

Deep learning methods for drug response prediction in cancer: Predominant and emerging trends
- PMID: 36873878
- PMCID: PMC9975164
- DOI: 10.3389/fmed.2023.1086097
Deep learning methods for drug response prediction in cancer: Predominant and emerging trends
Abstract
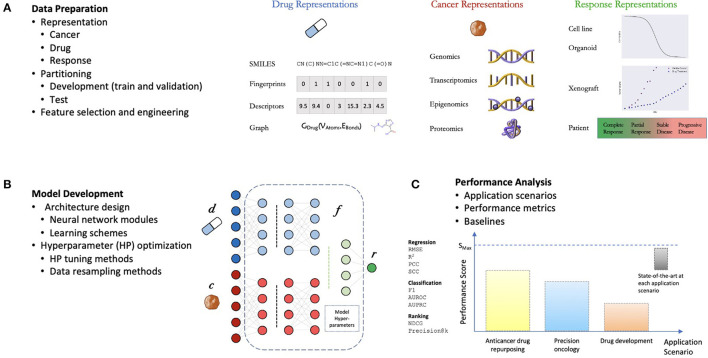
Cancer claims millions of lives yearly worldwide. While many therapies have been made available in recent years, by in large cancer remains unsolved. Exploiting computational predictive models to study and treat cancer holds great promise in improving drug development and personalized design of treatment plans, ultimately suppressing tumors, alleviating suffering, and prolonging lives of patients. A wave of recent papers demonstrates promising results in predicting cancer response to drug treatments while utilizing deep learning methods. These papers investigate diverse data representations, neural network architectures, learning methodologies, and evaluations schemes. However, deciphering promising predominant and emerging trends is difficult due to the variety of explored methods and lack of standardized framework for comparing drug response prediction models. To obtain a comprehensive landscape of deep learning methods, we conducted an extensive search and analysis of deep learning models that predict the response to single drug treatments. A total of 61 deep learning-based models have been curated, and summary plots were generated. Based on the analysis, observable patterns and prevalence of methods have been revealed. This review allows to better understand the current state of the field and identify major challenges and promising solution paths.
Keywords: deep learning; drug response prediction; drug sensitivity; multiomics; neural networks; personalized medicine; precision medicine; precision oncology.
Copyright © 2023 Partin, Brettin, Zhu, Narykov, Clyde, Overbeek and Stevens.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures






References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources