

Evidence of a predictive coding hierarchy in the human brain listening to speech
- PMID: 36864133
- PMCID: PMC10038805
- DOI: 10.1038/s41562-022-01516-2
Evidence of a predictive coding hierarchy in the human brain listening to speech
Abstract
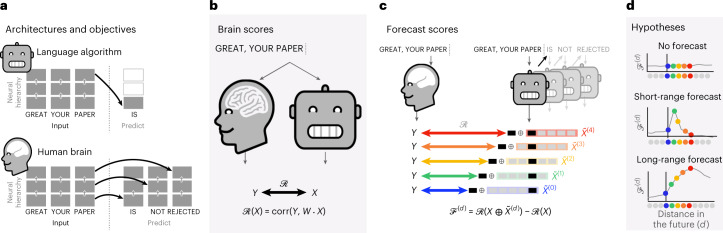
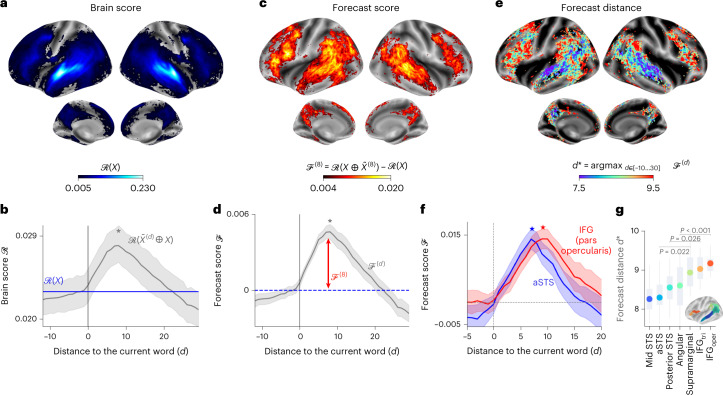
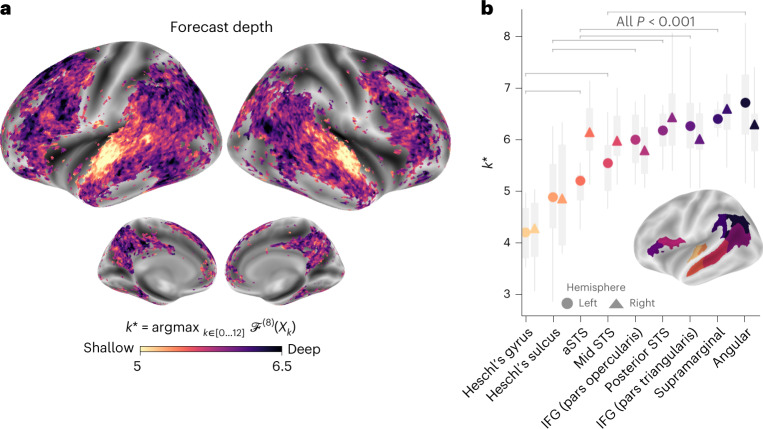
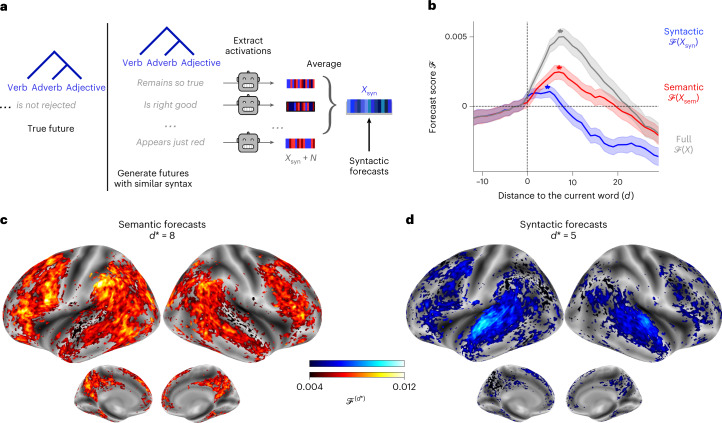
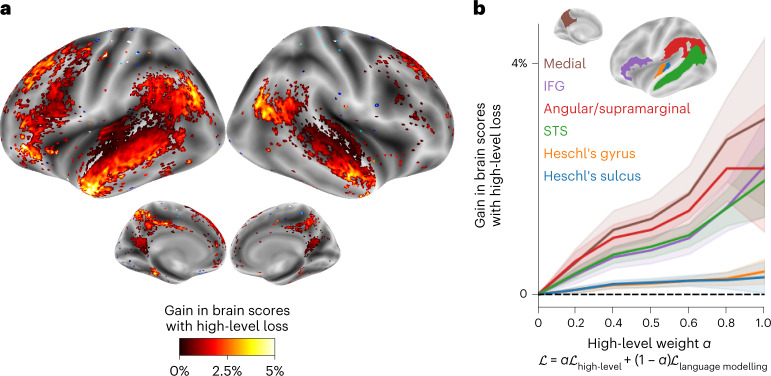
Considerable progress has recently been made in natural language processing: deep learning algorithms are increasingly able to generate, summarize, translate and classify texts. Yet, these language models still fail to match the language abilities of humans. Predictive coding theory offers a tentative explanation to this discrepancy: while language models are optimized to predict nearby words, the human brain would continuously predict a hierarchy of representations that spans multiple timescales. To test this hypothesis, we analysed the functional magnetic resonance imaging brain signals of 304 participants listening to short stories. First, we confirmed that the activations of modern language models linearly map onto the brain responses to speech. Second, we showed that enhancing these algorithms with predictions that span multiple timescales improves this brain mapping. Finally, we showed that these predictions are organized hierarchically: frontoparietal cortices predict higher-level, longer-range and more contextual representations than temporal cortices. Overall, these results strengthen the role of hierarchical predictive coding in language processing and illustrate how the synergy between neuroscience and artificial intelligence can unravel the computational bases of human cognition.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Vaswani, A. et al. Attention is all you need. In Advances in Neural Information Processing Systems, Vol. 30 (Curran Associates, 2017).
-
- Radford, A. et al. Language models are unsupervised multitask Learners (2019).
-
- Brown, T. B. et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, Vol. 33, 1877-1901 (Curran Associates, 2020).
-
- Fan, A., Lewis, M. and Dauphin, Y. Hierarchical Neural Story Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 889–898 (Association for Computational Linguistics, 2018).
-
- Jain, S. and Huth, A. G. Incorporating context into language encoding models for fMRI. In Proc. 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Vol. 31, (Curran Associates, 2018).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
