

The CANDOR corpus: Insights from a large multimodal dataset of naturalistic conversation
- PMID: 37000886
- PMCID: PMC10065445
- DOI: 10.1126/sciadv.adf3197
The CANDOR corpus: Insights from a large multimodal dataset of naturalistic conversation
Abstract
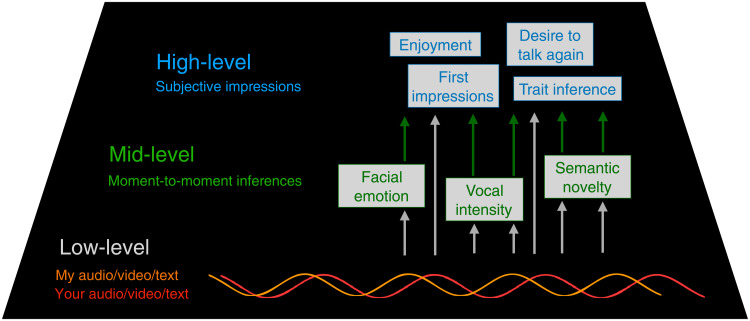
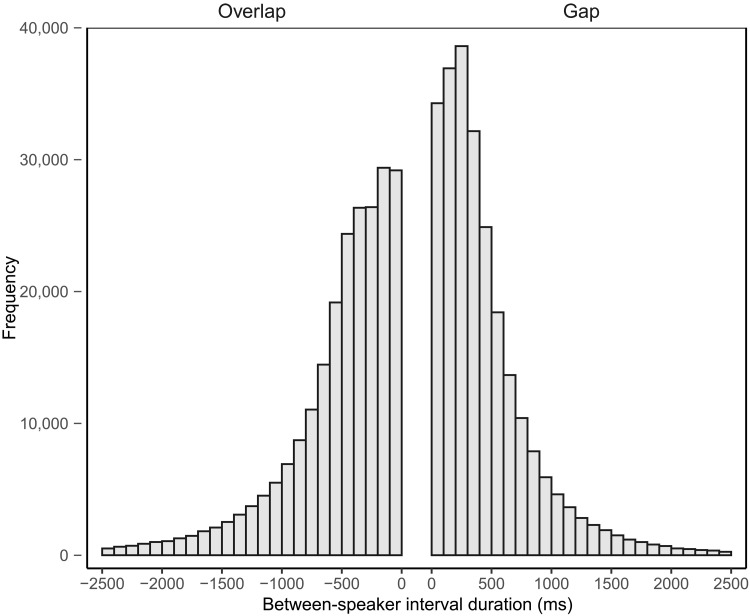
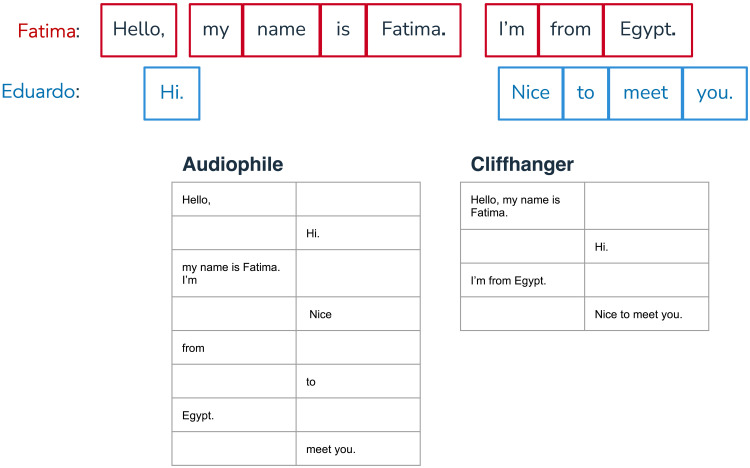
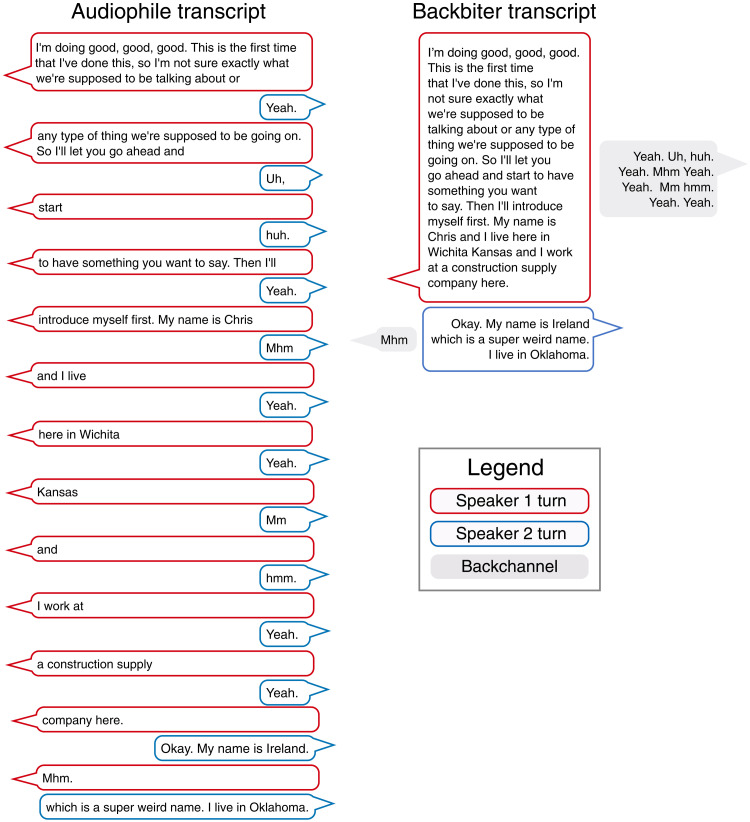
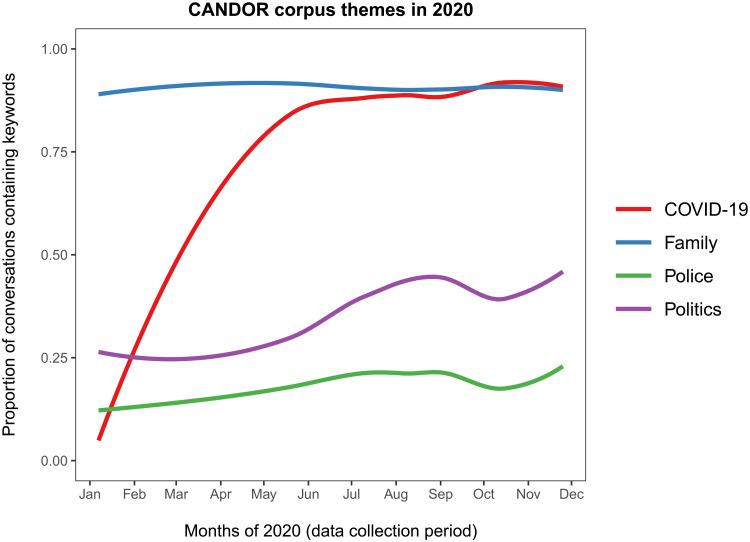
People spend a substantial portion of their lives engaged in conversation, and yet, our scientific understanding of conversation is still in its infancy. Here, we introduce a large, novel, and multimodal corpus of 1656 conversations recorded in spoken English. This 7+ million word, 850-hour corpus totals more than 1 terabyte of audio, video, and transcripts, with moment-to-moment measures of vocal, facial, and semantic expression, together with an extensive survey of speakers' postconversation reflections. By taking advantage of the considerable scope of the corpus, we explore many examples of how this large-scale public dataset may catalyze future research, particularly across disciplinary boundaries, as scholars from a variety of fields appear increasingly interested in the study of conversation.
Figures
References
-
- H. H. Clark, Arenas of Language Use (University of Chicago Press, 1992).
-
- N. J. Enfield, How We Talk: The Inner Workings of Conversation (Basic Books, 2017).
-
- M. J. Pickering, S. Garrod, Understanding Dialogue: Language Use and Social Interaction (Cambridge Univ. Press, 2021).
-
- H. Sacks, E. A. Schegloff, G. Jefferson, A simplest systematics for the organization of turn-taking for conversation, in Studies in the Organization of Conversational Interaction, J. Schenkein, Ed. (Academic Press, 1978), pp. 7–55.
-
- M. Tomasello, Constructing a Language: A Usage-based Theory of Language Acquisition (Harvard Univ. Press, 2003).
MeSH terms
LinkOut - more resources
Full Text Sources
