

Blind Users Accessing Their Training Images in Teachable Object Recognizers
- PMID: 36916963
- PMCID: PMC10008526
- DOI: 10.1145/3517428.3544824
Blind Users Accessing Their Training Images in Teachable Object Recognizers
Abstract
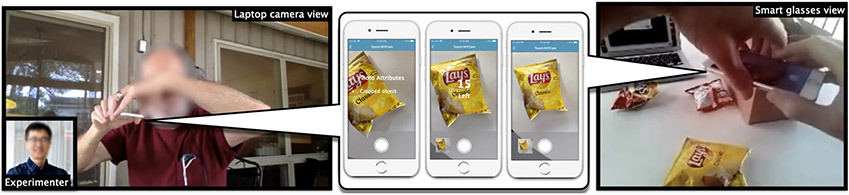
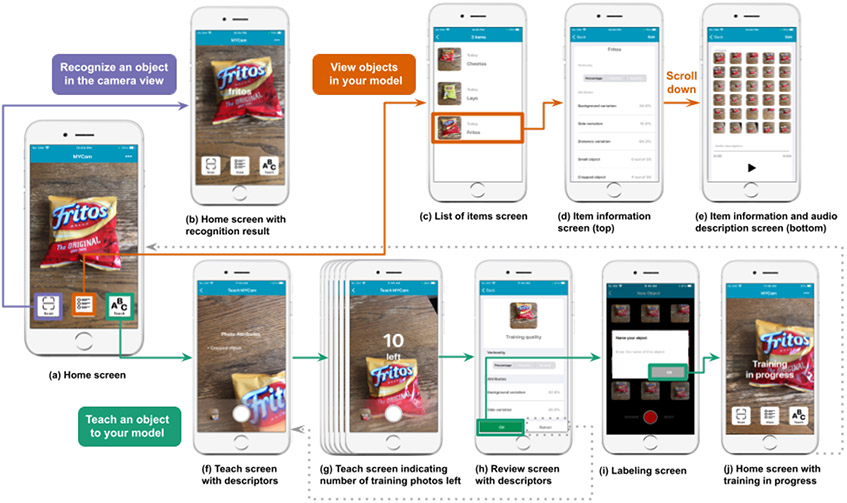
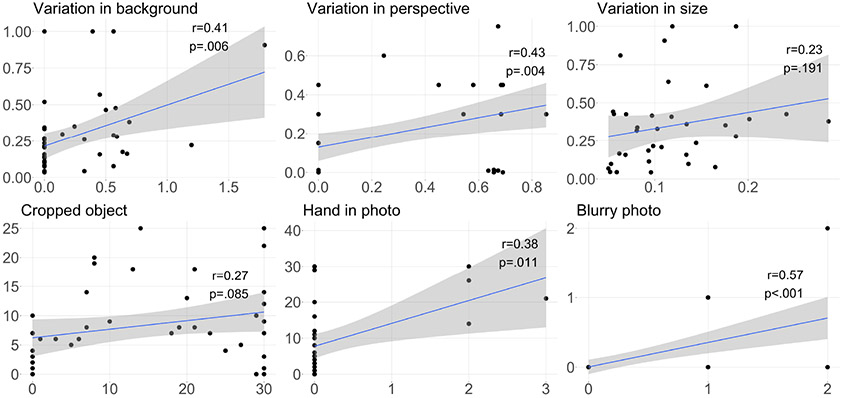
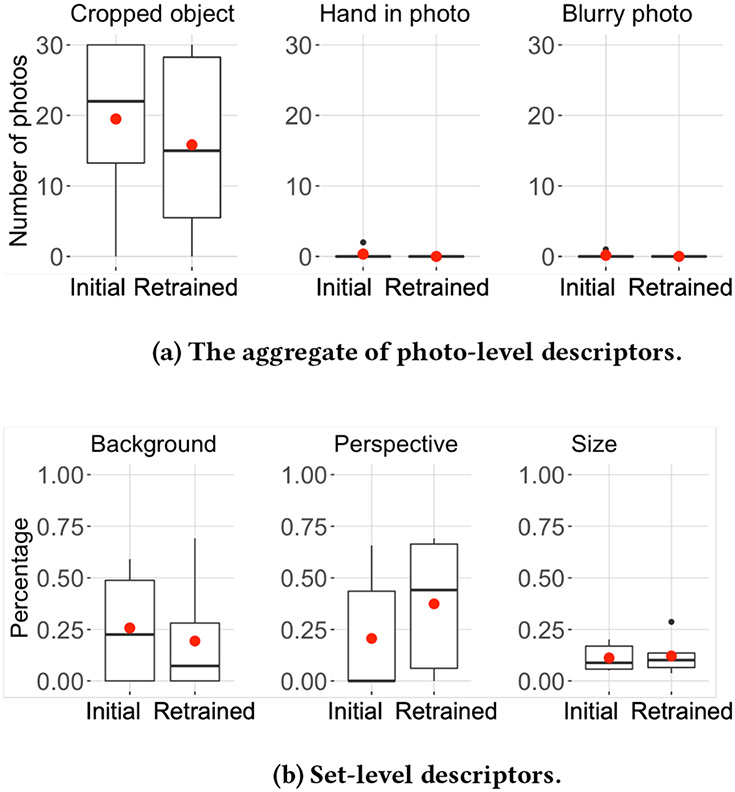
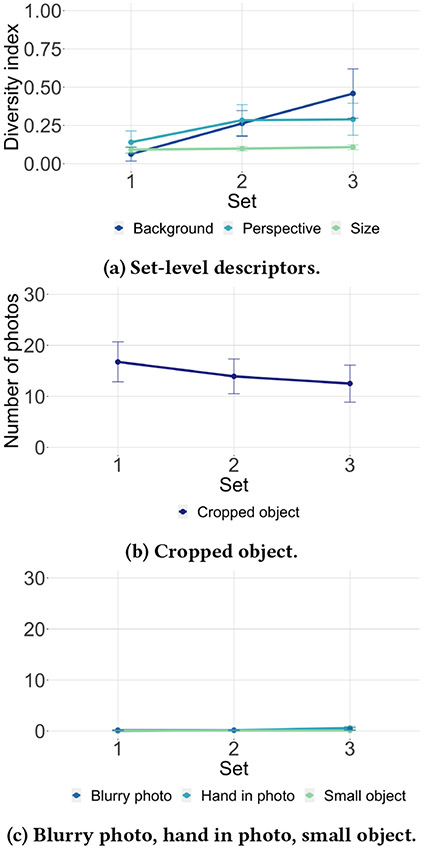
Teachable object recognizers provide a solution for a very practical need for blind people - instance level object recognition. They assume one can visually inspect the photos they provide for training, a critical and inaccessible step for those who are blind. In this work, we engineer data descriptors that address this challenge. They indicate in real time whether the object in the photo is cropped or too small, a hand is included, the photos is blurred, and how much photos vary from each other. Our descriptors are built into open source testbed iOS app, called MYCam. In a remote user study in (N = 12) blind participants' homes, we show how descriptors, even when error-prone, support experimentation and have a positive impact in the quality of training set that can translate to model performance though this gain is not uniform. Participants found the app simple to use indicating that they could effectively train it and that the descriptors were useful. However, many found the training being tedious, opening discussions around the need for balance between information, time, and cognitive load.
