

Functionally distinct BMP1 isoforms show an opposite pattern of abundance in plasma from non-small cell lung cancer subjects and controls
- PMID: 36989217
- PMCID: PMC10058078
- DOI: 10.1371/journal.pone.0282821
Functionally distinct BMP1 isoforms show an opposite pattern of abundance in plasma from non-small cell lung cancer subjects and controls
Abstract
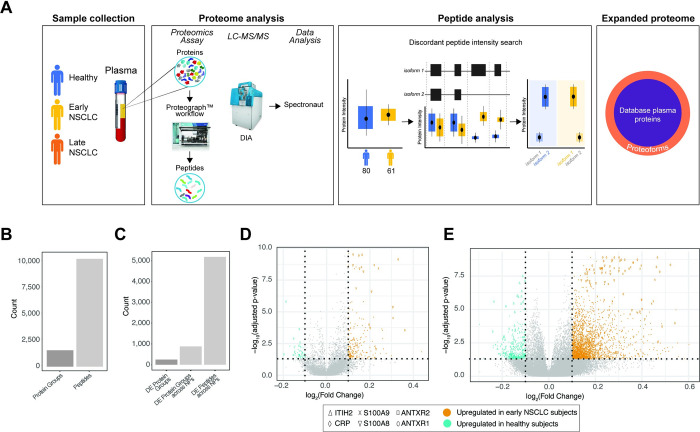
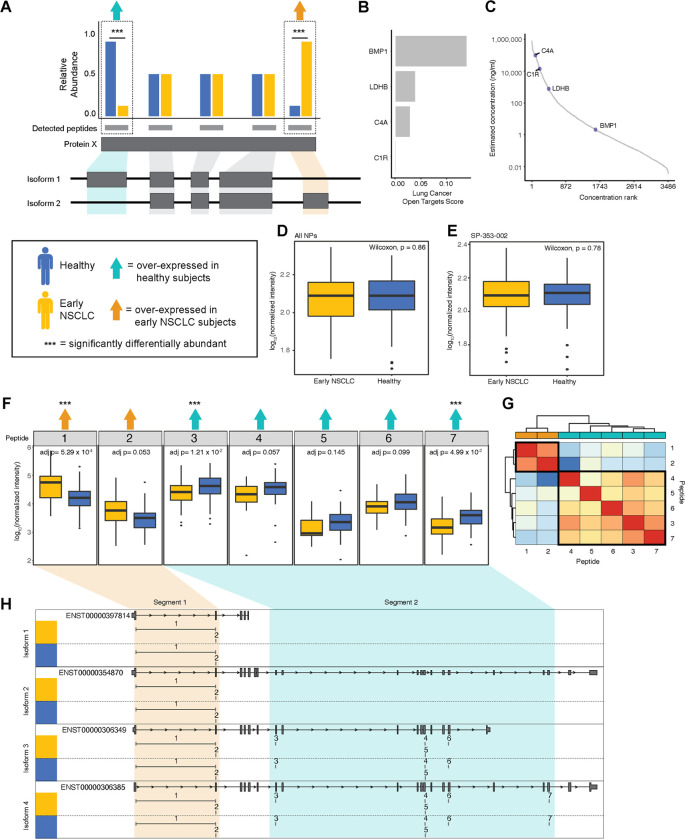
Advancements in deep plasma proteomics are enabling high-resolution measurement of plasma proteoforms, which may reveal a rich source of novel biomarkers previously concealed by aggregated protein methods. Here, we analyze 188 plasma proteomes from non-small cell lung cancer subjects (NSCLC) and controls to identify NSCLC-associated protein isoforms by examining differentially abundant peptides as a proxy for isoform-specific exon usage. We find four proteins comprised of peptides with opposite patterns of abundance between cancer and control subjects. One of these proteins, BMP1, has known isoforms that can explain this differential pattern, for which the abundance of the NSCLC-associated isoform increases with stage of NSCLC progression. The presence of cancer and control-associated isoforms suggests differential regulation of BMP1 isoforms. The identified BMP1 isoforms have known functional differences, which may reveal insights into mechanisms impacting NSCLC disease progression.
Copyright: © 2023 Donovan et al. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Conflict of interest statement
OCF. has financial interest in Selecta Biosciences, Tarveda Therapeutics, and Seer. MKRD, YH, JEB, JW, DH, SF, IM, SK, MK, RWB, TLP, SB, OCF, and AS have financial interest in Seer. LAD is a member of Seer’s Scientific Advisor Board and is financially compensated for that role. Only Seer, and no other companies mentioned here, was involved in the study design, data collection and analysis, and manuscript writing/editing. This does not alter our adherence to PLOS ONE policies on sharing data and materials.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
