

Mortality prediction among ICU inpatients based on MIMIC-III database results from the conditional medical generative adversarial network
- PMID: 36798767
- PMCID: PMC9925961
- DOI: 10.1016/j.heliyon.2023.e13200
Mortality prediction among ICU inpatients based on MIMIC-III database results from the conditional medical generative adversarial network
Abstract
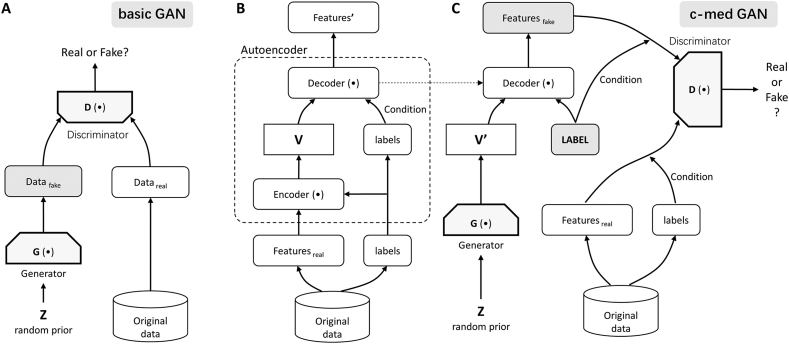
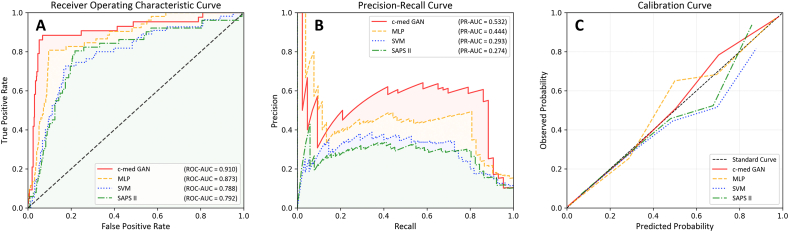
Background and aims: Improved mortality prediction among intensive care unit (ICU) inpatients is a valuable and challenging task. Limited clinical data, especially with appropriate labels, are an important element restricting accurate predictions. Generative adversarial networks (GANs) are excellent generative models and have shown great potential for data simulation. However, there have been no relevant studies using GANs to predict mortality among ICU inpatients. In this study, we aim to evaluate the predictive performance of a variant of GAN called conditional medical GAN (c-med GAN) compared with some baseline models, including simplified acute physiology score II (SAPS II), support vector machine (SVM), and multilayer perceptron (MLP).
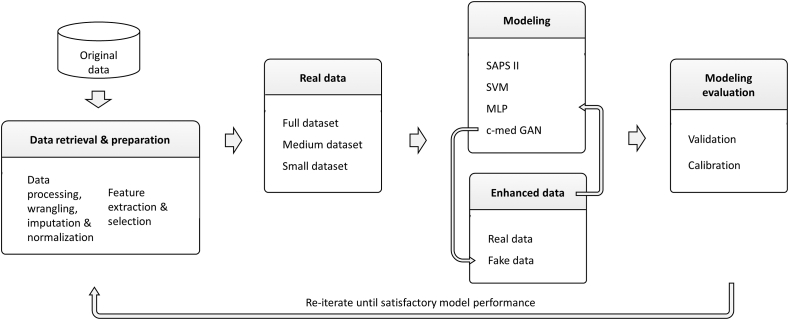
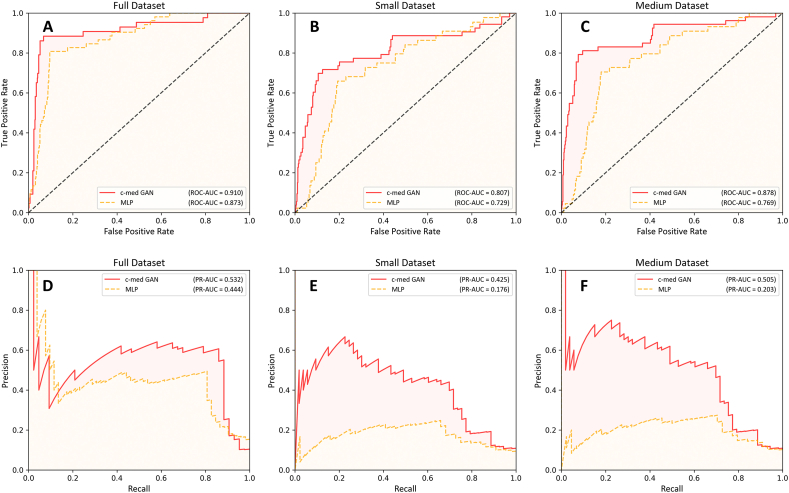
Methods: Data from a publicly available intensive care database, the Medical Information Mart for Intensive Care III (MIMIC-III) database (v1.4), were included in this study. The area under the precision-recall curve (PR-AUC), area under the receiver operating characteristic curve (ROC-AUC), and F1 score were used to evaluate the predictive performance. In addition, the size of the dataset was artificially reduced, and the performance of the c-med GAN was compared in different size datasets.