Keywords: blind; machine teaching; object recognition; participatory machine learning; visual impairment.
Figures









References
-
- Abdolrahmani Ali, Easley William, Williams Michele, Branham Stacy, and Hurst Amy. 2017. Embracing Errors: Examining How Context of Use Impacts Blind Individuals’ Acceptance of Navigation Aid Errors. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems (Denver, Colorado, USA) (CHI ’17). Association for Computing Machinery, New York, NY, USA, 4158–4169. 10.1145/3025453.3025528 - DOI
-
- Ahmetovic Dragan, Bernareggi Cristian, Gerino Andrea, and Mascetti Sergio. 2014. ZebraRecognizer: Efficient and Precise Localization of Pedestrian Crossings. In 2014 22nd International Conference on Pattern Recognition. 2566–2571. 10.1109/ICPR.2014.443 - DOI
-
- Ahmetovic Dragan, Sato Daisuke, Oh Uran, Ishihara Tatsuya, Kitani Kris, and Asakawa Chieko. 2020. ReCog: Supporting Blind People in Recognizing Personal Objects. Association for Computing Machinery, New York, NY, USA, 1–12. 10.1145/3313831.3376143 - DOI
-
- Aira. 2017. Your Life, Your Schedule, Right Now. https://aira.io
-
- Akter Taslima, Dosono Bryan, Ahmed Tousif, Kapadia Apu, and Semaan Bryan. 2020. "I am uncomfortable sharing what I can’t see": Privacy Concerns of the Visually Impaired with Camera Based Assistive Applications. In 29th USENIX Security Symposium (USENIX Security 20). USENIX Association, 1929–1948. https://www.usenix.org/conference/usenixsecurity20/presentation/akter
Grants and funding
LinkOut - more resources
Full Text Sources