

Deep Neural Networks and Visuo-Semantic Models Explain Complementary Components of Human Ventral-Stream Representational Dynamics
- PMID: 36759190
- PMCID: PMC10010451
- DOI: 10.1523/JNEUROSCI.1424-22.2022
Deep Neural Networks and Visuo-Semantic Models Explain Complementary Components of Human Ventral-Stream Representational Dynamics
Abstract
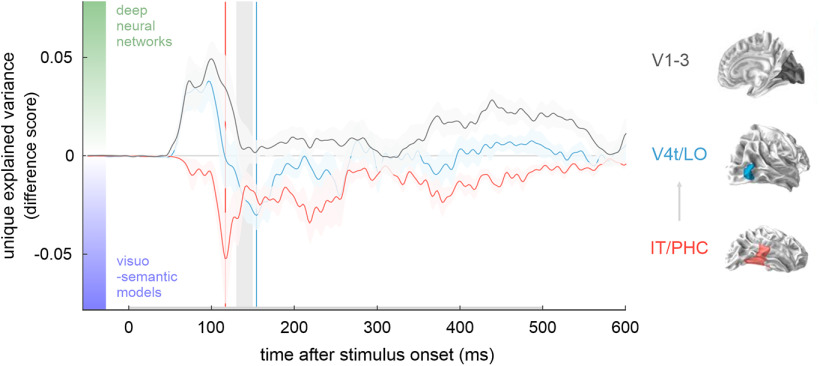
Deep neural networks (DNNs) are promising models of the cortical computations supporting human object recognition. However, despite their ability to explain a significant portion of variance in neural data, the agreement between models and brain representational dynamics is far from perfect. We address this issue by asking which representational features are currently unaccounted for in neural time series data, estimated for multiple areas of the ventral stream via source-reconstructed magnetoencephalography data acquired in human participants (nine females, six males) during object viewing. We focus on the ability of visuo-semantic models, consisting of human-generated labels of object features and categories, to explain variance beyond the explanatory power of DNNs alone. We report a gradual reversal in the relative importance of DNN versus visuo-semantic features as ventral-stream object representations unfold over space and time. Although lower-level visual areas are better explained by DNN features starting early in time (at 66 ms after stimulus onset), higher-level cortical dynamics are best accounted for by visuo-semantic features starting later in time (at 146 ms after stimulus onset). Among the visuo-semantic features, object parts and basic categories drive the advantage over DNNs. These results show that a significant component of the variance unexplained by DNNs in higher-level cortical dynamics is structured and can be explained by readily nameable aspects of the objects. We conclude that current DNNs fail to fully capture dynamic representations in higher-level human visual cortex and suggest a path toward more accurate models of ventral-stream computations.SIGNIFICANCE STATEMENT When we view objects such as faces and cars in our visual environment, their neural representations dynamically unfold over time at a millisecond scale. These dynamics reflect the cortical computations that support fast and robust object recognition. DNNs have emerged as a promising framework for modeling these computations but cannot yet fully account for the neural dynamics. Using magnetoencephalography data acquired in human observers during object viewing, we show that readily nameable aspects of objects, such as 'eye', 'wheel', and 'face', can account for variance in the neural dynamics over and above DNNs. These findings suggest that DNNs and humans may in part rely on different object features for visual recognition and provide guidelines for model improvement.
Keywords: categories; features; object recognition; recurrent deep neural networks; source-reconstructed MEG data; vision.
Copyright © 2023 the authors.
Figures



References
-
- Barbu A, Mayo D, Alverio J, Luo W, Wang C, Gutfreund D, Tenenbaum J, Katz B (2019) ObjectNet: a large-scale bias-controlled dataset for pushing the limits of object recognition models. Paper presented at the meeting of Advances in Neural Information Processing Systems, Vancouver, Canada, November.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources