

GReNaDIne: A Data-Driven Python Library to Infer Gene Regulatory Networks from Gene Expression Data
- PMID: 36833196
- PMCID: PMC9957546
- DOI: 10.3390/genes14020269
GReNaDIne: A Data-Driven Python Library to Infer Gene Regulatory Networks from Gene Expression Data
Abstract
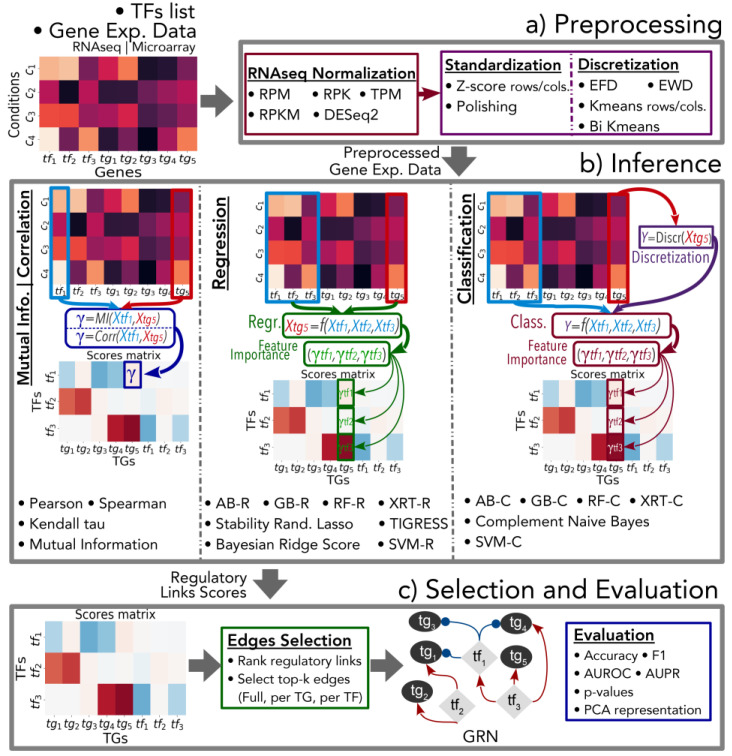
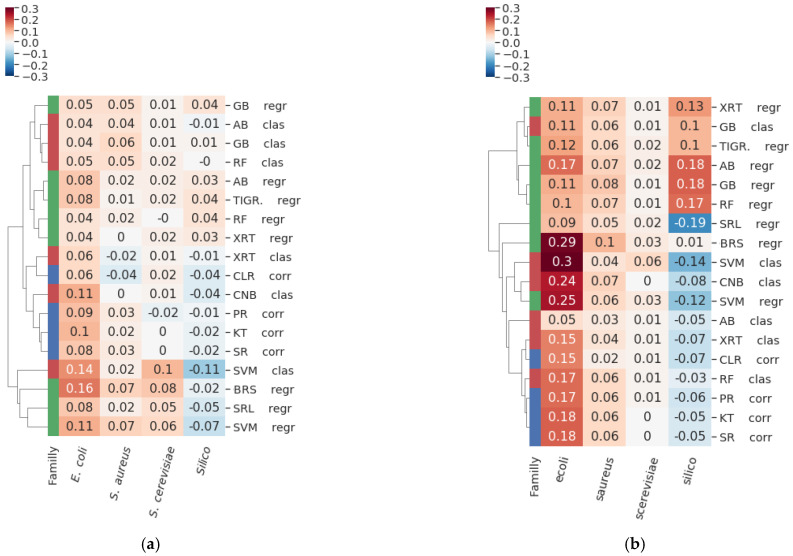
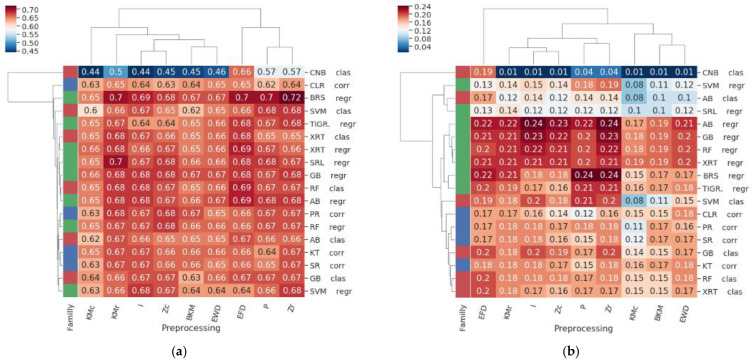
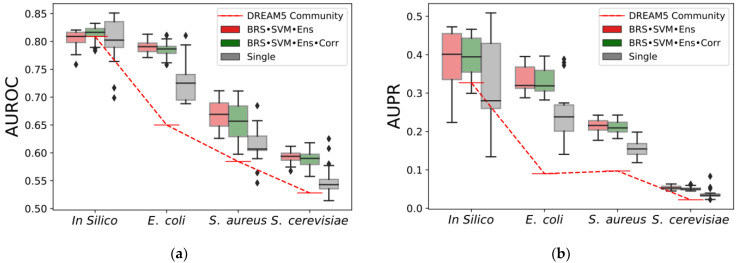
Context: Inferring gene regulatory networks (GRN) from high-throughput gene expression data is a challenging task for which different strategies have been developed. Nevertheless, no ever-winning method exists, and each method has its advantages, intrinsic biases, and application domains. Thus, in order to analyze a dataset, users should be able to test different techniques and choose the most appropriate one. This step can be particularly difficult and time consuming, since most methods' implementations are made available independently, possibly in different programming languages. The implementation of an open-source library containing different inference methods within a common framework is expected to be a valuable toolkit for the systems biology community. Results: In this work, we introduce GReNaDIne (Gene Regulatory Network Data-driven Inference), a Python package that implements 18 machine learning data-driven gene regulatory network inference methods. It also includes eight generalist preprocessing techniques, suitable for both RNA-seq and microarray dataset analysis, as well as four normalization techniques dedicated to RNA-seq. In addition, this package implements the possibility to combine the results of different inference tools to form robust and efficient ensembles. This package has been successfully assessed under the DREAM5 challenge benchmark dataset. The open-source GReNaDIne Python package is made freely available in a dedicated GitLab repository, as well as in the official third-party software repository PyPI Python Package Index. The latest documentation on the GReNaDIne library is also available at Read the Docs, an open-source software documentation hosting platform. Contribution: The GReNaDIne tool represents a technological contribution to the field of systems biology. This package can be used to infer gene regulatory networks from high-throughput gene expression data using different algorithms within the same framework. In order to analyze their datasets, users can apply a battery of preprocessing and postprocessing tools and choose the most adapted inference method from the GReNaDIne library and even combine the output of different methods to obtain more robust results. The results format provided by GReNaDIne is compatible with well-known complementary refinement tools such as PYSCENIC.
