

This is a preprint.
Compressed phenotypic screens for complex multicellular models and high-content assays
- PMID: 36747859
- PMCID: PMC9900857
- DOI: 10.1101/2023.01.23.525189
Compressed phenotypic screens for complex multicellular models and high-content assays
Abstract
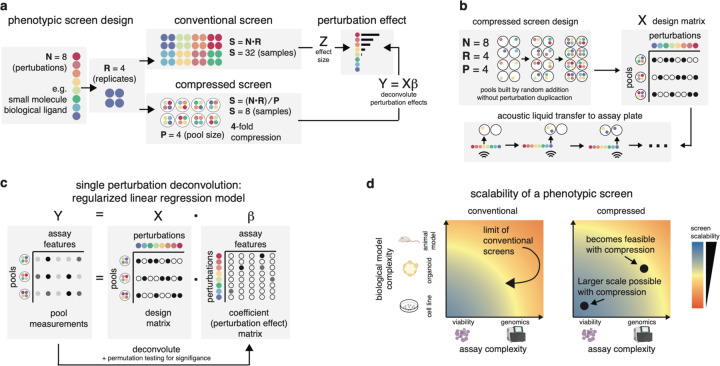
High-throughput phenotypic screens leveraging biochemical perturbations, high-content readouts, and complex multicellular models could advance therapeutic discovery yet remain constrained by limitations of scale. To address this, we establish a method for compressing screens by pooling perturbations followed by computational deconvolution. Conducting controlled benchmarks with a highly bioactive small molecule library and a high-content imaging readout, we demonstrate increased efficiency for compressed experimental designs compared to conventional approaches. To prove generalizability, we apply compressed screening to examine transcriptional responses of patient-derived pancreatic cancer organoids to a library of tumor-microenvironment (TME)-nominated recombinant protein ligands. Using single-cell RNA-seq as a readout, we uncover reproducible phenotypic shifts induced by ligands that correlate with clinical features in larger datasets and are distinct from reference signatures available in public databases. In sum, our approach enables phenotypic screens that interrogate complex multicellular models with rich phenotypic readouts to advance translatable drug discovery as well as basic biology.
Conflict of interest statement
Declaration of Interests A.K.S. reports compensation for consulting and/or SAB membership from Merck, Honeycomb Biotechnologies, Cellarity, Repertoire Immune Medicines, Hovione, Third Rock Ventures, Ochre Bio, FL82, Empress Therapeutics, Relation Therapeutics, Senda Biosciences, IntrECate biotherapeutics, Santa Ana Bio and Dahlia Biosciences unrelated to this work. B.E.M. reports compensation for consulting from Empress Therapeutics unrelated to this work. S.R. holds equity in Amgen. P.C.B. is a consultant to or holds equity in 10X Genomics, General Automation Lab Technologies/Isolation Bio, Celsius Therapeutics, Next Gen Diagnostics, Cache DNA, Concerto Biosciences, Stately, Ramona Optics, and Bifrost. W.C.H. is a consultant for Thermo Fisher, Solasta Ventures, MPM Capital, KSQ Therapeutics, Tyra Biosciences, Jubilant Therapeutics, RAPPTA Therapeutics, Function Oncology, Riva Therapeutics, Serinus Biosciences, Frontier Medicines and Calyx.
Figures






References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases