

Artificial-intelligence-based molecular classification of diffuse gliomas using rapid, label-free optical imaging
- PMID: 36959422
- PMCID: PMC10445531
- DOI: 10.1038/s41591-023-02252-4
Artificial-intelligence-based molecular classification of diffuse gliomas using rapid, label-free optical imaging
Abstract
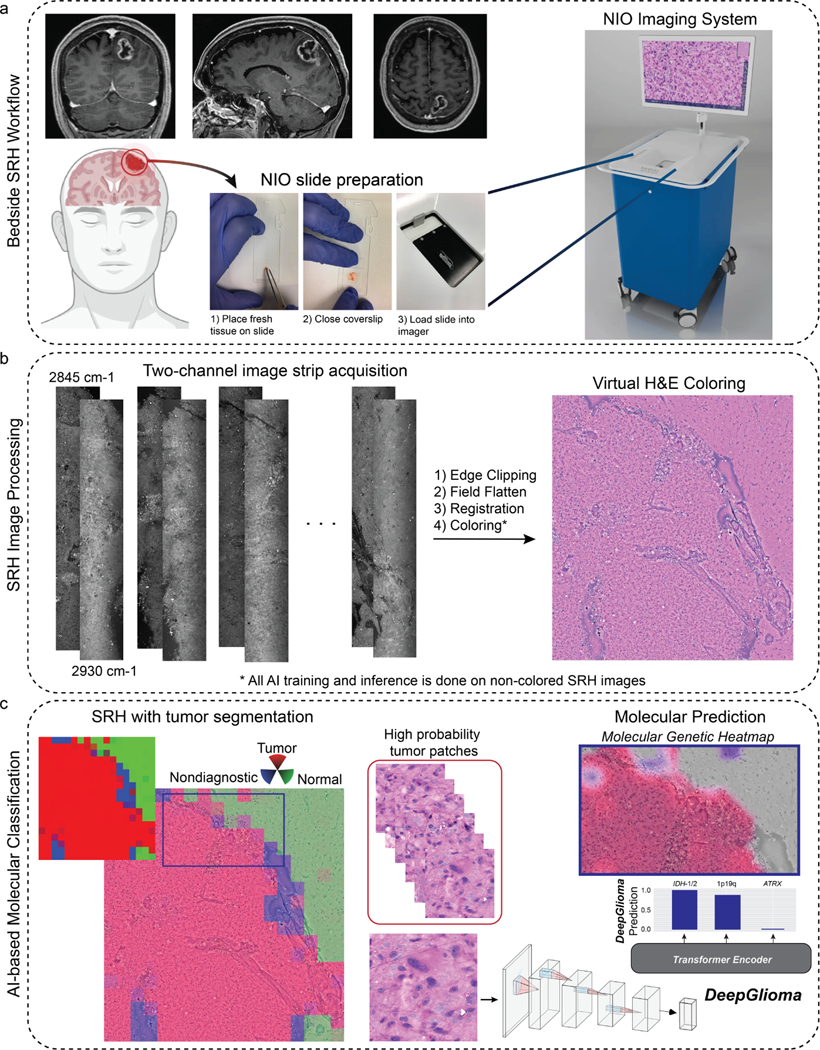
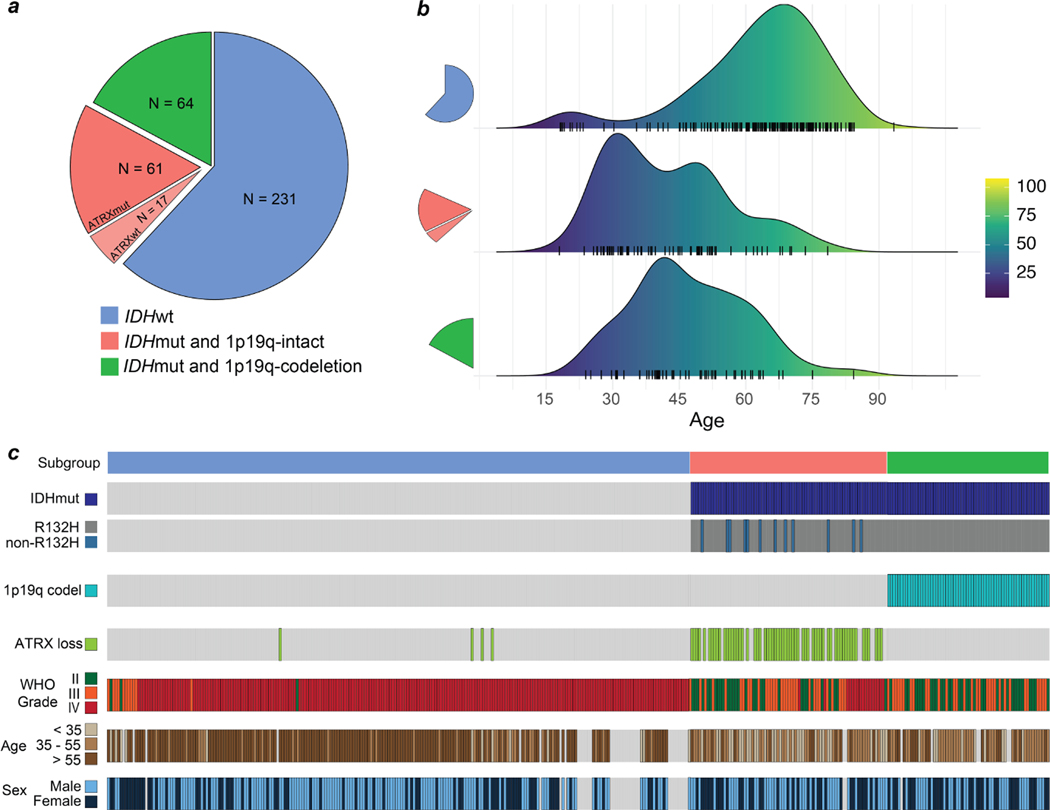
