

Generalizable biomarker prediction from cancer pathology slides with self-supervised deep learning: A retrospective multi-centric study
- PMID: 36958327
- PMCID: PMC10140458
- DOI: 10.1016/j.xcrm.2023.100980
Generalizable biomarker prediction from cancer pathology slides with self-supervised deep learning: A retrospective multi-centric study
Abstract
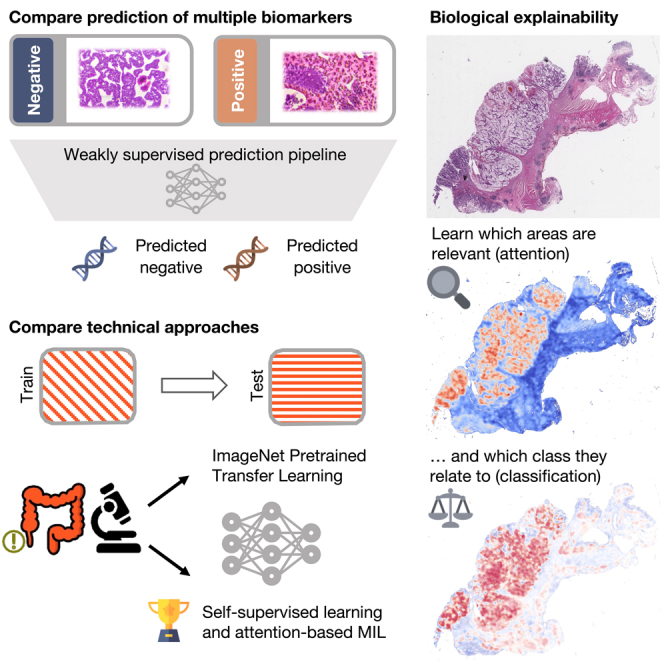
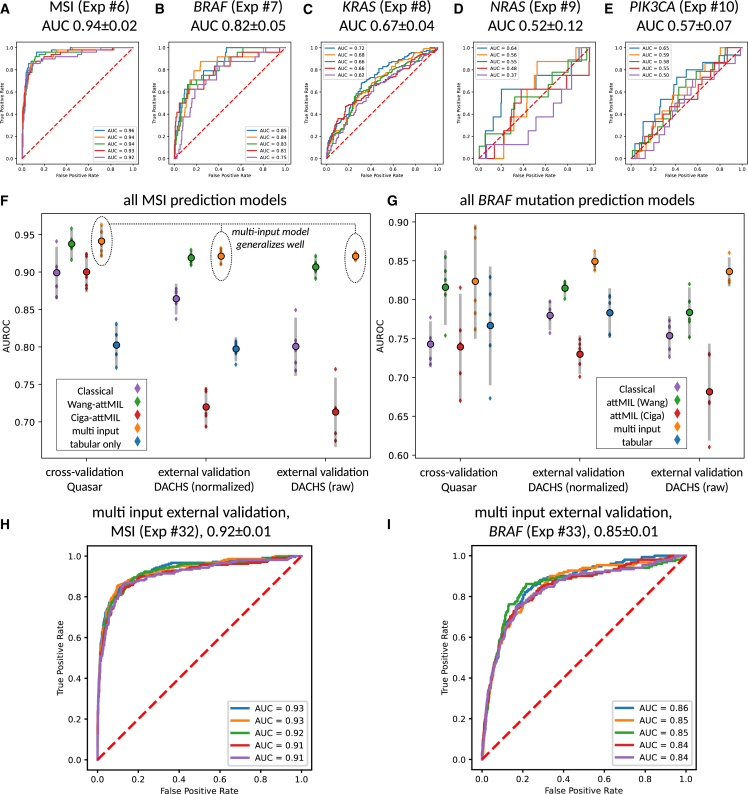
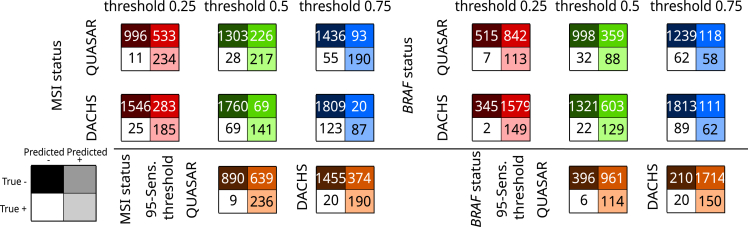
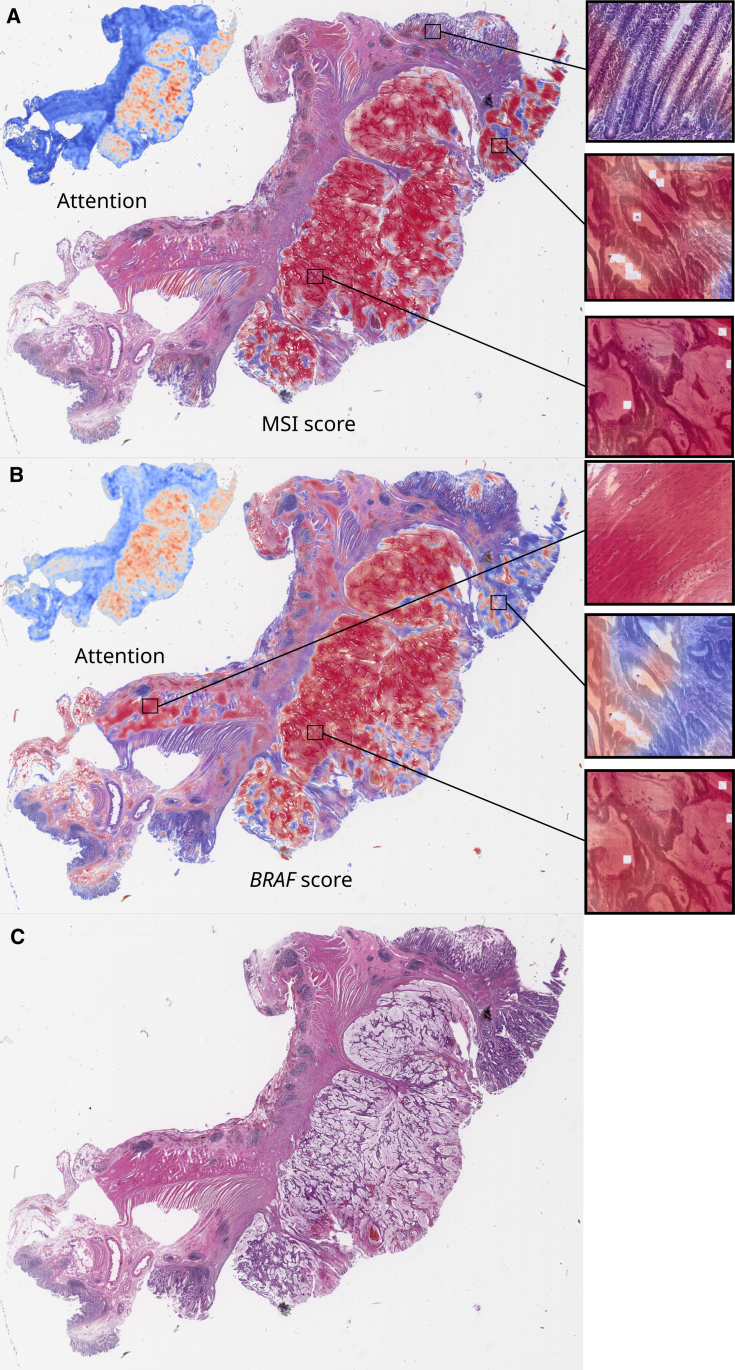
Deep learning (DL) can predict microsatellite instability (MSI) from routine histopathology slides of colorectal cancer (CRC). However, it is unclear whether DL can also predict other biomarkers with high performance and whether DL predictions generalize to external patient populations. Here, we acquire CRC tissue samples from two large multi-centric studies. We systematically compare six different state-of-the-art DL architectures to predict biomarkers from pathology slides, including MSI and mutations in BRAF, KRAS, NRAS, and PIK3CA. Using a large external validation cohort to provide a realistic evaluation setting, we show that models using self-supervised, attention-based multiple-instance learning consistently outperform previous approaches while offering explainable visualizations of the indicative regions and morphologies. While the prediction of MSI and BRAF mutations reaches a clinical-grade performance, mutation prediction of PIK3CA, KRAS, and NRAS was clinically insufficient.
Keywords: artificial intelligence; attention heatmaps; attention-based multiple-instance learning; biomarker; colorectal cancer; computational pathology; multi-input models; oncogenic mutation; self-supervised learning.
Copyright © 2023 The Author(s). Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests For transparency, we provide the following information: J.N.K. declares consulting services for Owkin, France; Panakeia, UK; and DoMore Diagnostics, Norway. P.Q. and N.P.W. declare research funding from Roche and PQ consulting and speaker services for Roche. P.Q. is a National Institute of Health Research senior investigator.
Figures


References
-
- Heinz C.N., Echle A., Foersch S., Bychkov A., Kather J.N. The future of artificial intelligence in digital pathology - results of a survey across stakeholder groups. Histopathology. 2022;80:1121–1127. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Medical
Research Materials
Miscellaneous
