

The Type 2 Diabetes Knowledge Portal: An open access genetic resource dedicated to type 2 diabetes and related traits
- PMID: 36963395
- PMCID: PMC10231654
- DOI: 10.1016/j.cmet.2023.03.001
The Type 2 Diabetes Knowledge Portal: An open access genetic resource dedicated to type 2 diabetes and related traits
Abstract
Associations between human genetic variation and clinical phenotypes have become a foundation of biomedical research. Most repositories of these data seek to be disease-agnostic and therefore lack disease-focused views. The Type 2 Diabetes Knowledge Portal (T2DKP) is a public resource of genetic datasets and genomic annotations dedicated to type 2 diabetes (T2D) and related traits. Here, we seek to make the T2DKP more accessible to prospective users and more useful to existing users. First, we evaluate the T2DKP's comprehensiveness by comparing its datasets with those of other repositories. Second, we describe how researchers unfamiliar with human genetic data can begin using and correctly interpreting them via the T2DKP. Third, we describe how existing users can extend their current workflows to use the full suite of tools offered by the T2DKP. We finally discuss the lessons offered by the T2DKP toward the goal of democratizing access to complex disease genetic results.
Keywords: CMDKP; GWAS; T2DKP; data sharing; diabetes; effector genes; genetic associations; genetic support; genomics; portal.
Copyright © 2023 The Author(s). Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests A.C. is a Sanofi employee and holds shares and stock options in the company. M.I.M. has served on advisory panels for Pfizer, Novo Nordisk, and Zoe Global; has received honoraria from Merck, Pfizer, Novo