

Classification of neurologic outcomes from medical notes using natural language processing
- PMID: 36865787
- PMCID: PMC9974159
- DOI: 10.1016/j.eswa.2022.119171
Classification of neurologic outcomes from medical notes using natural language processing
Abstract
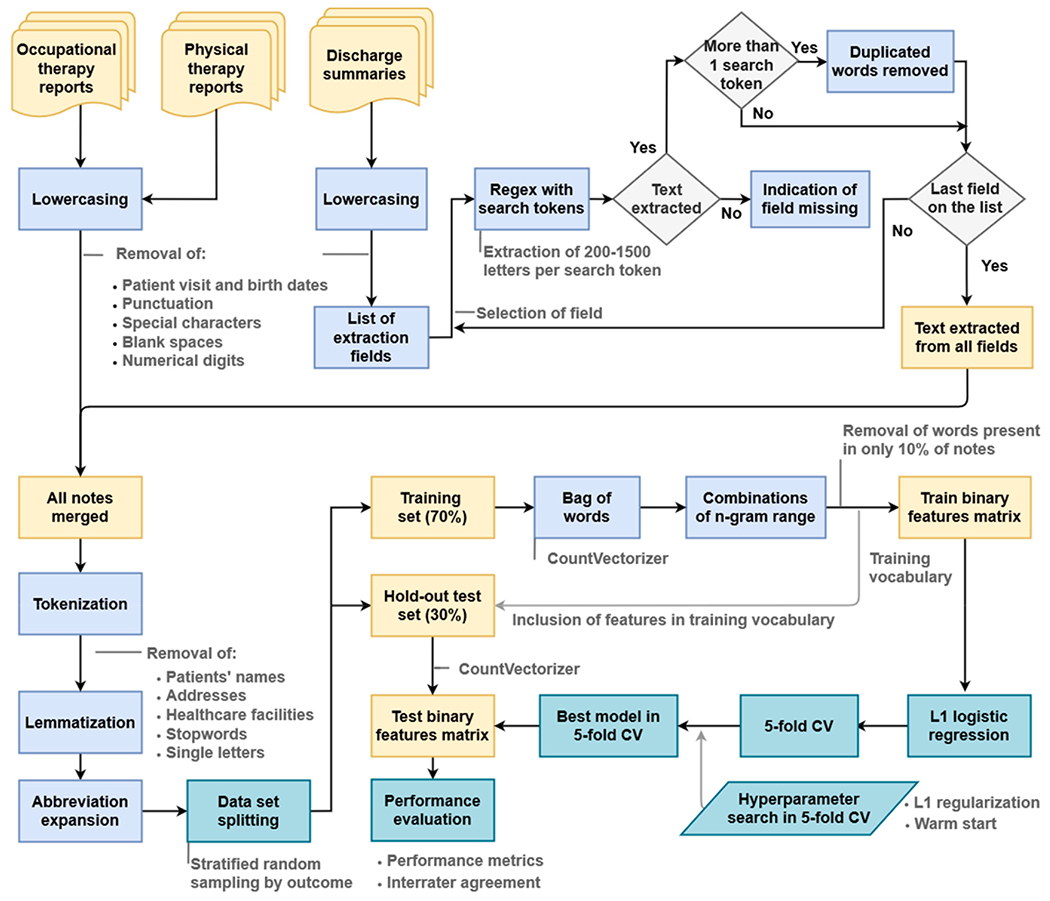
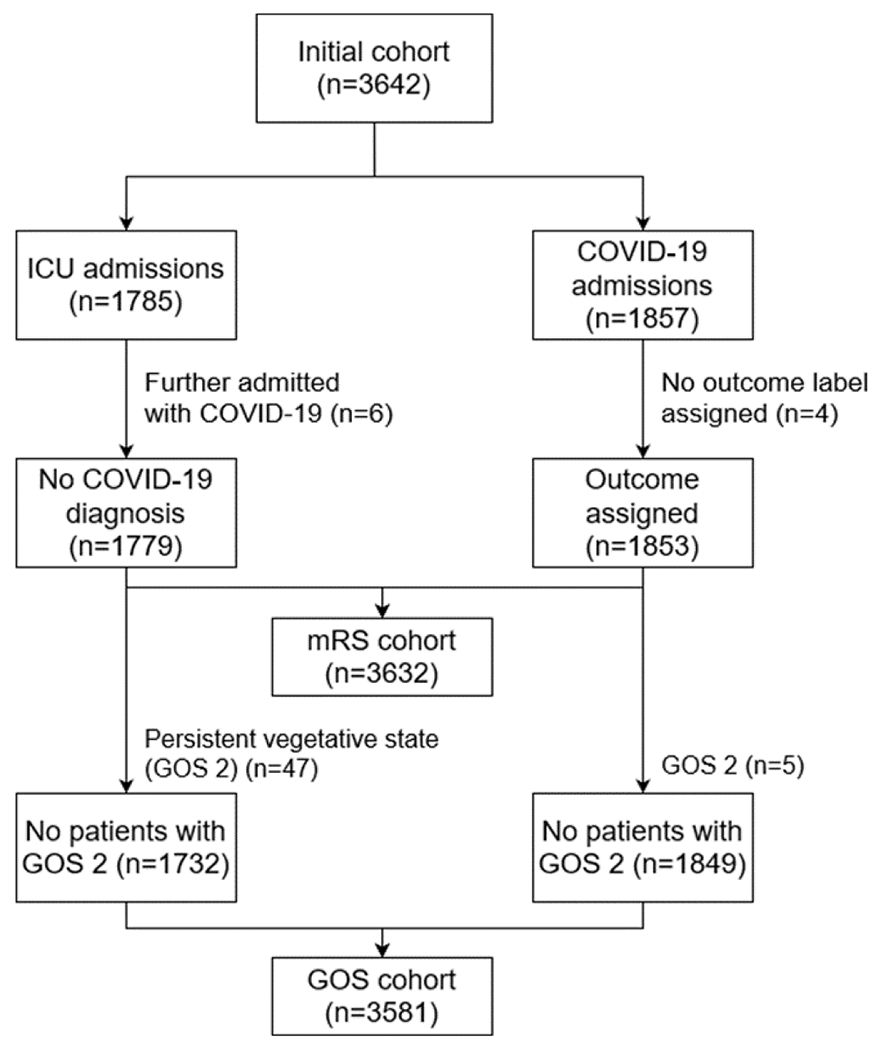
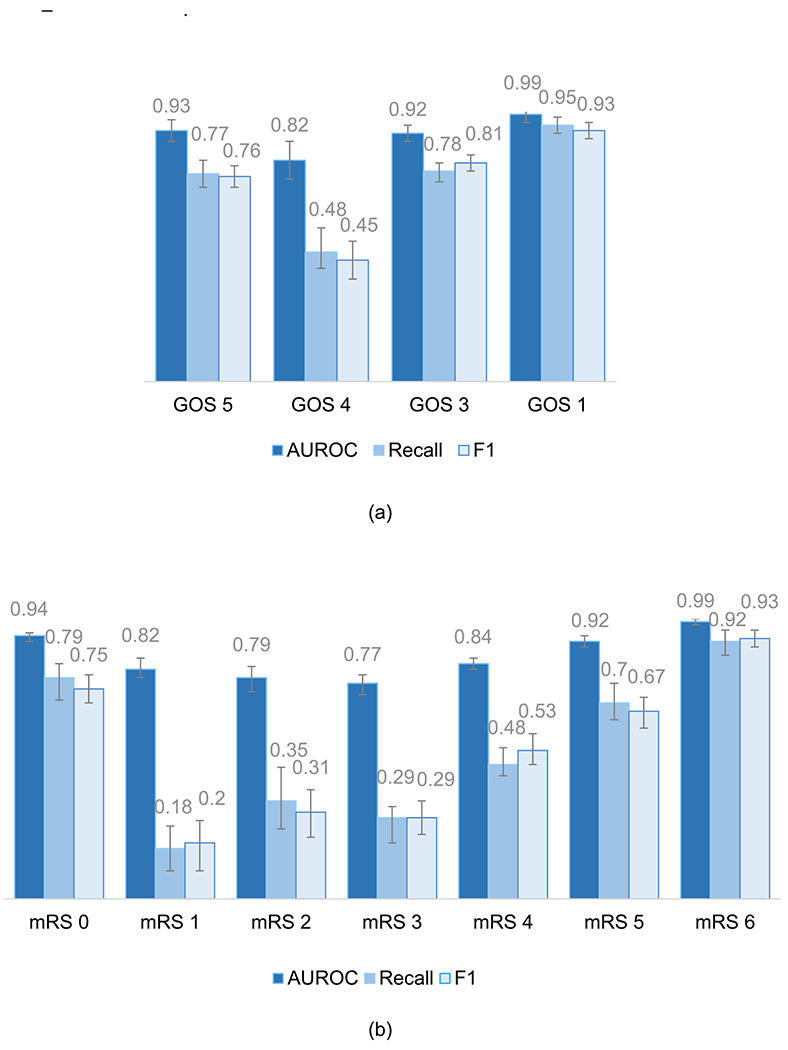
Neurologic disability level at hospital discharge is an important outcome in many clinical research studies. Outside of clinical trials, neurologic outcomes must typically be extracted by labor intensive manual review of clinical notes in the electronic health record (EHR). To overcome this challenge, we set out to develop a natural language processing (NLP) approach that automatically reads clinical notes to determine neurologic outcomes, to make it possible to conduct larger scale neurologic outcomes studies. We obtained 7314 notes from 3632 patients hospitalized at two large Boston hospitals between January 2012 and June 2020, including discharge summaries (3485), occupational therapy (1472) and physical therapy (2357) notes. Fourteen clinical experts reviewed notes to assign scores on the Glasgow Outcome