker M, Hilton S, 2005. The validity of searching routinely collected general practice computer data to identify patients with chronic kidney disease (ckd): a manual review of 500 medical records. Nephrology Dialysis Transplantation 20, 2089–2096. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
