

Towards an automated data cleaning with deep learning in CRESST
- PMID: 36741916
- PMCID: PMC9886615
- DOI: 10.1140/epjp/s13360-023-03674-2
Towards an automated data cleaning with deep learning in CRESST
Abstract
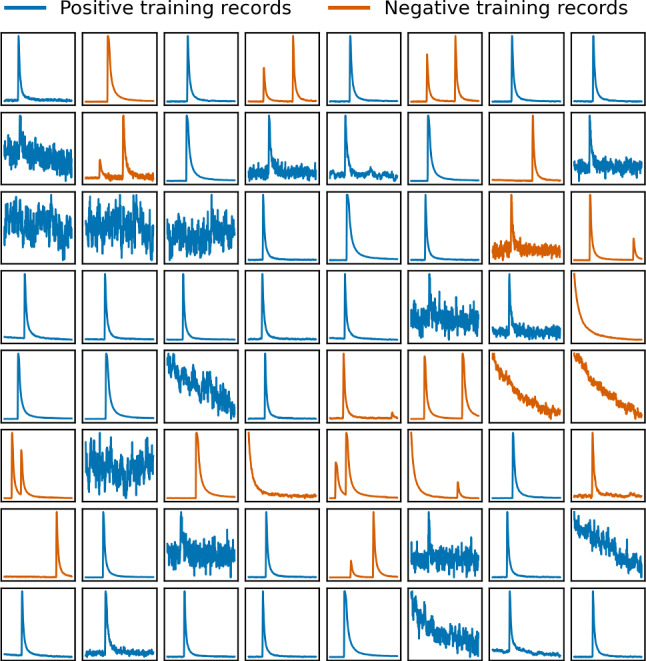
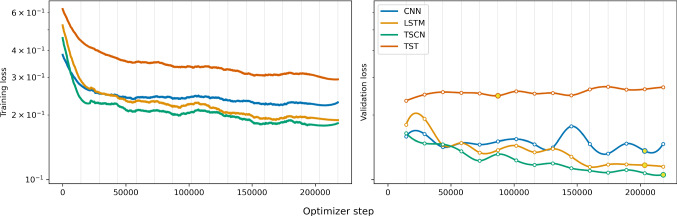
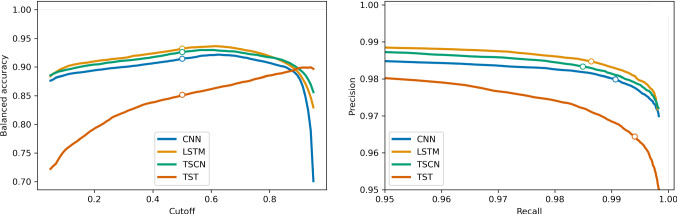
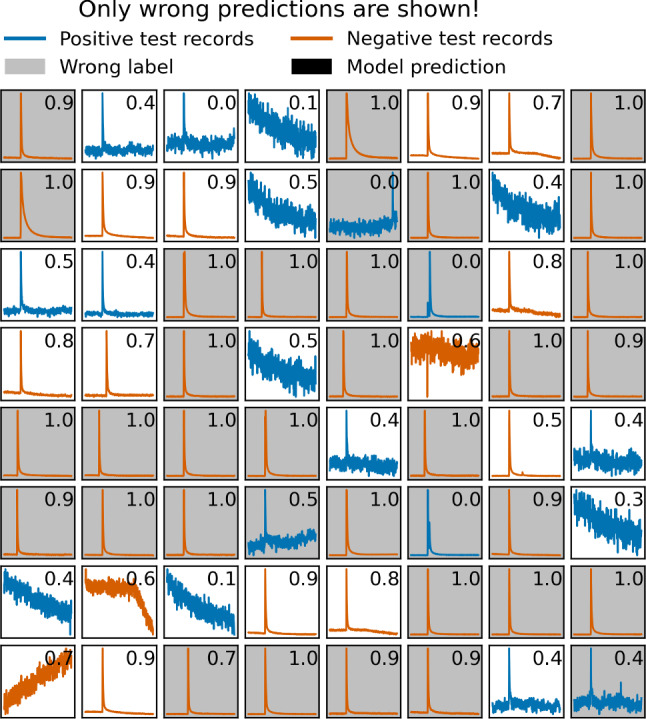
The CRESST experiment employs cryogenic calorimeters for the sensitive measurement of nuclear recoils induced by dark matter particles. The recorded signals need to undergo a careful cleaning process to avoid wrongly reconstructed recoil energies caused by pile-up and read-out artefacts. We frame this process as a time series classification task and propose to automate it with neural networks. With a data set of over one million labeled records from 68 detectors, recorded between 2013 and 2019 by CRESST, we test the capability of four commonly used neural network architectures to learn the data cleaning task. Our best performing model achieves a balanced accuracy of 0.932 on our test set. We show on an exemplary detector that about half of the wrongly predicted events are in fact wrongly labeled events, and a large share of the remaining ones have a context-dependent ground truth. We furthermore evaluate the recall and selectivity of our classifiers with simulated data. The results confirm that the trained classifiers are well suited for the data cleaning task.