Keywords: Python; bioinformatics; ensemble learning; gene expression; gene regulatory network inference; machine learning; systems biology.
Conflict of interest statement
All authors declare no competing interests, either financial or nonfinancial.
Figures
Similar articles
-
GRNBoost2 and Arboreto: efficient and scalable inference of gene regulatory networks.Bioinformatics. 2019 Jun 1;35(12):2159-2161. doi: 10.1093/bioinformatics/bty916. Bioinformatics. 2019. PMID: 30445495
-
MICRAT: a novel algorithm for inferring gene regulatory networks using time series gene expression data.BMC Syst Biol. 2018 Dec 14;12(Suppl 7):115. doi: 10.1186/s12918-018-0635-1. BMC Syst Biol. 2018. PMID: 30547796 Free PMC article.
-
CMIP: a software package capable of reconstructing genome-wide regulatory networks using gene expression data.BMC Bioinformatics. 2016 Dec 23;17(Suppl 17):535. doi: 10.1186/s12859-016-1324-y. BMC Bioinformatics. 2016. PMID: 28155637 Free PMC article.
-
Biological Network Inference and analysis using SEBINI and CABIN.Methods Mol Biol. 2009;541:551-76. doi: 10.1007/978-1-59745-243-4_24. Methods Mol Biol. 2009. PMID: 19381531 Review.
-
Integrated inference and analysis of regulatory networks from multi-level measurements.Methods Cell Biol. 2012;110:19-56. doi: 10.1016/B978-0-12-388403-9.00002-3. Methods Cell Biol. 2012. PMID: 22482944 Free PMC article. Review.
Cited by
-
Aggrephagy-related patterns in tumor microenvironment, prognosis, and immunotherapy for acute myeloid leukemia: a comprehensive single-cell RNA sequencing analysis.Front Oncol. 2023 Jul 17;13:1195392. doi: 10.3389/fonc.2023.1195392. eCollection 2023. Front Oncol. 2023. PMID: 37534253 Free PMC article.
-
Gene Self-Expressive Networks as a Generalization-Aware Tool to Model Gene Regulatory Networks.Biomolecules. 2023 Mar 13;13(3):526. doi: 10.3390/biom13030526. Biomolecules. 2023. PMID: 36979461 Free PMC article.
-
Disruption of Morrbid alleviates autoinflammatory osteomyelitis in Pstpip2-deficient mice.Dis Model Mech. 2025 Jul 1;18(7):dmm052176. doi: 10.1242/dmm.052176. Epub 2025 Jul 7. Dis Model Mech. 2025. PMID: 40503910 Free PMC article.
-
A distinct immune landscape in anti-synthetase syndrome profiled by a single-cell genomic study.Front Immunol. 2024 Oct 24;15:1436114. doi: 10.3389/fimmu.2024.1436114. eCollection 2024. Front Immunol. 2024. PMID: 39512337 Free PMC article.
-
Enhance the therapeutic efficacy of human umbilical cord-derived mesenchymal stem cells in prevention of acute graft-versus-host disease through CRISPLD2 modulation.Stem Cell Res Ther. 2025 May 1;16(1):222. doi: 10.1186/s13287-025-04321-6. Stem Cell Res Ther. 2025. PMID: 40312744 Free PMC article.
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
