

Evaluating the use of large language model in identifying top research questions in gastroenterology
- PMID: 36914821
- PMCID: PMC10011374
- DOI: 10.1038/s41598-023-31412-2
Evaluating the use of large language model in identifying top research questions in gastroenterology
Abstract
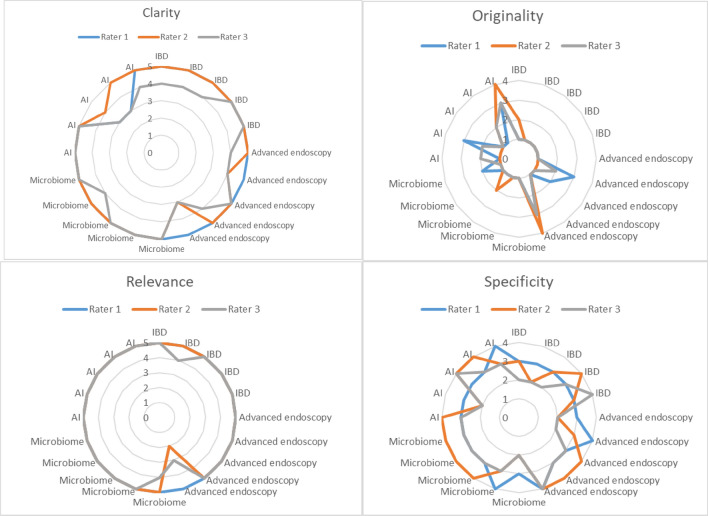
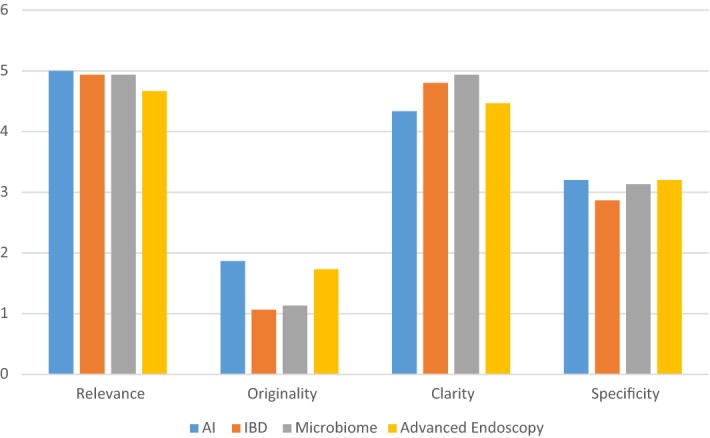
The field of gastroenterology (GI) is constantly evolving. It is essential to pinpoint the most pressing and important research questions. To evaluate the potential of chatGPT for identifying research priorities in GI and provide a starting point for further investigation. We queried chatGPT on four key topics in GI: inflammatory bowel disease, microbiome, Artificial Intelligence in GI, and advanced endoscopy in GI. A panel of experienced gastroenterologists separately reviewed and rated the generated research questions on a scale of 1-5, with 5 being the most important and relevant to current research in GI. chatGPT generated relevant and clear research questions. Yet, the questions were not considered original by the panel of gastroenterologists. On average, the questions were rated 3.6 ± 1.4, with inter-rater reliability ranging from 0.80 to 0.98 (p < 0.001). The mean grades for relevance, clarity, specificity, and originality were 4.9 ± 0.1, 4.6 ± 0.4, 3.1 ± 0.2, 1.5 ± 0.4, respectively. Our study suggests that Large Language Models (LLMs) may be a useful tool for identifying research priorities in the field of GI, but more work is needed to improve the novelty of the generated research questions.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- About OpenAI. Retrieved from https://openai.com/about/
-
- Zhou, X., Zhang, Y., Cui, L. & Huang, D. Evaluating commonsense in pre-trained language models. ArXiv. 10.48550/arXiv.1911.11931 (2019).
-
- Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S. & Zaremba, W. Evaluating large language models trained on code. ArXiv. 10.48550/arXiv.2107.03374 (2021).
MeSH terms
LinkOut - more resources
Full Text Sources
