

This is a preprint.
Stabl: sparse and reliable biomarker discovery in predictive modeling of high-dimensional omic data
- PMID: 36909508
- PMCID: PMC10002850
- DOI: 10.21203/rs.3.rs-2609859/v1
Stabl: sparse and reliable biomarker discovery in predictive modeling of high-dimensional omic data
Update in
-
Discovery of sparse, reliable omic biomarkers with Stabl.Nat Biotechnol. 2024 Oct;42(10):1581-1593. doi: 10.1038/s41587-023-02033-x. Epub 2024 Jan 2. Nat Biotechnol. 2024. PMID: 38168992 Free PMC article.
Abstract
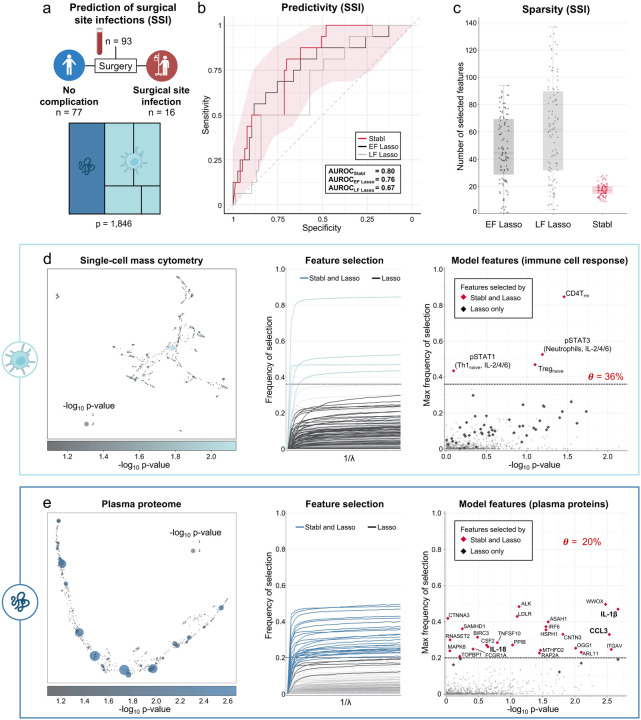
High-content omic technologies coupled with sparsity-promoting regularization methods (SRM) have transformed the biomarker discovery process. However, the translation of computational results into a clinical use-case scenario remains challenging. A rate-limiting step is the rigorous selection of reliable biomarker candidates among a host of biological features included in multivariate models. We propose Stabl, a machine learning framework that unifies the biomarker discovery process with multivariate predictive modeling of clinical outcomes by selecting a sparse and reliable set of biomarkers. Evaluation of Stabl on synthetic