

This is a preprint.
Using Mechanistic Models and Machine Learning to Design Single-Color Multiplexed Nascent Chain Tracking Experiments
- PMID: 36747627
- PMCID: PMC9900927
- DOI: 10.1101/2023.01.25.525583
Using Mechanistic Models and Machine Learning to Design Single-Color Multiplexed Nascent Chain Tracking Experiments
Update in
-
Using mechanistic models and machine learning to design single-color multiplexed nascent chain tracking experiments.Front Cell Dev Biol. 2023 May 30;11:1151318. doi: 10.3389/fcell.2023.1151318. eCollection 2023. Front Cell Dev Biol. 2023. PMID: 37325568 Free PMC article.
Abstract
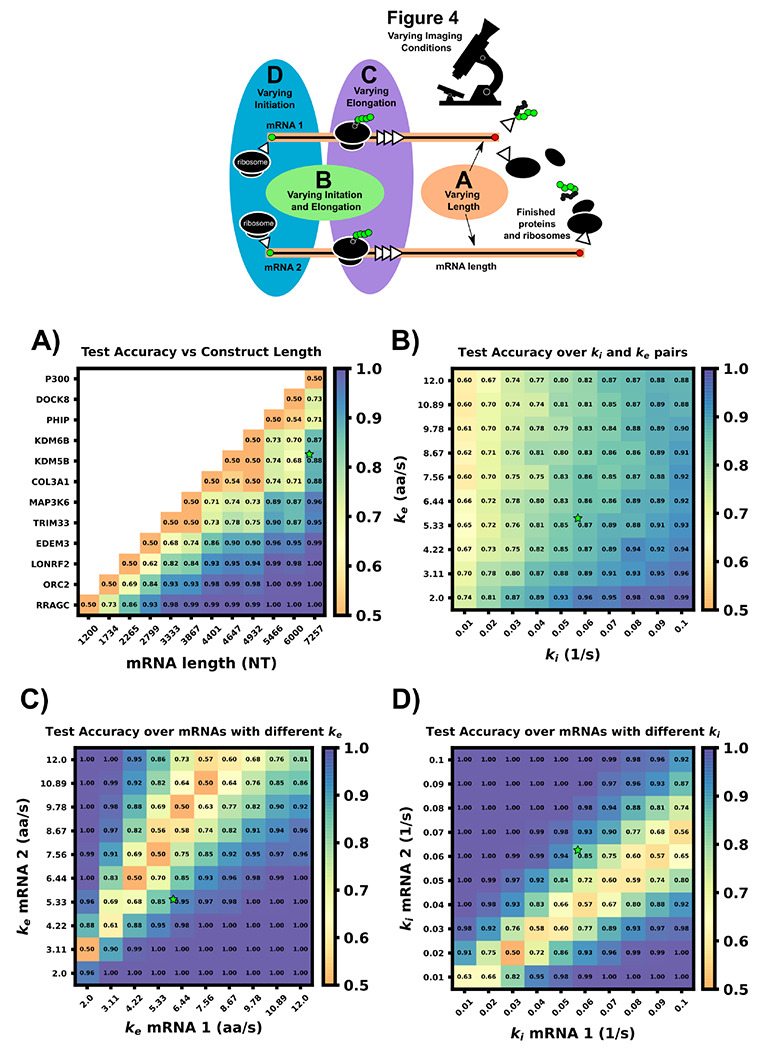
mRNA translation is the ubiquitous cellular process of reading messenger-RNA strands into functional proteins. Over the past decade, large strides in microscopy techniques have allowed observation of mRNA translation at a single-molecule resolution for self-consistent time-series measurements in live cells. Dubbed Nascent chain tracking (NCT), these methods have explored many temporal dynamics in mRNA translation uncaptured by other experimental methods such as ribosomal profiling, smFISH, pSILAC, BONCAT, or FUNCAT-PLA. However, NCT is currently restricted to the observation of one or two mRNA species at a time due to limits in the number of resolvable fluorescent tags. In this work, we propose a hybrid computational pipeline, where detailed mechanistic simulations produce realistic NCT videos, and machine learning is used to assess potential experimental designs for their ability to resolve multiple mRNA species using a single fluorescent color for all species. Through simulation, we show that with careful application, this hybrid design strategy could in principle be used to extend the number of mRNA species that could be watched simultaneously within the same cell. We present a simulated example NCT experiment with seven different mRNA species within the same simulated cell and use our ML labeling to identify these spots with 90% accuracy using only two distinct fluorescent tags. The proposed extension to the NCT color palette should allow experimentalists to access a plethora of new experimental design possibilities, especially for cell signalling applications requiring simultaneous study of multiple mRNAs.
Conflict of interest statement
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures








References
-
- Allan D. B., Caswell T., Keim N. C., van der Wel C. M., and Verweij R. W. (2021). soft-matter/trackpy: Trackpy v0.5.0 doi: 10.5281/zenodo.4682814 - DOI
-
- Bergstra J. and Bengio Y. (2012). Random search for hyper-parameter optimization yoshua bengio. Journal of Machine Learning Research 13, 281–305
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous