

A self-adaptive hardware with resistive switching synapses for experience-based neurocomputing
- PMID: 36944647
- PMCID: PMC10030830
- DOI: 10.1038/s41467-023-37097-5
A self-adaptive hardware with resistive switching synapses for experience-based neurocomputing
Abstract
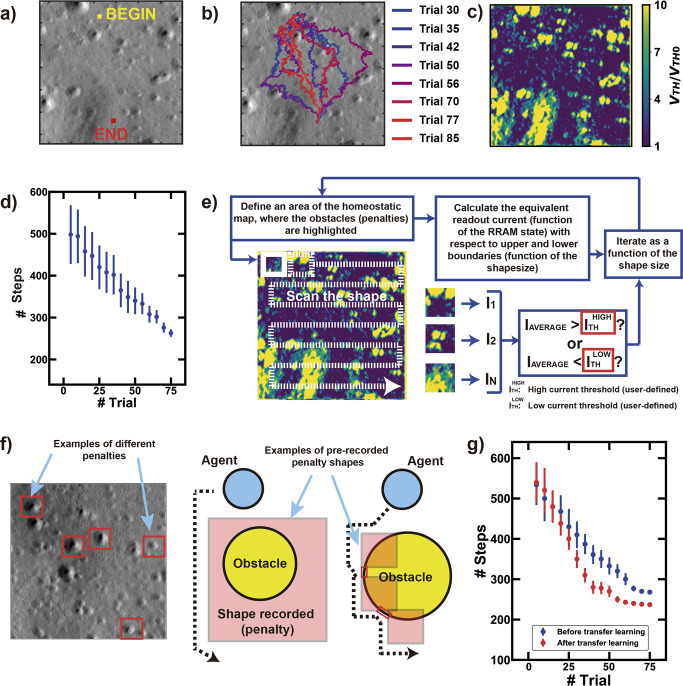
Neurobiological systems continually interact with the surrounding environment to refine their behaviour toward the best possible reward. Achieving such learning by experience is one of the main challenges of artificial intelligence, but currently it is hindered by the lack of hardware capable of plastic adaptation. Here, we propose a bio-inspired recurrent neural network, mastered by a digital system on chip with resistive-switching synaptic arrays of memory devices, which exploits homeostatic Hebbian learning for improved efficiency. All the results are discussed experimentally and theoretically, proposing a conceptual framework for benchmarking the main outcomes in terms of accuracy and resilience. To test the proposed architecture