

Comparison of R9.4.1/Kit10 and R10/Kit12 Oxford Nanopore flowcells and chemistries in bacterial genome reconstruction
- PMID: 36748454
- PMCID: PMC9973852
- DOI: 10.1099/mgen.0.000910
Comparison of R9.4.1/Kit10 and R10/Kit12 Oxford Nanopore flowcells and chemistries in bacterial genome reconstruction
Abstract
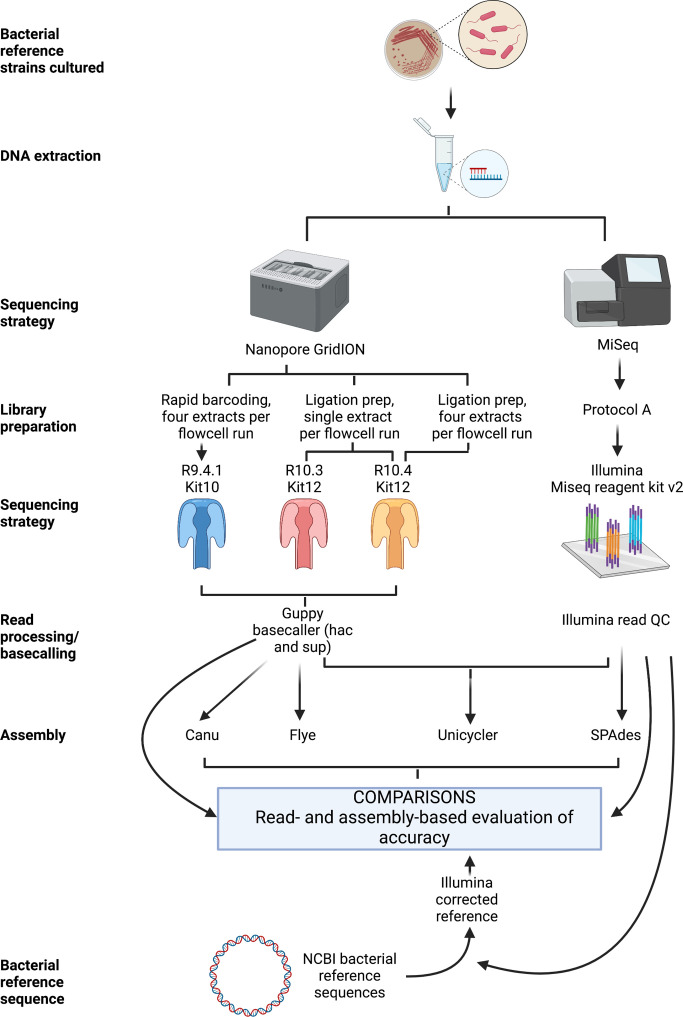
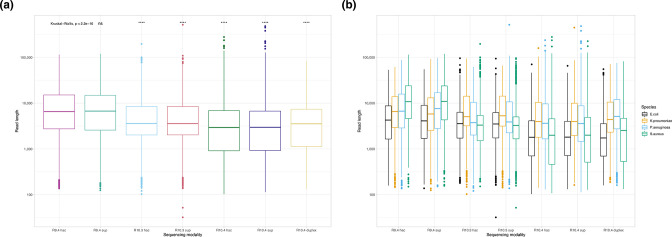
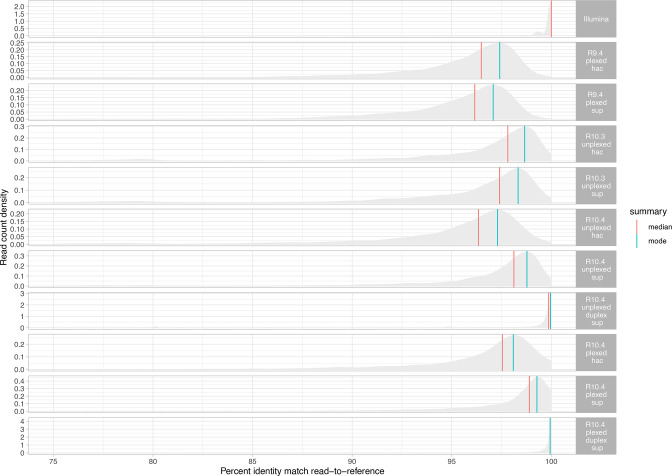
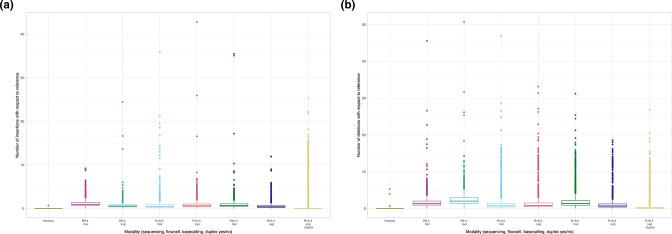
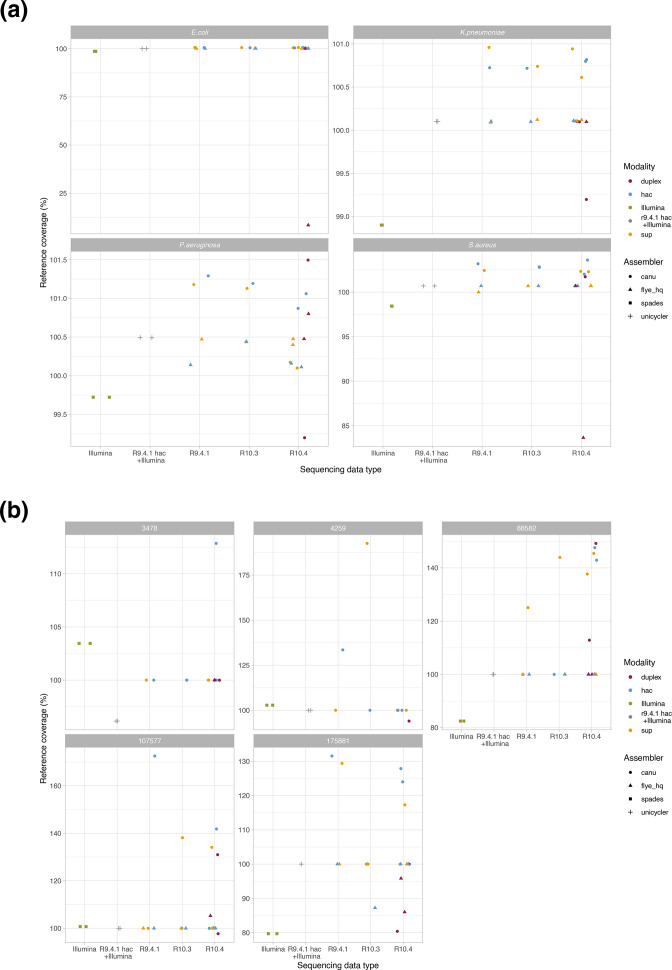
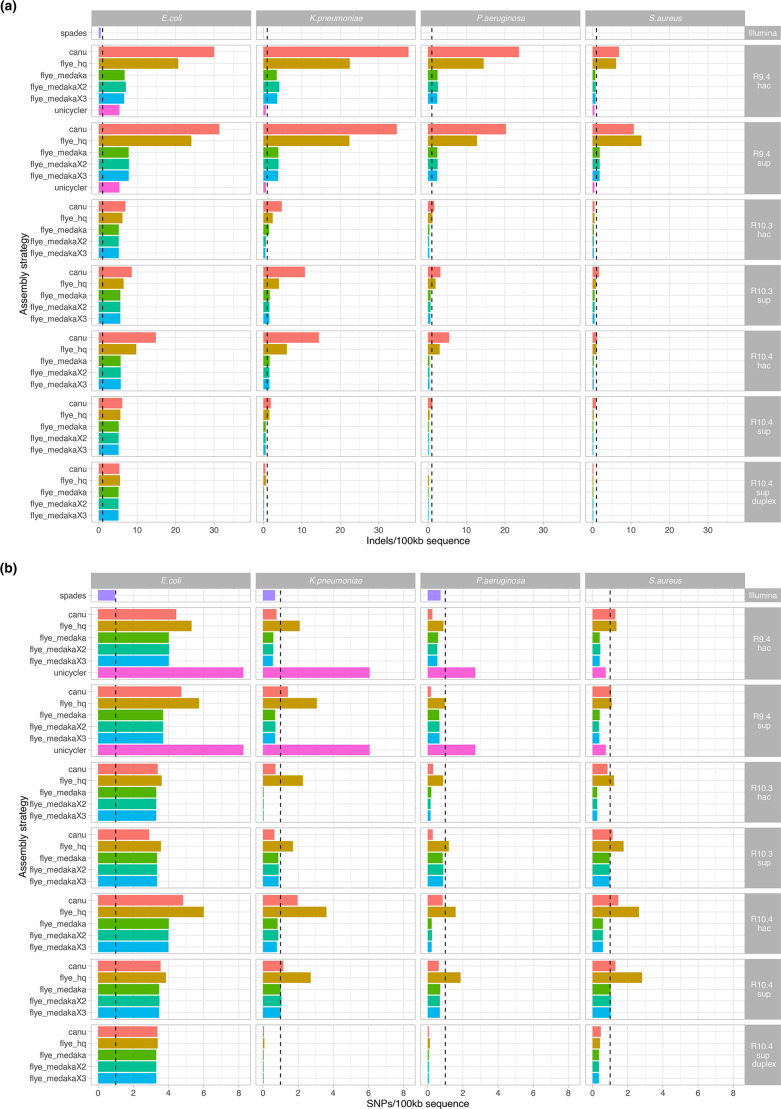
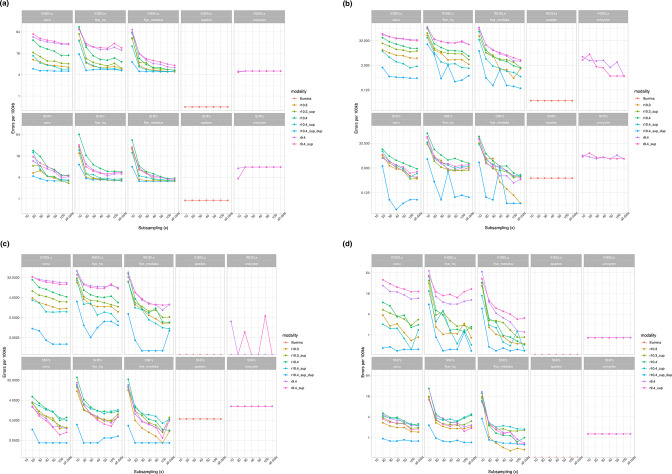
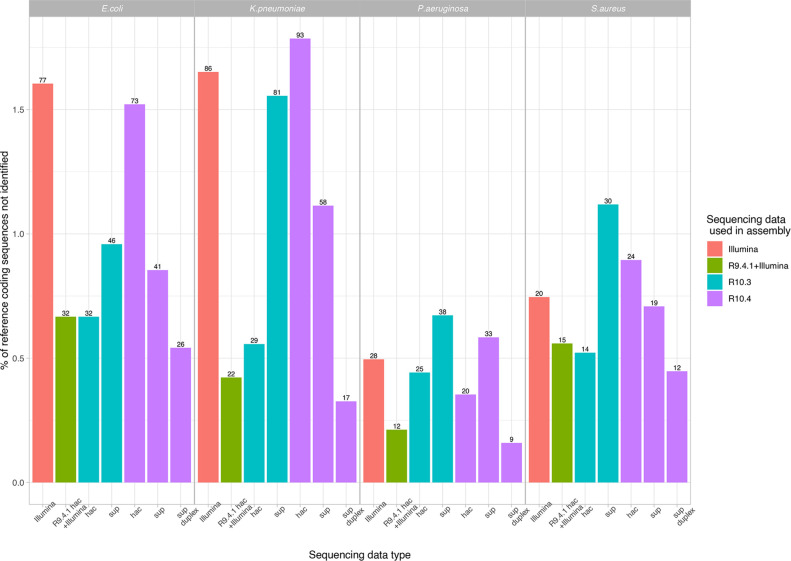
Complete, accurate, cost-effective, and high-throughput reconstruction of bacterial genomes for large-scale genomic epidemiological studies is currently only possible with hybrid assembly, combining long- (typically using nanopore sequencing) and short-read (Illumina) datasets. Being able to use nanopore-only data would be a significant advance. Oxford Nanopore Technologies (ONT) have recently released a new