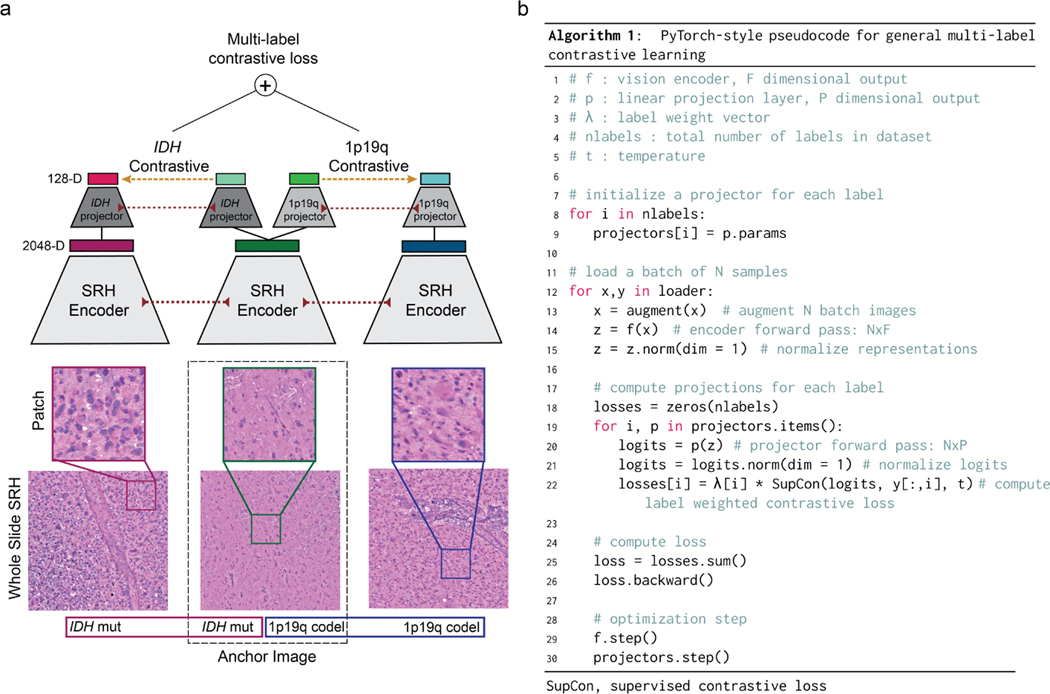
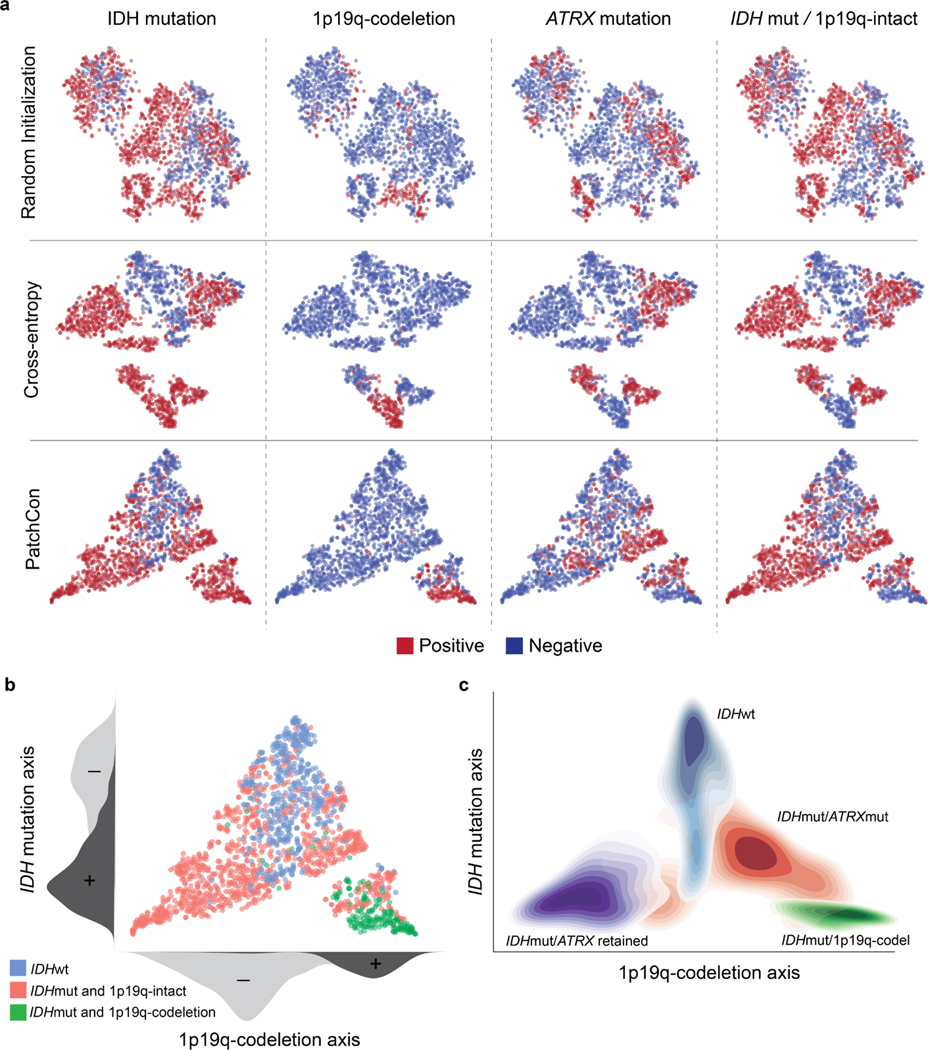
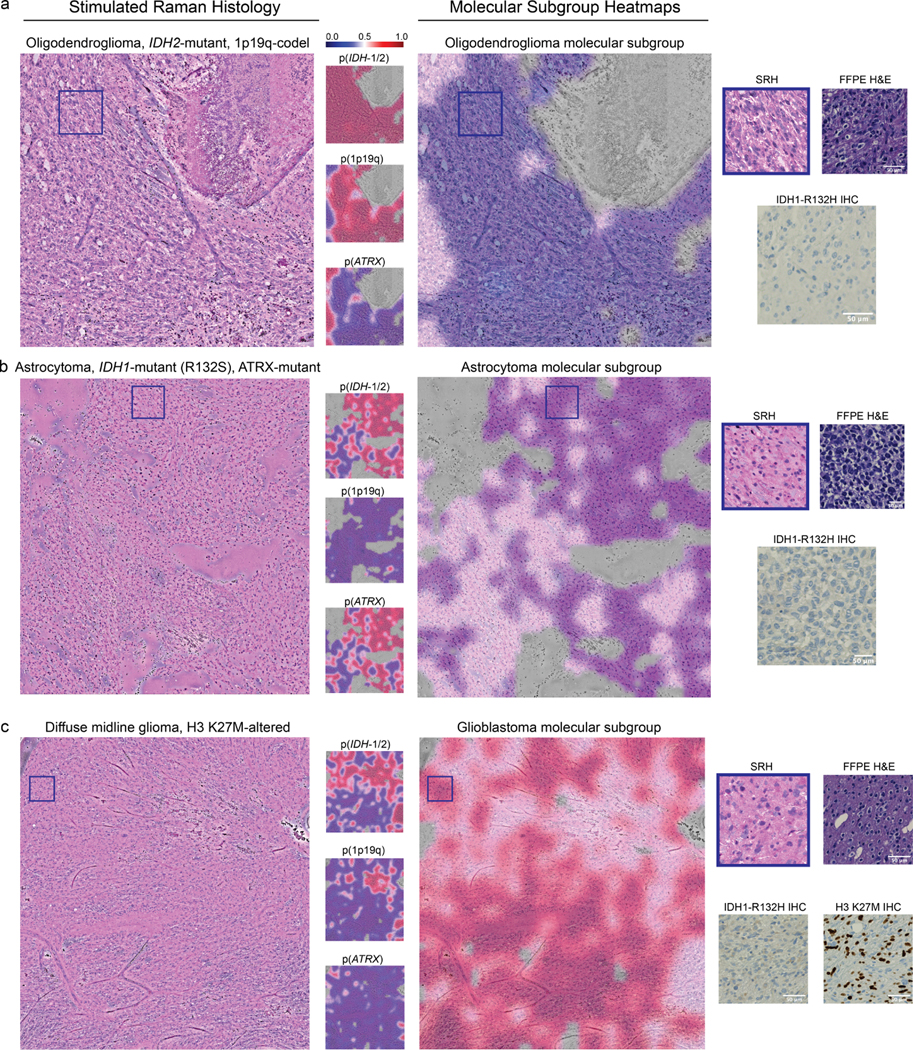
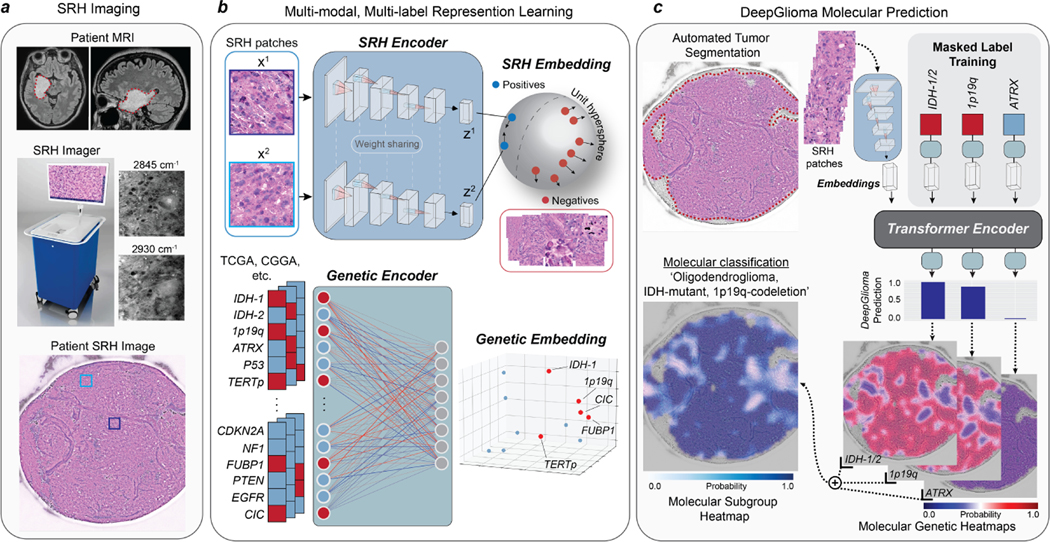
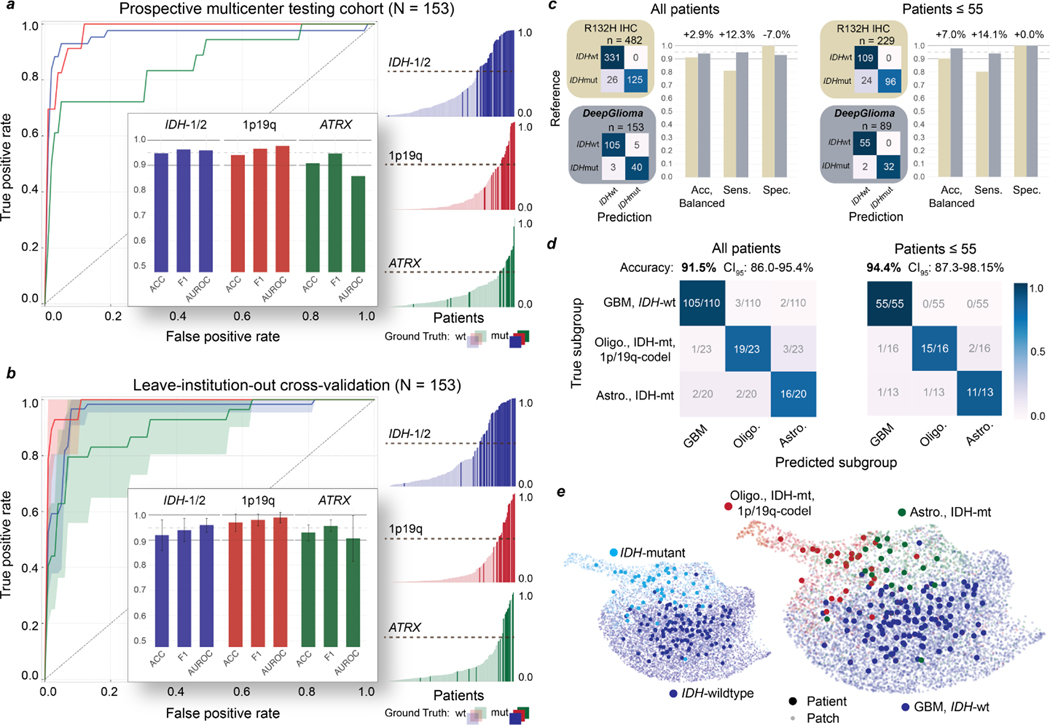
Molecular classification has transformed the management of brain tumors by enabling more accurate prognostication and personalized treatment. However, timely molecular diagnostic testing for patients with brain tumors is limited, complicating surgical and adjuvant treatment and obstructing clinical trial enrollment. In this study, we developed DeepGlioma, a rapid (<90 seconds), artificial-intelligence-based diagnostic screening system to streamline the molecular diagnosis of diffuse gliomas. DeepGlioma is trained using a multimodal dataset that includes stimulated Raman histology (SRH); a rapid, label-free, non-consumptive, optical imaging method; and large-scale, public genomic data. In a prospective, multicenter, international testing cohort of patients with diffuse glioma (n = 153) who underwent real-time SRH imaging, we demonstrate that DeepGlioma can predict the molecular alterations used by the World Health Organization to define the adult-type diffuse glioma taxonomy (IDH mutation, 1p19q co-deletion and ATRX mutation), achieving a mean molecular classification accuracy of 93.3 ± 1.6%. Our results represent how artificial intelligence and optical histology can be used to provide a rapid and scalable adjunct to wet lab methods for the molecular screening of patients with diffuse glioma.
© 2023. The Author(s), under exclusive licence to Springer Nature America, Inc.