Scale (GOS) with 4 classes, namely 'good recovery', 'moderate disability', 'severe disability', and 'death' and on the Modified Rankin Scale (mRS), with 7 classes, namely 'no symptoms', 'no significant disability', 'slight disability', 'moderate disability', 'moderately severe disability', 'severe disability', and 'death'. For 428 patients' notes, 2 experts scored the cases generating interrater reliability estimates for GOS and mRS. After preprocessing and extracting features from the notes, we trained a multiclass logistic regression model using LASSO regularization and 5-fold cross validation for hyperparameter tuning. The model performed well on the test set, achieving a micro average area under the receiver operating characteristic and F-score of 0.94 (95% CI 0.93-0.95) and 0.77 (0.75-0.80) for GOS, and 0.90 (0.89-0.91) and 0.59 (0.57-0.62) for mRS, respectively. Our work demonstrates that an NLP algorithm can accurately assign neurologic outcomes based on free text clinical notes. This algorithm increases the scale of research on neurological outcomes that is possible with EHR data.
Keywords: Coronavirus; Glasgow outcome scale; Intensive care unit; Machine learning; Modified Rankin Scale; Natural language processing.
Conflict of interest statement
Declaration of Competing Interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures

References
-
- Agarwala S, Anagawadi A, & Reddy Guddeti RM (2021). Detecting Semantic Similarity Of Documents Using Natural Language Processing. Procedia Computer Science, 189, 128–135. 10.1016/j.procs.2021.05.076 - DOI
-
- Alawad M, Gao S, Qiu J, Schaefferkoetter N, Hinkle JD, Yoon H-J, Christian JB, Wu X-C, Durbin EB, Jeong JC, Hands I, Rust D, & Tourassi G (2019). Deep Transfer Learning Across Cancer Registries for Information Extraction from Pathology Reports. IEEE EMBS International Conference on Biomedical Health Informatics (BHI), 2019, 1–4. 10.1109/BHI.2019.8834586 - DOI - PMC - PubMed
-
- Azari A, Janeja VP, & Levin S (2015). Imbalanced learning to predict long stay Emergency Department patients. IEEE International Conference on Bioinformatics and Biomedicine (BIBM), 2015, 807–814.
-
- Bai T, & Vucetic S (2019). Improving Medical Code Prediction from Clinical Text via Incorporating Online Knowledge Sources. The World Wide Web Conference, 72–82. 10.1145/3308558.3313485 - DOI
Grants and funding
LinkOut - more resources
Full Text Sources