flowcell (R10.4) and chemistry (Kit12), which reportedly generate per-read accuracies rivalling those of Illumina data. To evaluate this, we sequenced DNA extracts from four commonly studied bacterial pathogens, namely Escherichia coli, Klebsiella pneumoniae, Pseudomonas aeruginosa and Staphylococcus aureus, using Illumina and ONT's R9.4.1/Kit10, R10.3/Kit12, R10.4/Kit12 flowcells/chemistries. We compared raw read accuracy and assembly accuracy for each modality, considering the impact of different nanopore basecalling models, commonly used assemblers, sequencing depth, and the use of duplex versus simplex reads. 'Super accuracy' (sup) basecalled R10.4 reads - in particular duplex reads - have high per-read accuracies and could be used to robustly reconstruct bacterial genomes without the use of Illumina data. However, the per-run yield of duplex reads generated in our hands with standard sequencing protocols was low (typically <10 %), with substantial implications for cost and throughput if relying on nanopore data only to enable bacterial genome reconstruction. In addition, recovery of small plasmids with the best-performing long-read assembler (Flye) was inconsistent. R10.4/Kit12 combined with sup basecalling holds promise as a singular sequencing technology in the reconstruction of commonly studied bacterial genomes, but hybrid assembly (Illumina+R9.4.1 hac) currently remains the highest throughput, most robust, and cost-effective approach to fully reconstruct these bacterial genomes.
Keywords: Genome sequencing; hybrid assembly; long-read assembly.
Conflict of interest statement
Oxford Nanopore Technologies supplied the R10.3 and R10.4 flowcells free of charge for this study. They were also involved in discussions regarding which data processing approaches to use to optimise basecalling and assembly outputs; however, they did not impact on the presentation of any of the results.
Figures
References
-
- Oxford Nanopore Technologies. https://nanoporetech.com/about-us/news/r103-newest-nanopore-high-accurac... n.d.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources