

This is a preprint.
Assessing the Accuracy and Reliability of AI-Generated Medical Responses: An Evaluation of the Chat-GPT Model
- PMID: 36909565
- PMCID: PMC10002821
- DOI: 10.21203/rs.3.rs-2566942/v1
Assessing the Accuracy and Reliability of AI-Generated Medical Responses: An Evaluation of the Chat-GPT Model
Abstract
Background: Natural language processing models such as ChatGPT can generate text-based content and are poised to become a major information source in medicine and beyond. The accuracy and completeness of ChatGPT for medical queries is not known.
Methods: Thirty-three physicians across 17 specialties generated 284 medical questions that they subjectively classified as easy, medium, or hard with either binary (yes/no) or descriptive answers. The physicians then graded ChatGPT-generated answers to these questions for accuracy (6-point Likert scale; range 1 - completely incorrect to 6 - completely correct) and completeness (3-point Likert scale; range 1 - incomplete to 3 - complete plus additional context). Scores were summarized with descriptive statistics and compared using Mann-Whitney U or Kruskal-Wallis testing.
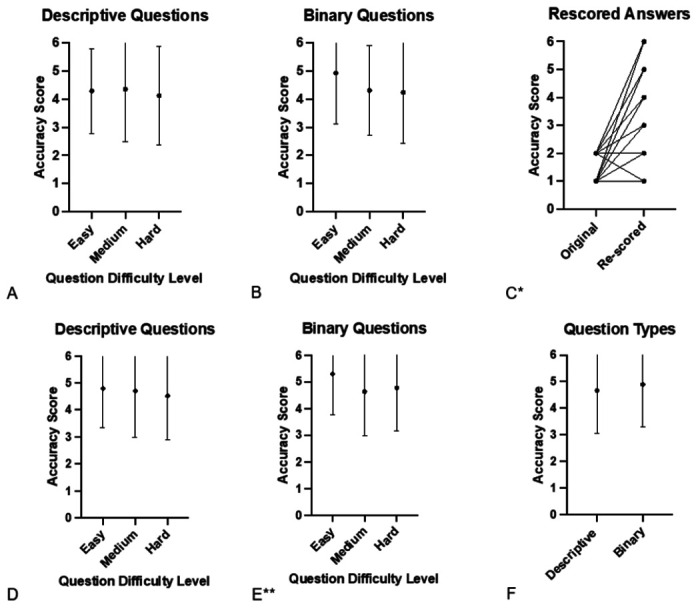
Results: Across all questions (n=284), median accuracy score was 5.5 (between almost completely and completely correct) with mean score of 4.8 (between mostly and almost completely correct). Median completeness score was 3 (complete and comprehensive) with mean score of 2.5. For questions rated easy, medium, and hard, median accuracy scores were 6, 5.5, and 5 (mean 5.0, 4.7, and 4.6; p=0.05). Accuracy scores for binary and descriptive questions were similar (median 6 vs. 5; mean 4.9 vs. 4.7; p=0.07). Of 36 questions with scores of 1-2, 34 were re-queried/re-graded 8-17 days later with substantial improvement (median 2 vs. 4; p<0.01).
Conclusions: ChatGPT generated largely accurate information to diverse medical queries as judged by academic physician specialists although with important limitations. Further research and model development are needed to correct inaccuracies and for validation.
Keywords: ChatGPT; artificial intelligence; clinical decision making; deep learning; knowledge dissemination; large language model; medical education; natural language processing.
Figures
References
-
- Shen Y, Heacock L, Elias J, Hentel KD, Reig B, Shih G, et al. ChatGPT and Other Large Language Models Are Double-edged Swords. Radiological Society of North America; 2023. p. 230163. - PubMed
-
- Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal R et al. Language models are few-shot learners. Advances in neural information processing systems. 2020;33:1877–901.
-
- Christiano PF, Leike J, Brown T, Martic M, Legg S, Amodei D. Deep reinforcement learning from human preferences. Advances in neural information processing systems. 2017;30.
-
- Gilson A, Safranek C, Huang T, Socrates V, Chi L, Taylor RA, et al. How Well Does ChatGPT Do When Taking the Medical Licensing Exams? The Implications of Large Language Models for Medical Education and Knowledge Assessment. medRxiv. 2022:2022.12. 23.22283901. - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