© The Author(s) 2023.
Conflict of interest statement
Conflict of interestOn behalf of all authors, the corresponding author states that there is no conflict of interest.
Figures


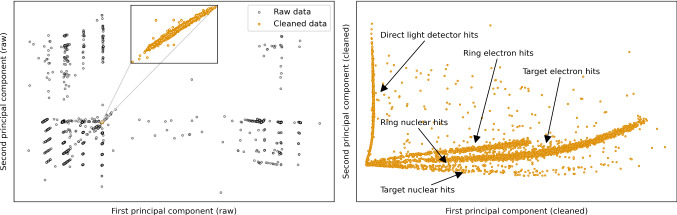
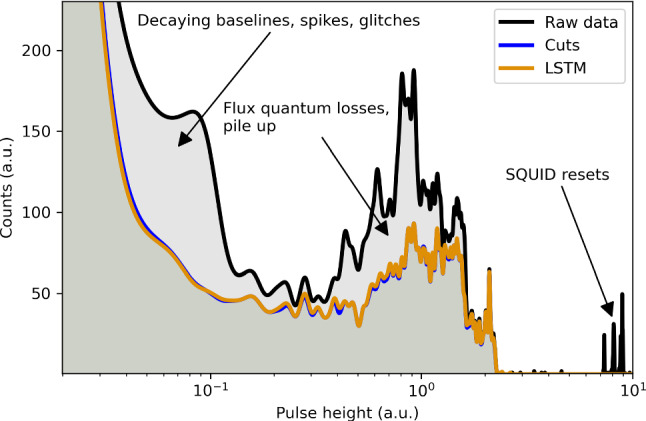
References
-
- N. Planck Collaboration, Y. Aghanim, Akrami et al., Planck 2018 results - vi. cosmological parameters. (2020) 10.1051/0004-6361/201833910
-
- G. Angloher, S. Banik, G. Benato et al., Latest observations on the low energy excess in CRESST-III,” (2022). arXiv:2207.09375
-
- Abdelhameed AH, Angloher G, Bauer P, et al. First results from the CRESST-III low-mass dark matter program. Phys. Rev. D. 2019;100:102002. doi: 10.1103/PhysRevD.100.102002. - DOI
-
- G. Angloher, S. Banik, G. Benato et al., Testing spin-dependent dark matter interactions with lithium aluminate targets in CRESST-III, (2022). arXiv:2207.07640
-
- Ismail Fawaz H, Forestier G, Weber J, et al. Deep learning for time series classification: a review. Data Mining and Knowle. Dis. 2019;33:917–963. doi: 10.1007/s10618-019-00619-1. - DOI
LinkOut - more resources
Full Text Sources