

Using machine learning on clinical data to identify unexpected patterns in groups of COVID-19 patients
- PMID: 36755135
- PMCID: PMC9906583
- DOI: 10.1038/s41598-022-26294-9
Using machine learning on clinical data to identify unexpected patterns in groups of COVID-19 patients
Abstract
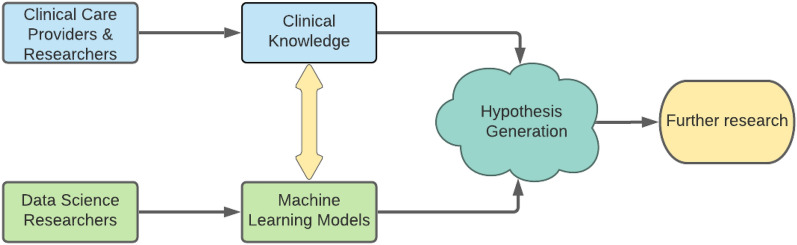
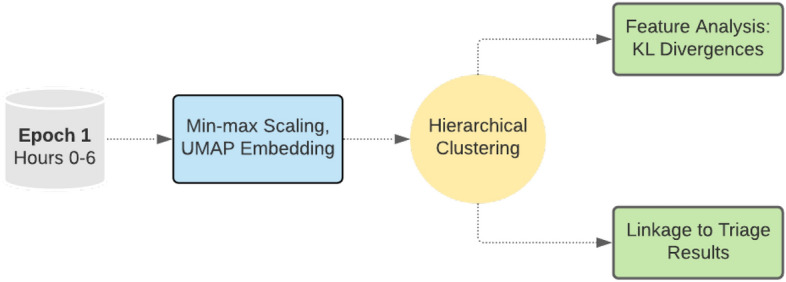
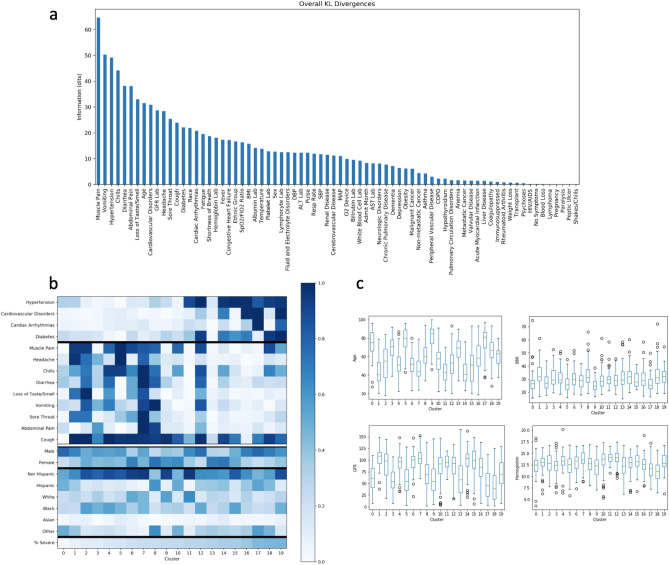
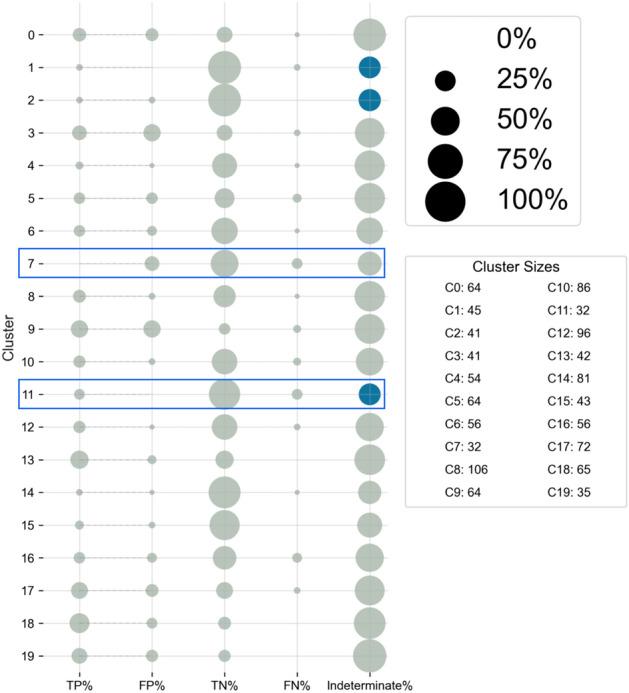
As clinicians are faced with a deluge of clinical data, data science can play an important role in highlighting key features driving patient outcomes, aiding in the development of new clinical hypotheses. Insight derived from machine learning can serve as a clinical support tool by connecting care providers with reliable results from big data analysis that identify previously undetected clinical patterns. In this work, we show an example of collaboration between clinicians and data scientists during the COVID-19 pandemic, identifying sub-groups of COVID-19 patients with unanticipated outcomes or who are high-risk for severe disease or death. We apply a random forest classifier model to predict adverse patient outcomes early in the disease course, and we connect our classification results to unsupervised clustering of patient features that may underpin patient risk. The paradigm for using data science for hypothesis generation and clinical decision support, as well as our triaged classification approach and unsupervised clustering methods to determine patient cohorts, are applicable to driving rapid hypothesis generation and iteration in a variety of clinical challenges, including future public health crises.
© 2023. The Author(s).
Conflict of interest statement
Dr. Garibaldi is a member of the FDA Pulmonary-Asthma Drug Advisory Committee and has received consulting fees from Janssen Research and Development, LLC, Gilead Sciences, Inc and Atea Pharmaceuticals, Inc. All other authors declare no competing interests.
Figures

References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Research Materials
