

Transformer-based structuring of free-text radiology report databases
- PMID: 36905469
- PMCID: PMC10181962
- DOI: 10.1007/s00330-023-09526-y
Transformer-based structuring of free-text radiology report databases
Abstract
Objectives: To provide insights for on-site development of transformer-based structuring of free-text report databases by investigating different labeling and pre-training strategies.
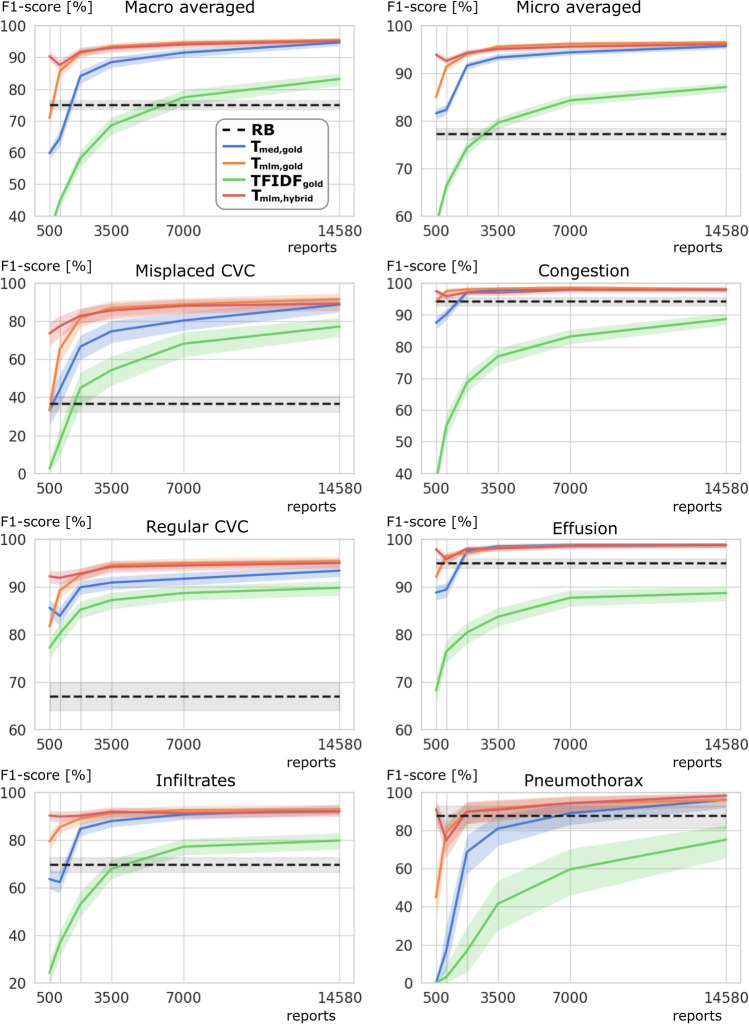
Methods: A total of 93,368 German chest X-ray reports from 20,912 intensive care unit (ICU) patients were included. Two labeling strategies were investigated to tag six findings of the attending radiologist. First, a system based on human-defined rules was applied for annotation of all reports (termed "silver labels"). Second, 18,000 reports were manually annotated in 197 h (termed "gold labels") of which 10% were used for testing. An on-site pre-trained model (Tmlm) using masked-language modeling (MLM) was compared to a public, medically pre-trained model (Tmed). Both models were fine-tuned on silver labels only, gold labels only, and first with silver and then gold labels (hybrid training) for text classification, using varying numbers (N: 500, 1000, 2000, 3500, 7000, 14,580) of gold labels. Macro-averaged F1-scores (MAF1) in percent were calculated with 95% confidence intervals (CI).
Results: Tmlm,gold (95.5 [94.5-96.3]) showed significantly higher MAF1 than Tmed,silver (75.0 [73.4-76.5]) and Tmlm,silver (75.2 [73.6-76.7]), but not significantly higher MAF1 than Tmed,gold (94.7 [93.6-95.6]), Tmed,hybrid (94.9 [93.9-95.8]), and Tmlm,hybrid (95.2 [94.3-96.0]). When using 7000 or less gold-labeled reports, Tmlm,gold (N: 7000, 94.7 [93.5-95.7]) showed significantly higher MAF1 than Tmed,gold (N: 7000, 91.5 [90.0-92.8]). With at least 2000 gold-labeled reports, utilizing silver labels did not lead to significant improvement of Tmlm,hybrid (N: 2000, 91.8 [90.4-93.2]) over Tmlm,gold (N: 2000, 91.4 [89.9-92.8]).
Conclusions: Custom pre-training of transformers and fine-tuning on manual annotations promises to be an efficient strategy to unlock report databases for data-driven medicine.
Key points: • On-site development of natural language processing methods that retrospectively unlock free-text databases of radiology clinics for data-driven medicine is of great interest. • For clinics seeking to develop methods on-site for retrospective structuring of a report database of a certain department, it remains unclear which of previously proposed strategies for labeling reports and pre-training models is the most appropriate in context of, e.g., available annotator time. • Using a custom pre-trained transformer model, along with a little annotation effort, promises to be an efficient way to retrospectively structure radiological databases, even if not millions of reports are available for pre-training.
Keywords: Deep learning; Intensive care units; Natural language processing; Radiology; Thorax.
© 2023. The Author(s).
Conflict of interest statement
The authors of this manuscript declare no relationships with any companies whose products or services may be related to the subject matter of the article.
Figures

Comment in
-
Transformers, codes and labels: large language modelling for natural language processing in clinical radiology.Eur Radiol. 2023 Jun;33(6):4226-4227. doi: 10.1007/s00330-023-09566-4. Epub 2023 Apr 4. Eur Radiol. 2023. PMID: 37014411 No abstract available.
References
-
- Irvin J, Rajpurkar P, Ko M, et al. Chexpert: a large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence. 2019;33(1):590–597. doi: 10.1609/aaai.v33i01.3301590. - DOI
-
- Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. In Advances in neural information processing systems 30
-
- Devlin J, Chang MW, Lee K, Toutanova K (2018) Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