datasets and four independent clinical studies demonstrates improved biomarker sparsity and reliability compared to commonly used SRMs at similar predictive performance. Stabl readily extends to double- and triple-omics integration tasks and identifies a sparser and more reliable set of biomarkers than those selected by state-of-the-art early- and late-fusion SRMs, thereby facilitating the biological interpretation and clinical translation of complex multi-omic predictive models. The complete package for Stabl is available online at https://github.com/gregbellan/Stabl.
Figures
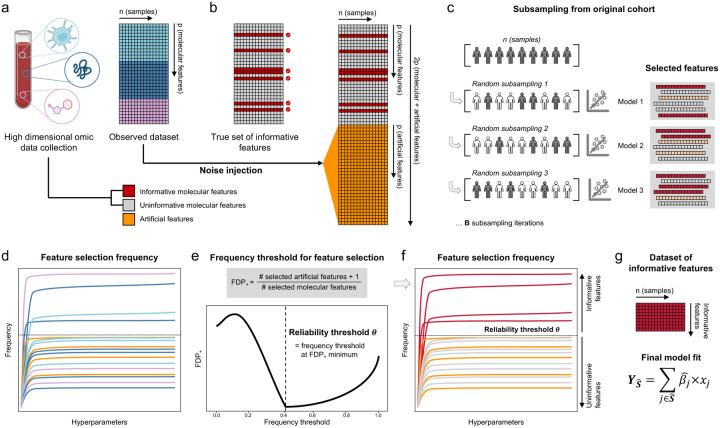
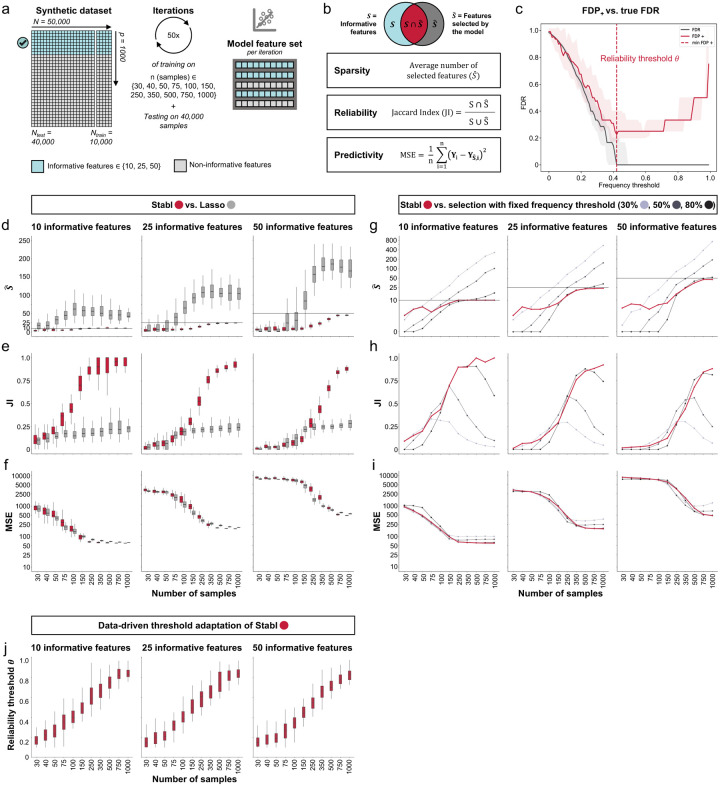
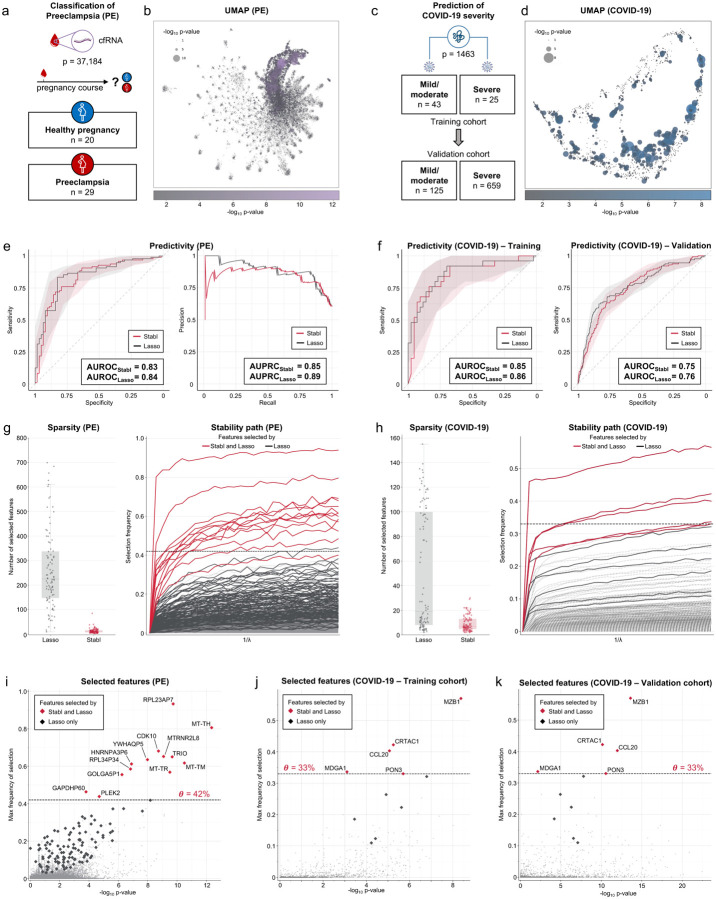
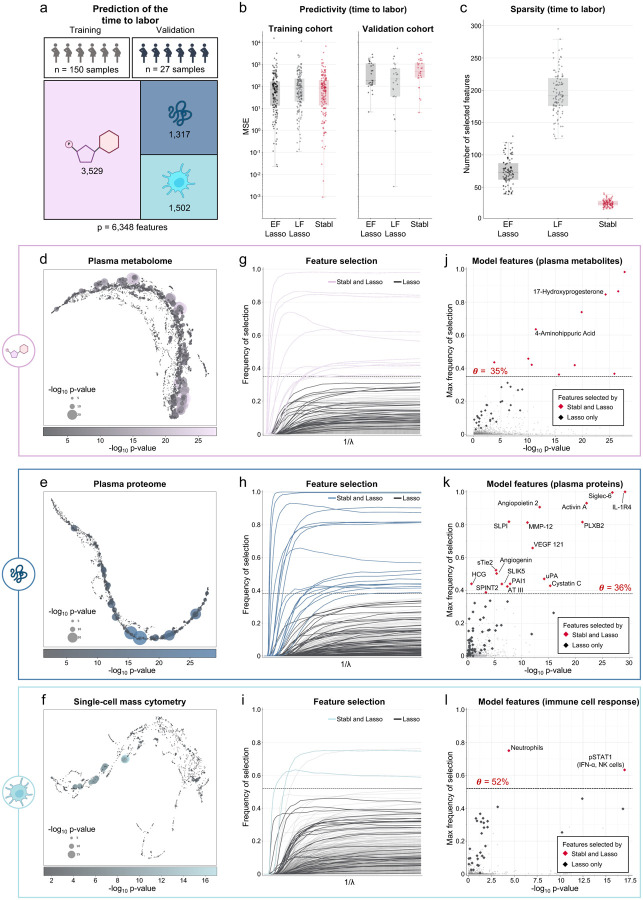
References
-
- Wafi A. & Mirnezami R. Translational –omics: Future potential and current challenges in precision medicine. Methods 151, 3–11 (2018). - PubMed
-
- Ghosh D. & Poisson L. M. “Omics” data and levels of evidence for biomarker discovery. Genomics 93, 13–16 (2009). - PubMed
-
- Tibshirani R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B Methodol. 58, 267–288 (1996).
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