for reinforcement learning tasks, we study the autonomous exploration of continually evolving environments and verify the results for the Mars rover navigation. We also show that, compared to conventional deep learning techniques, our in-memory hardware has the potential to achieve a significant boost in speed and power-saving.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
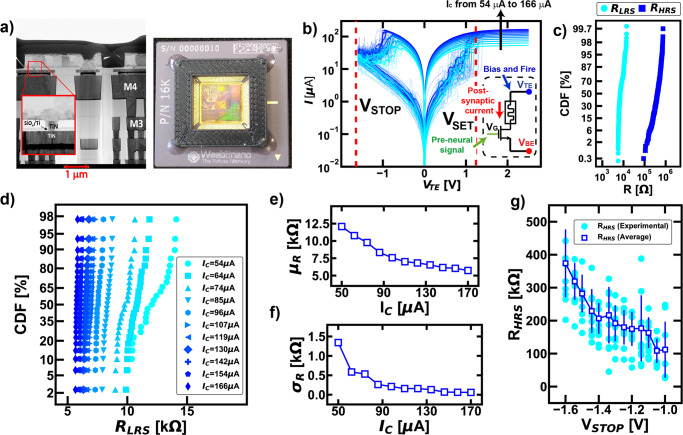
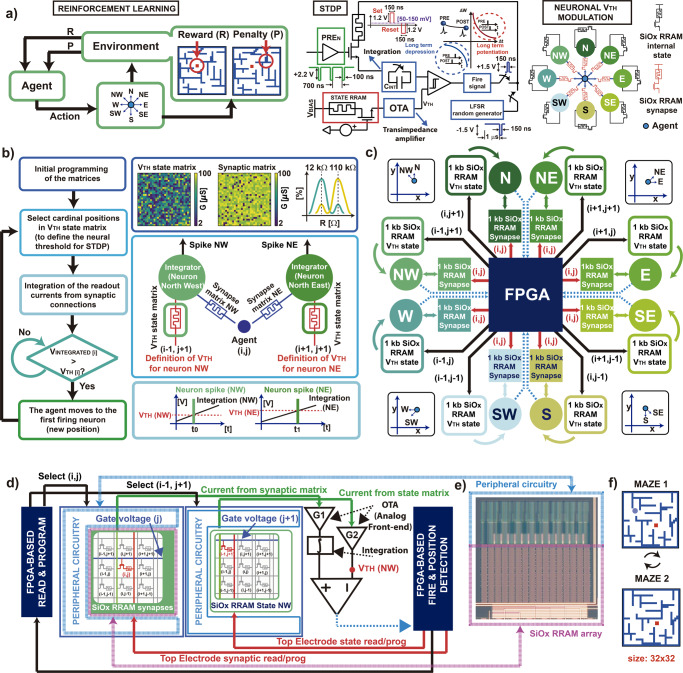
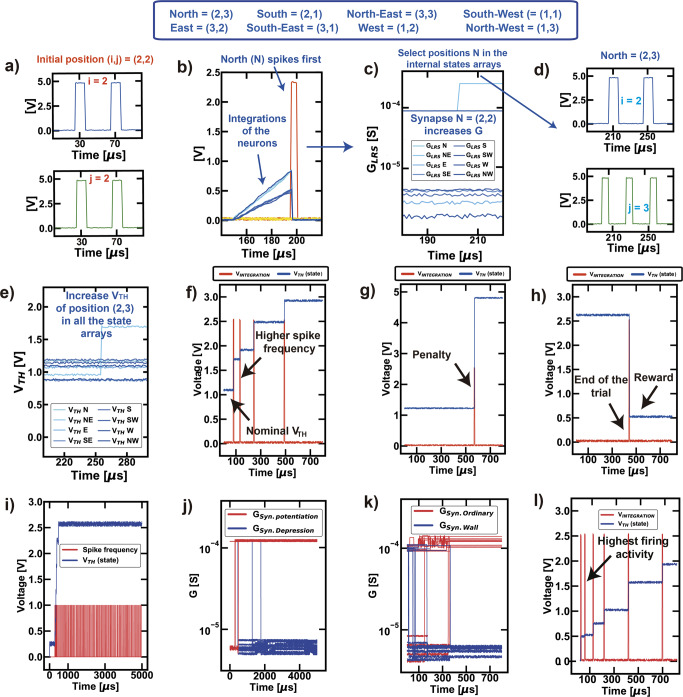
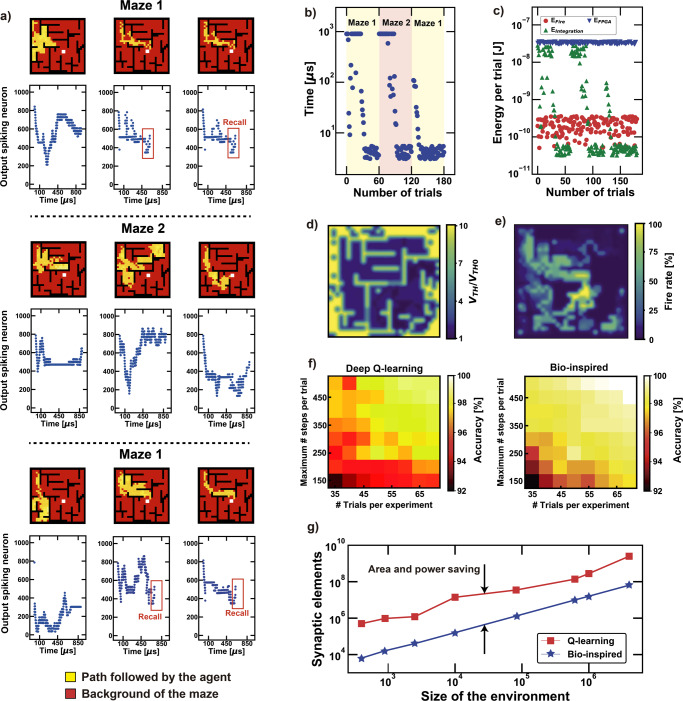
References
-
- Folke C, et al. Resilience thinking: integrating resilience, adaptability and transformability. Ecol. Soc. 2010;15:20. doi: 10.5751/ES-03610-150420. - DOI
-
- Kaelbling LP, Littman ML, Moore AW. Reinforcement learning: a survey. J. Artif. Intell. Res. 1996;4:237–285. doi: 10.1613/jair.301. - DOI
-
- Sutton RS. Learning to predict by the methods of temporal differences. Mach. Learn. 1988;3:9–44. doi: 10.1007/BF00115009. - DOI
LinkOut - more resources
Full Text Sources
Miscellaneous