Figures
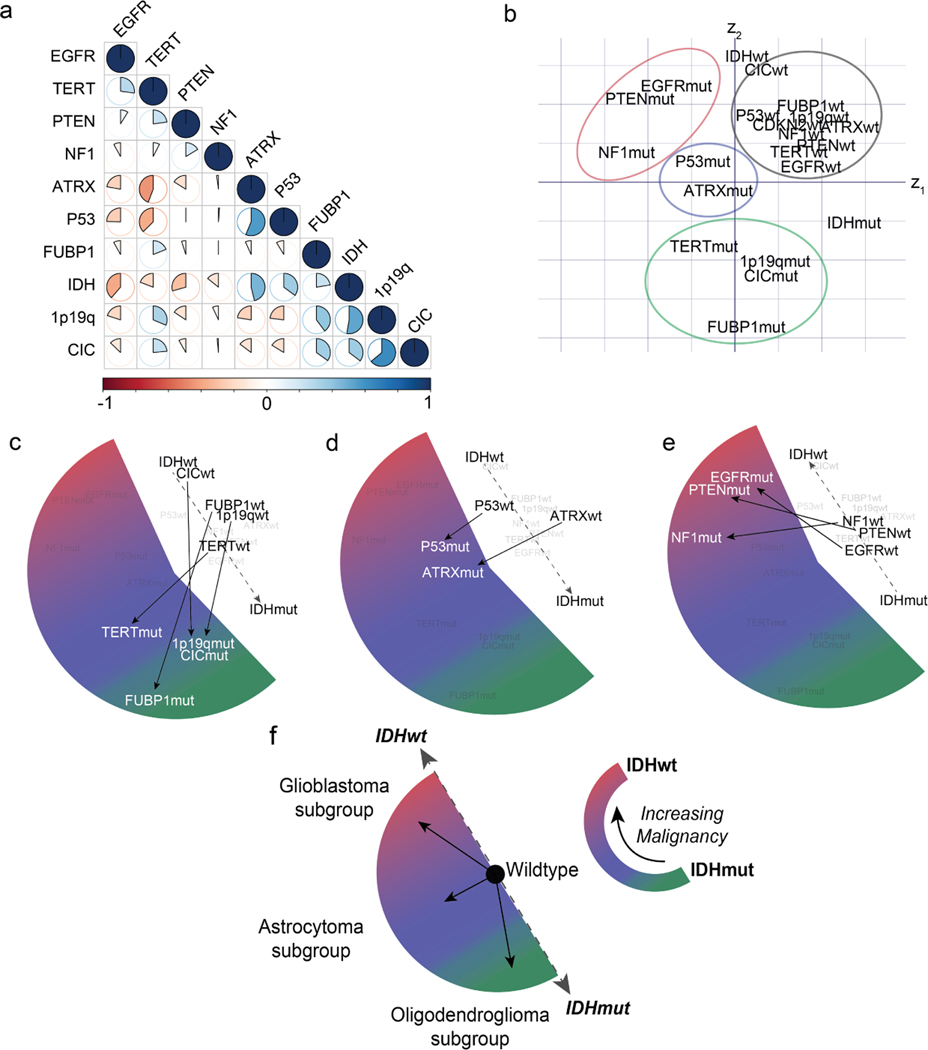

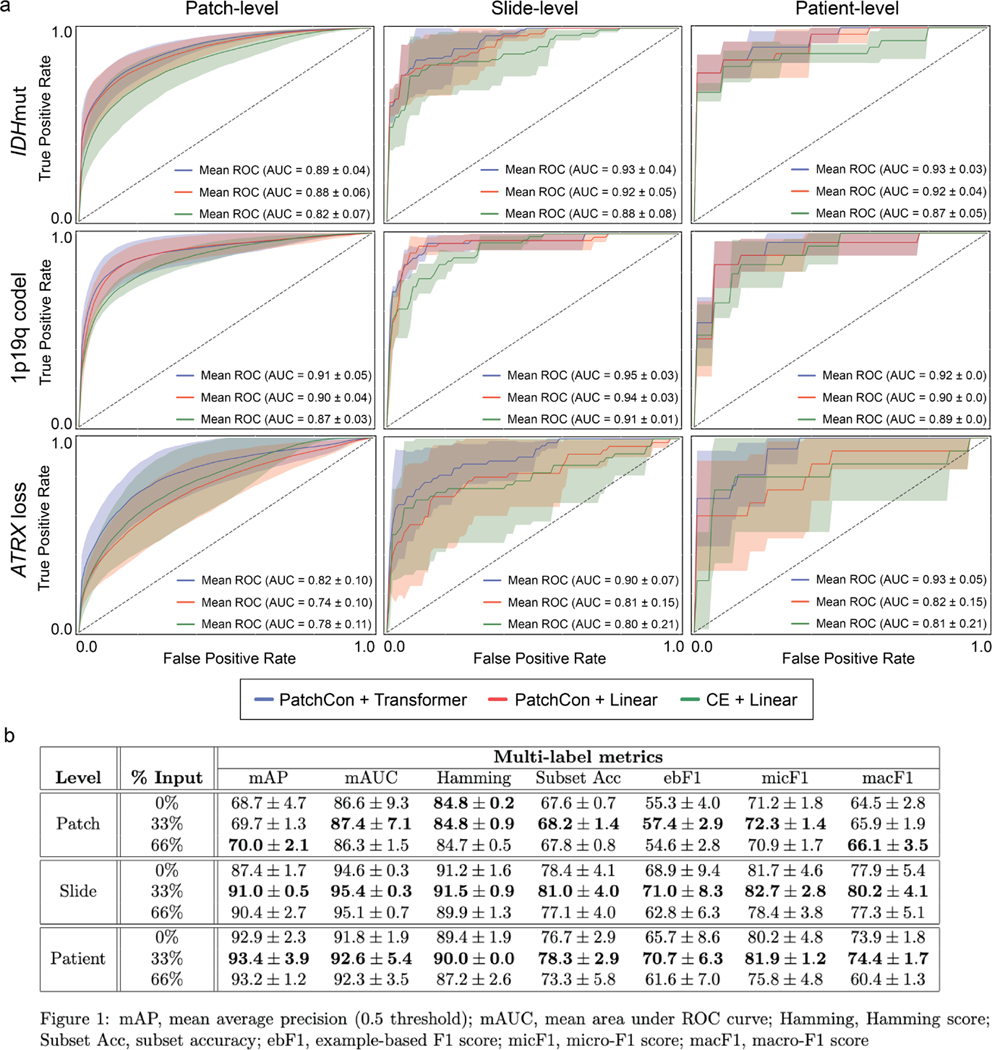
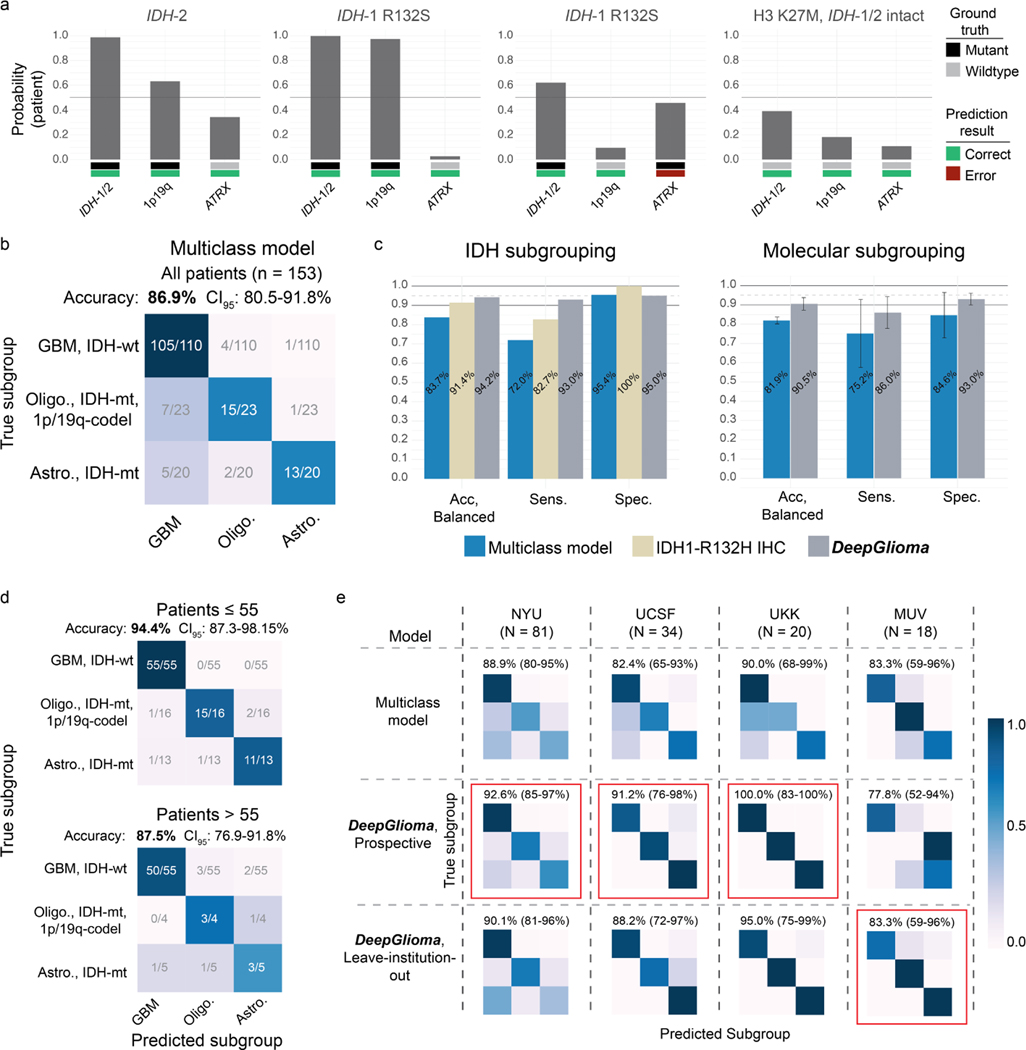
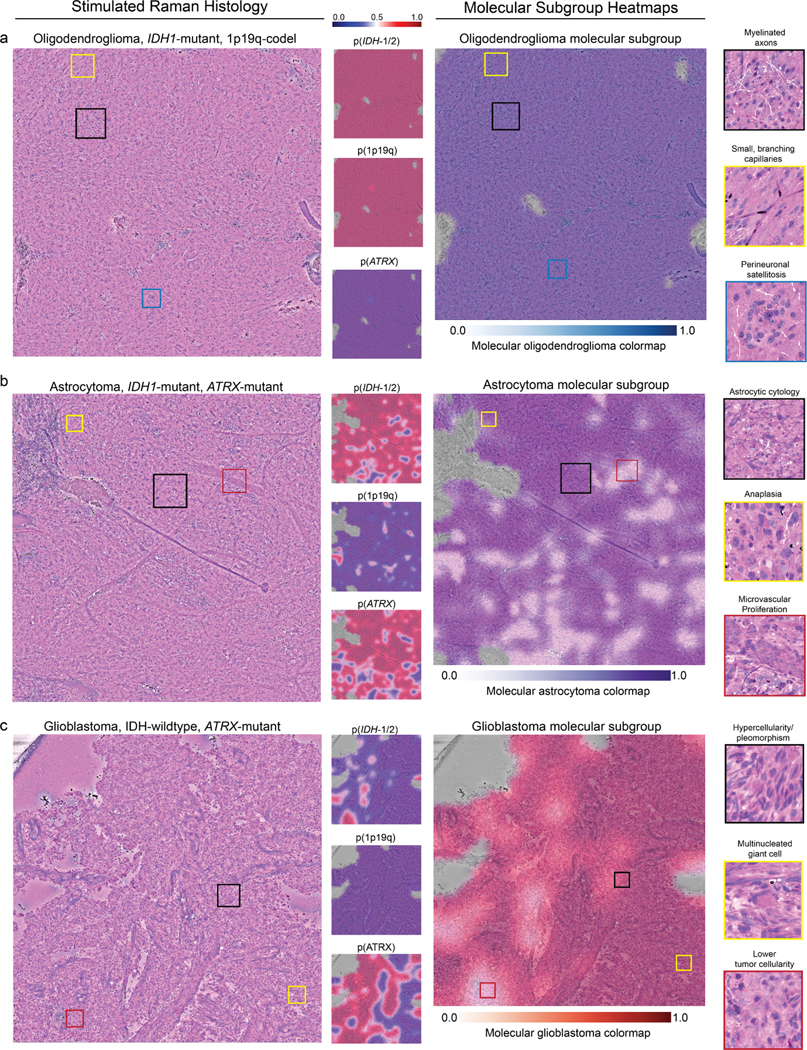
Comment in
-
Using AI to improve the molecular classification of brain tumors.Nat Med. 2023 Apr;29(4):793-794. doi: 10.1038/s41591-023-02298-4. Nat Med. 2023. PMID: 37041386 No abstract available.
References
-
- Sullivan R et al. Global cancer surgery: delivering safe, affordable, and timely cancer surgery. Lancet Oncol. 16 (11), 1193–1224 (2015). - PubMed
-
- Cheah P-L, Looi LM & Horton S Cost analysis of operating an anatomic pathology laboratory in a Middle-Income country. Am. J. Clin. Pathol. 149 (1), 1–7 (2018). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