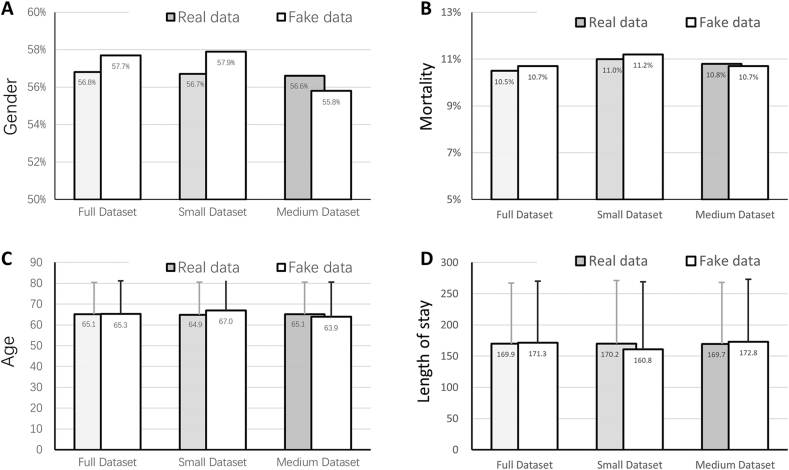
Results: The results showed that c-med GAN achieves the best PR-AUC, ROC-AUC, and F1 score compared with SAPS II, SVM, and MLP when training in the full MIMIC-III dataset. When the size of the dataset was reduced, the prediction performances of both MLP and c-med GAN were affected. However, the c-med GAN still outperformed MLP on smaller datasets and had less degradation.
Conclusion: The prediction of in-hospital mortality based on the c-med GAN for ICU patients showed better performance than the baseline models. Despite some inadequacies, this model may have a promising future in clinical applications which will be explored by further research.
Keywords: C-med GAN; GAN; MIMIC-III; Mortality prediction; ROC-AUC.
© 2023 The Authors.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Knaus W.A., Zimmerman J.E., Wagner D.P., Draper E.A., Lawrence D.E. Apache-acute physiology and chronic health evaluation: a physiologically based classification system. Crit. Care Med. 1981;9(8):591–597. - PubMed
-
- Le Gall J.R., Loirat P., Alperovitch A., Glaser P., Granthil C., Mathieu D., Mercier P., Thomas R., Villers D. A simplified acute physiology score for ICU patients. Crit. Care Med. 1984;12(11):975–977. - PubMed
-
- Vincent J.L., Moreno R., Takala J., Willatts S., De Mendonça A., Bruining H., Reinhart C.K., Suter P.M., Thijs L.G. The SOFA (Sepsis-related organ failure assessment) score to describe organ dysfunction/failure. On behalf of the working Group on sepsis-related problems of the European society of intensive care medicine. Intensive Care Med. 1996;22(7):707–710. - PubMed
-
- Knaus W.A., Draper E.A., Wagner D.P., Zimmerman J.E. Apache II: a severity of disease classification system. Crit. Care Med. 1985;13(10):818–829. - PubMed
-
- Poole D., Rossi C., Latronico N., Rossi G., Finazzi S., Bertolini G. Comparison between SAPS II and SAPS 3 in predicting hospital mortality in a cohort of 103 Italian ICUs. Is new always better? Intensive Care Med. 2012;38(8):1280–1288. - PubMed
LinkOut - more resources
Full Text Sources
Research Materials
