

Multiomic signatures of body mass index identify heterogeneous health phenotypes and responses to a lifestyle intervention
- PMID: 36941332
- PMCID: PMC10115644
- DOI: 10.1038/s41591-023-02248-0
Multiomic signatures of body mass index identify heterogeneous health phenotypes and responses to a lifestyle intervention
Abstract
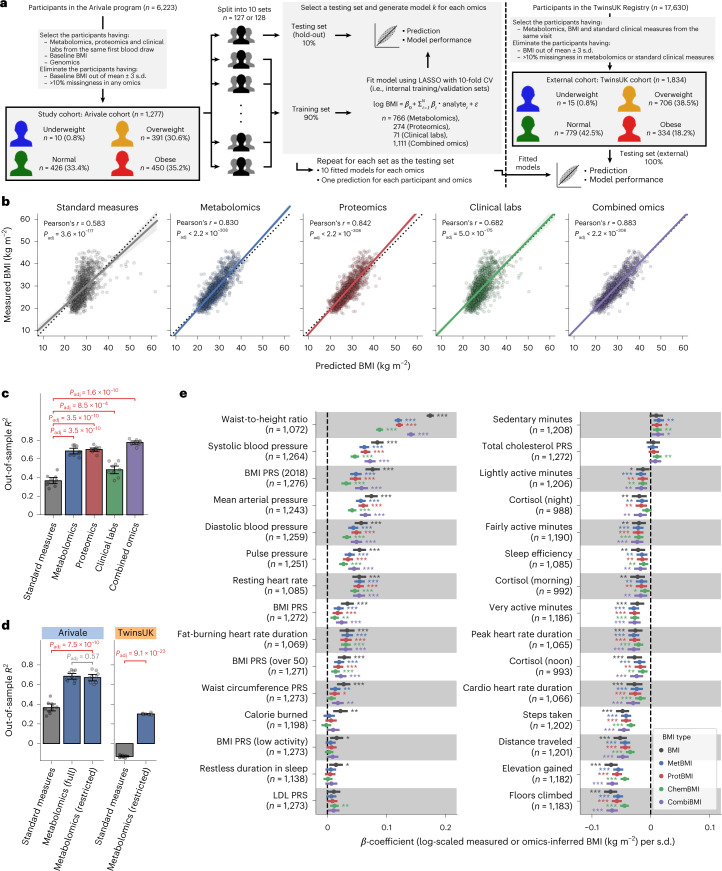
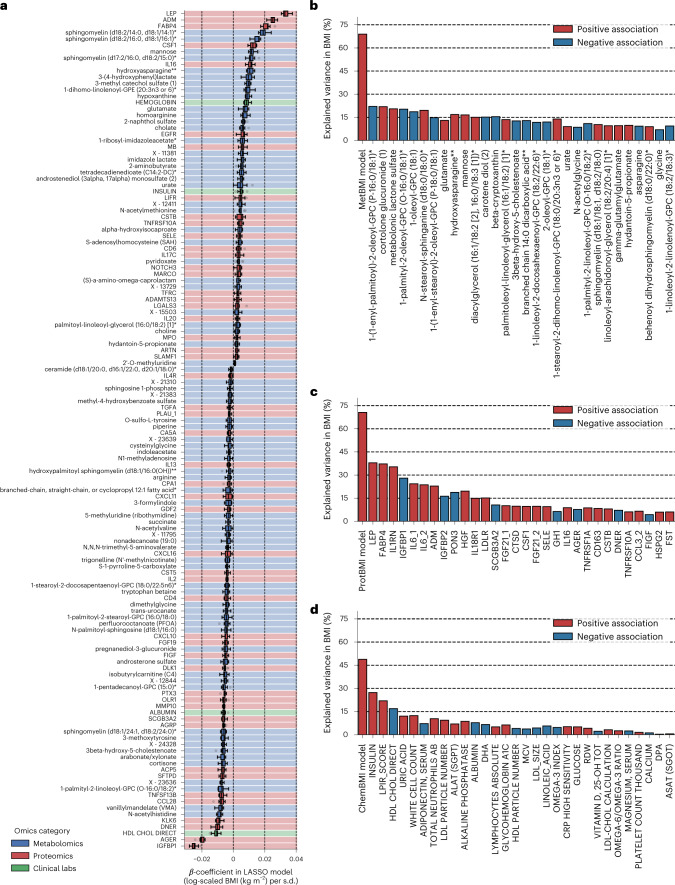
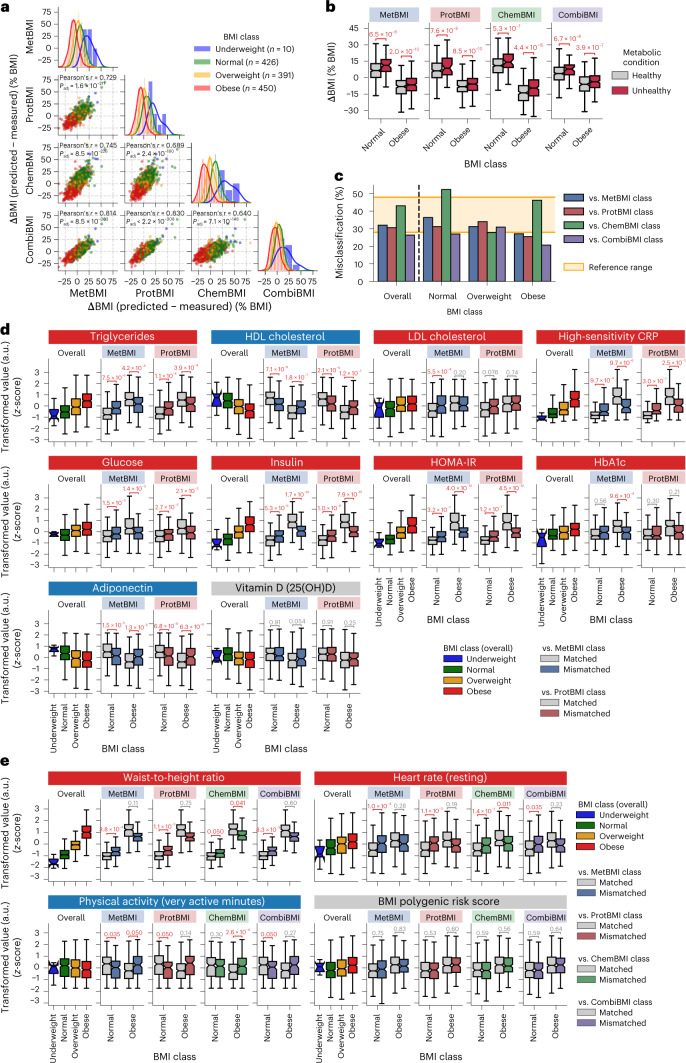
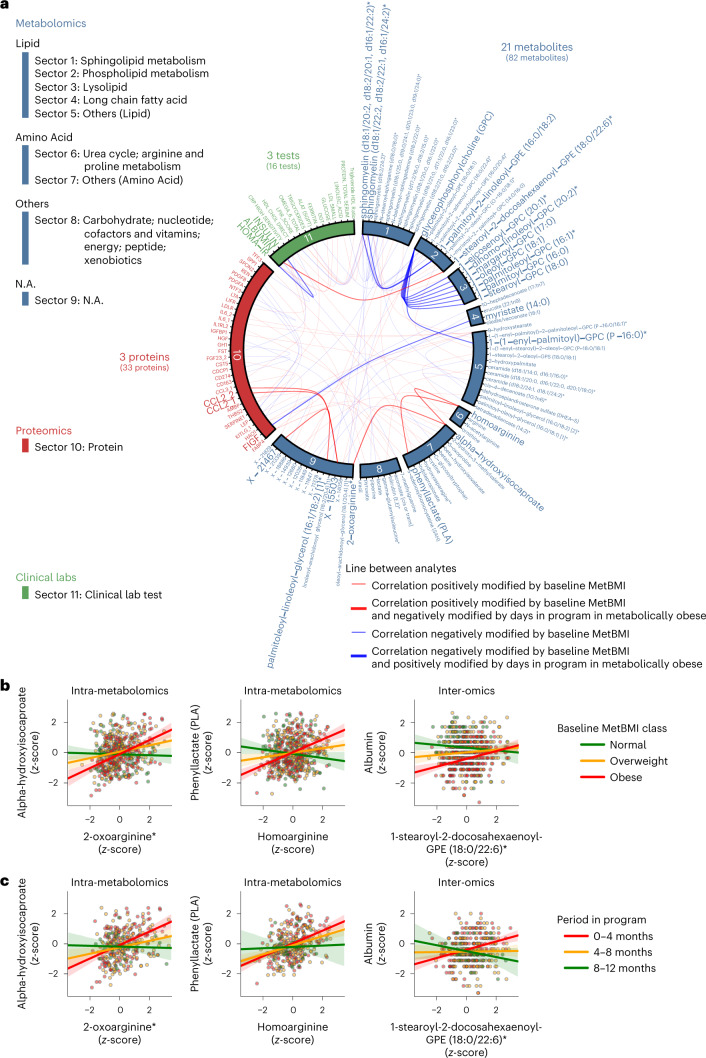
Multiomic profiling can reveal population heterogeneity for both health and disease states. Obesity drives a myriad of metabolic perturbations and is a risk factor for multiple chronic diseases. Here we report an atlas of cross-sectional and longitudinal changes in 1,111 blood analytes associated with variation in body mass index (BMI), as well as multiomic associations with host polygenic risk scores and gut microbiome composition, from a cohort of 1,277 individuals enrolled in a wellness program (Arivale). Machine learning model predictions of BMI from blood multiomics captured heterogeneous phenotypic states of host metabolism and gut microbiome composition better than BMI, which was also validated in an external cohort (TwinsUK). Moreover, longitudinal analyses identified variable BMI trajectories for different omics measures in response to a healthy lifestyle intervention; metabolomics-inferred BMI decreased to a greater extent than actual BMI, whereas proteomics-inferred BMI exhibited greater resistance to change. Our analyses further identified blood analyte-analyte associations that were modified by metabolomics-inferred BMI and partially reversed in individuals with metabolic obesity during the intervention. Taken together, our findings provide a blood atlas of the molecular perturbations associated with changes in obesity status, serving as a resource to quantify metabolic health for predictive and preventive medicine.
© 2023. The Author(s).
Conflict of interest statement
J.J.H. has received grants from Pfizer and Novartis for research unrelated to this study. All other authors declare no competing interests.
Figures










Comment in
-
Biological BMI uncovers hidden health risks and is more responsive to lifestyle shifts.Nat Med. 2023 Apr;29(4):801-802. doi: 10.1038/s41591-023-02283-x. Nat Med. 2023. PMID: 37041385 No abstract available.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