Nordisk, and Eli Lilly; and received research funding from Abbvie, Astra Zeneca, Boehringer Ingelheim, Eli Lilly, Janssen, Merck, Novo Nordisk, Pfizer, Roche, Sanofi Aventis, Servier, and Takeda. As of June 2019, M.I.M. is an employee of Genentech and a holder of Roche stock. M.R.M. is a Pfizer employee and holds shares of stock in the company. M.K.T. is an employee and shareholder of Eli Lilly and Company. As of April 2022, P.D. is an employee and stockholder of Regeneron Pharmaceuticals.
Figures
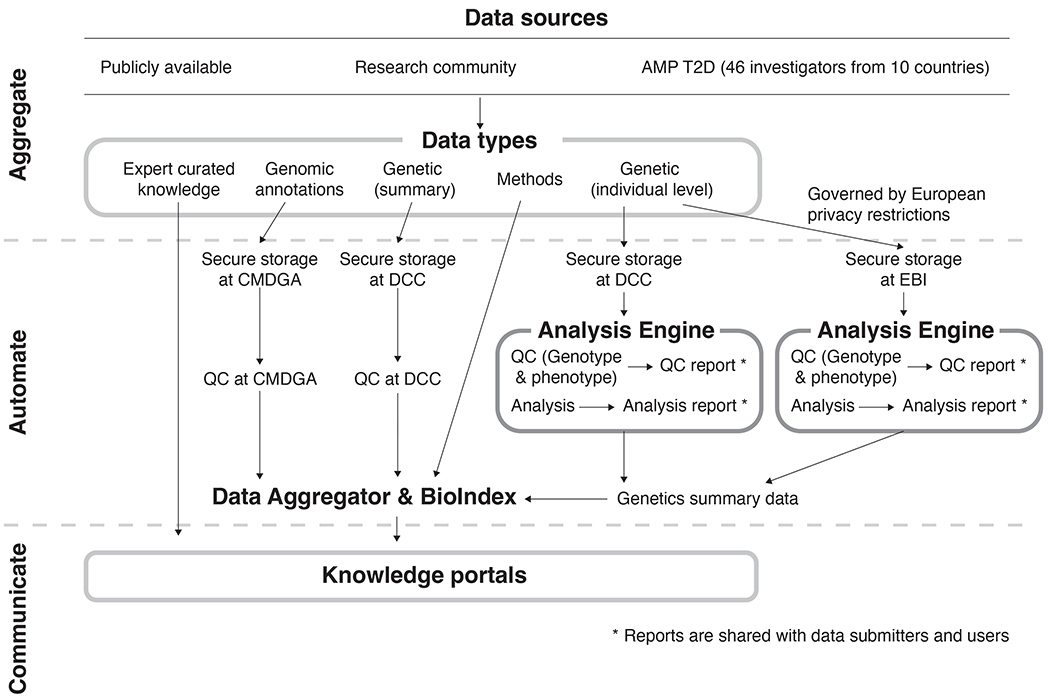
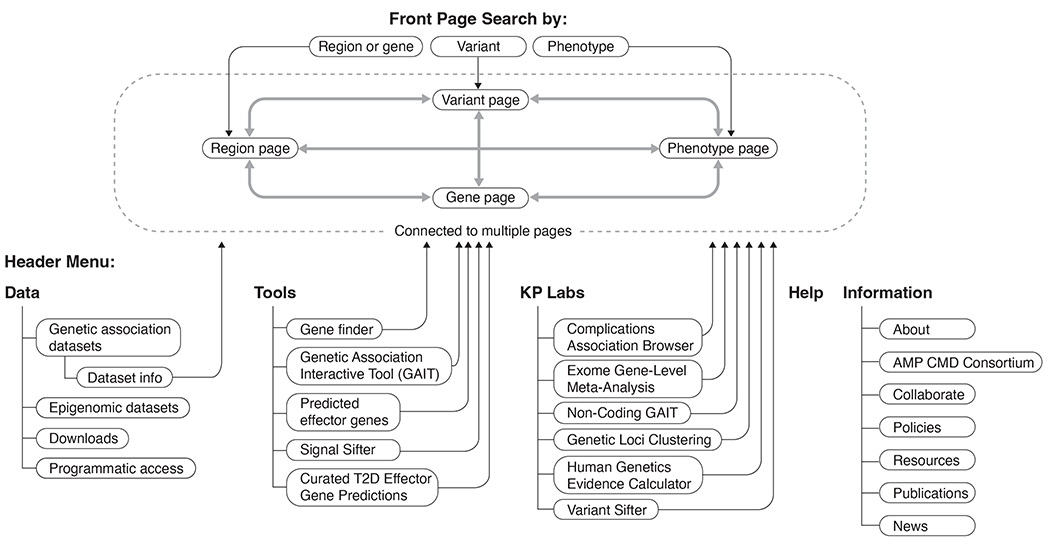
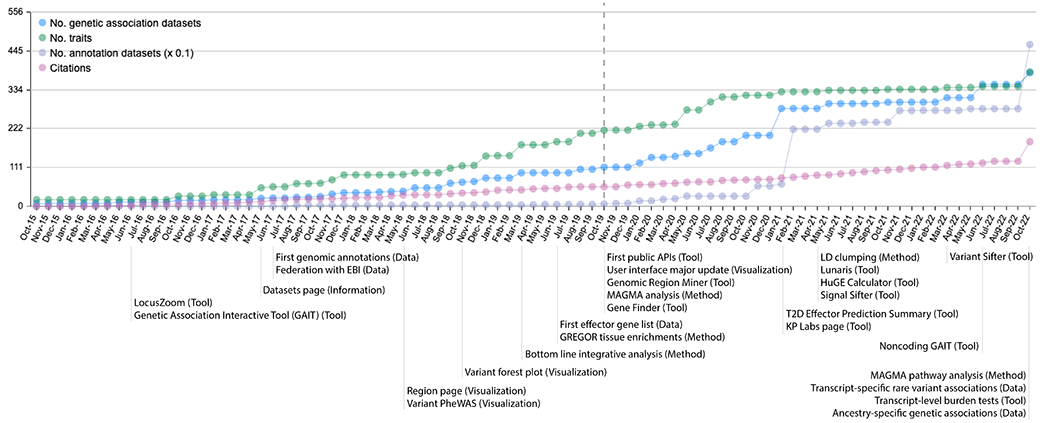
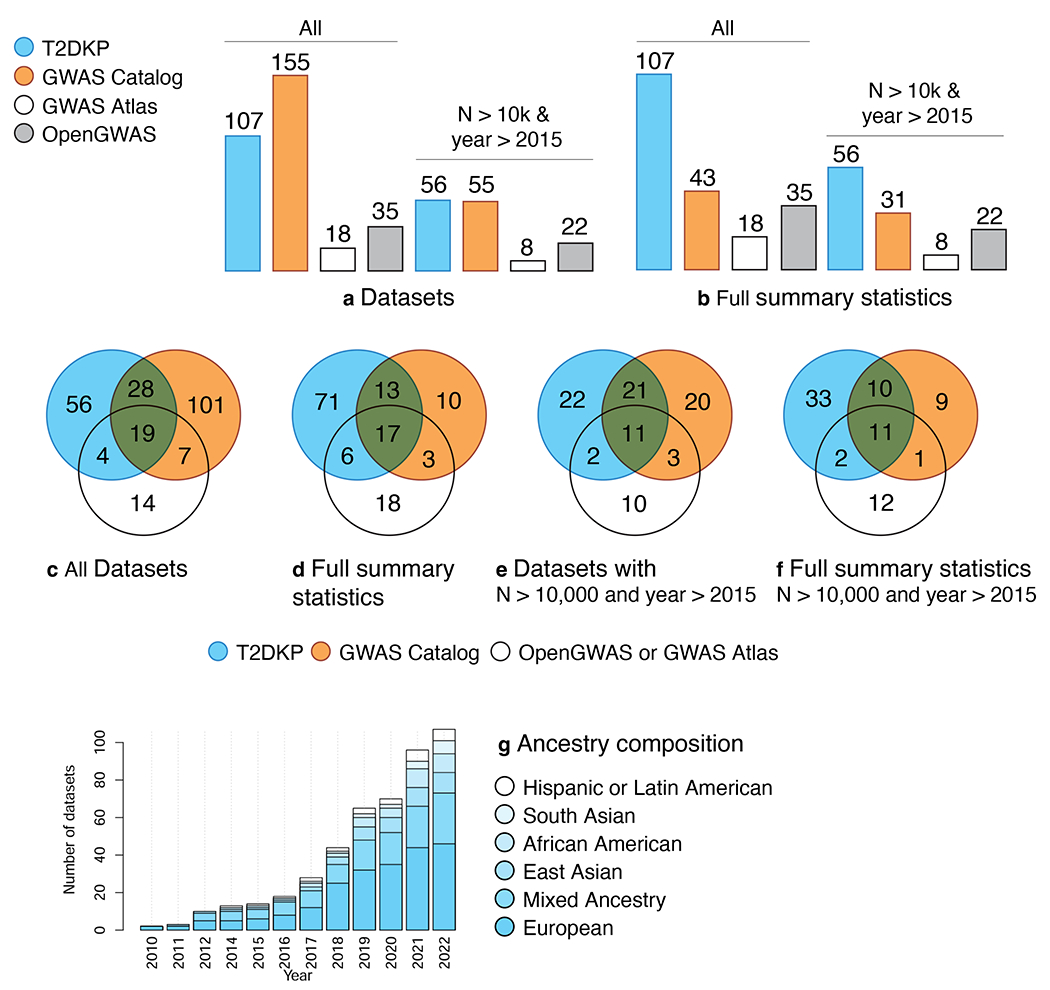
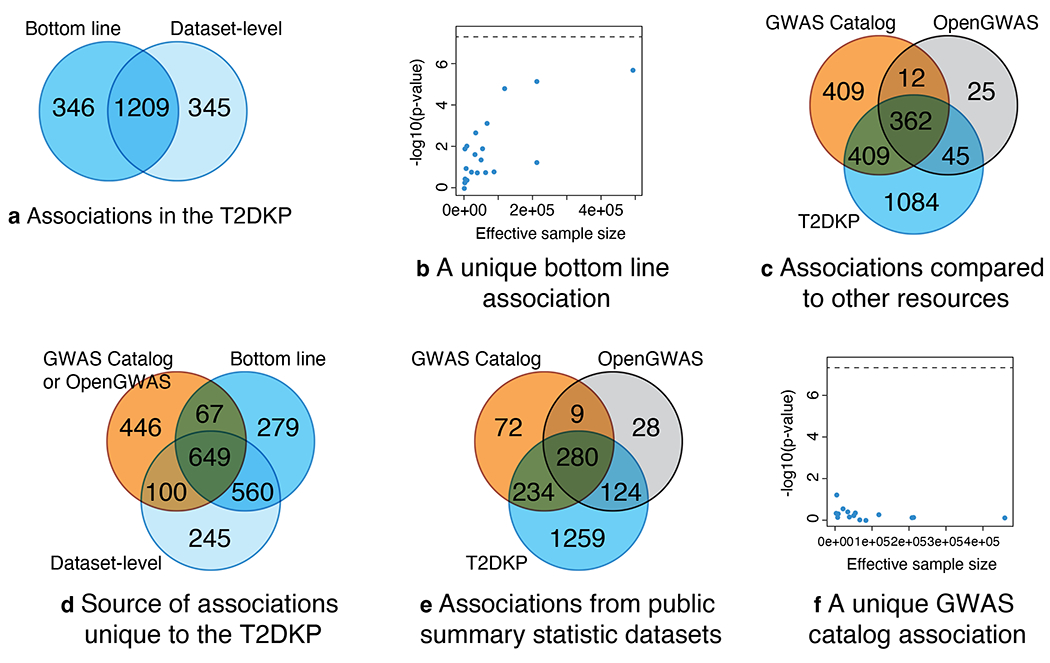
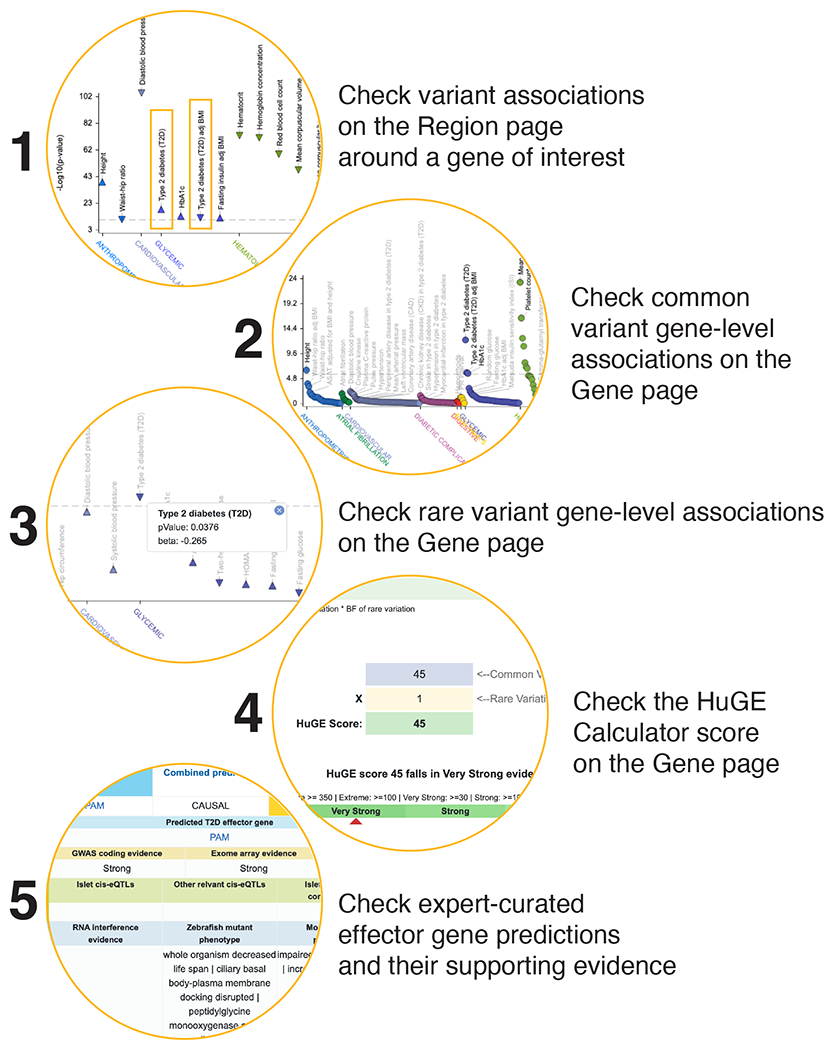

References
-
- King EA, Davis JW, and Degner JF (2019). Are drug targets with genetic support twice as likely to be approved? Revised estimates of the impact of genetic support for drug mechanisms on the probability of drug approval.: Supplementary Methods And Results (Genetics) 10.1101/513945. - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
- K23 DK114551/DK/NIDDK NIH HHS/United States
- R01 DK087635/DK/NIDDK NIH HHS/United States
- R01 DK132630/DK/NIDDK NIH HHS/United States
- R01 DK076077/DK/NIDDK NIH HHS/United States
- R01 DK125490/DK/NIDDK NIH HHS/United States
- P50 DK064236/DK/NIDDK NIH HHS/United States
- UM1 DK105554/DK/NIDDK NIH HHS/United States
- DP3 DK108220/DK/NIDDK NIH HHS/United States
- R01 DK062370/DK/NIDDK NIH HHS/United States
- U01 DK105535/DK/NIDDK NIH HHS/United States
- U01 HG011723/HG/NHGRI NIH HHS/United States
- R01 HG009976/HG/NHGRI NIH HHS/United States
- P30 DK020572/DK/NIDDK NIH HHS/United States
- WT_/Wellcome Trust/United Kingdom
