

Sparse clusterability: testing for cluster structure in high dimensions
- PMID: 37003995
- PMCID: PMC10064666
- DOI: 10.1186/s12859-023-05210-6
Sparse clusterability: testing for cluster structure in high dimensions
Abstract
Background: Cluster analysis is utilized frequently in scientific theory and applications to separate data into groups. A key assumption in many clustering algorithms is that the data was generated from a population consisting of multiple distinct clusters. Clusterability testing allows users to question the inherent assumption of latent cluster structure, a theoretical requirement for meaningful results in cluster analysis.
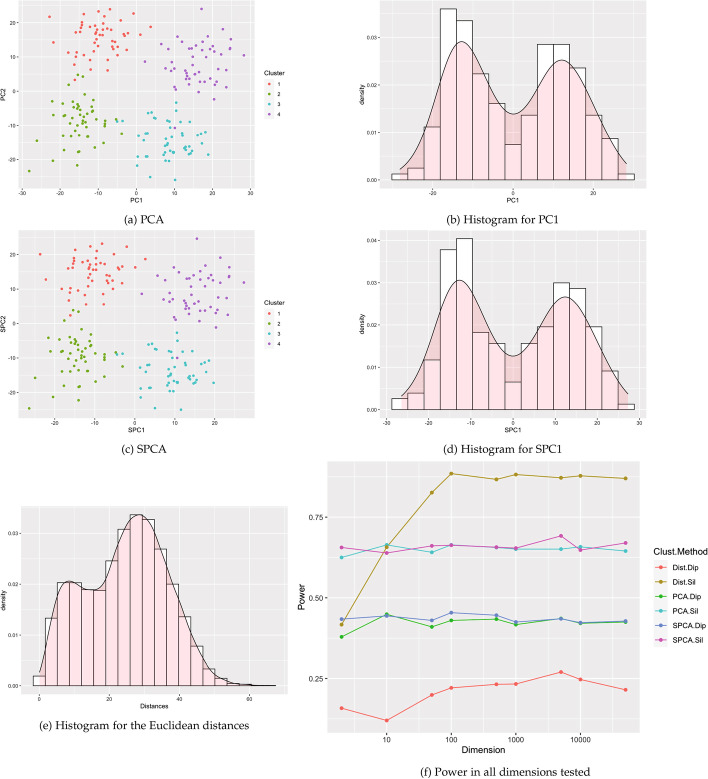
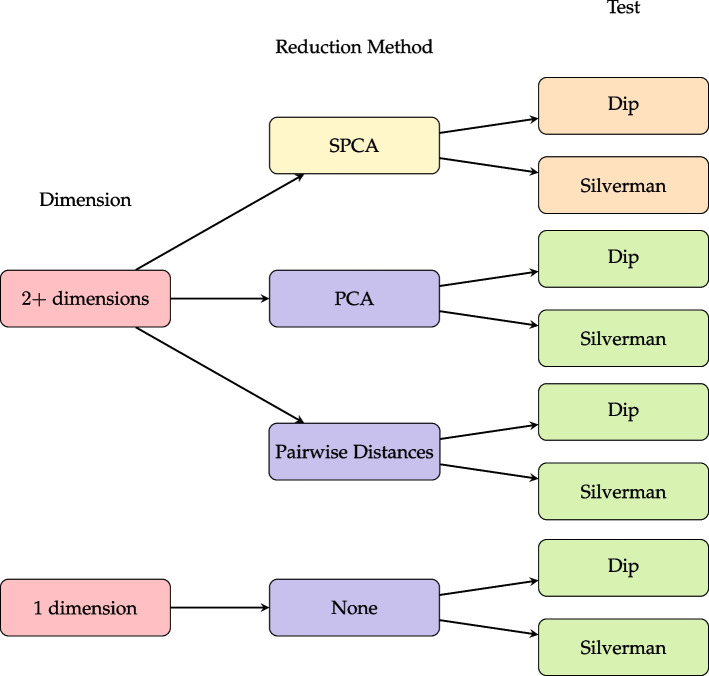
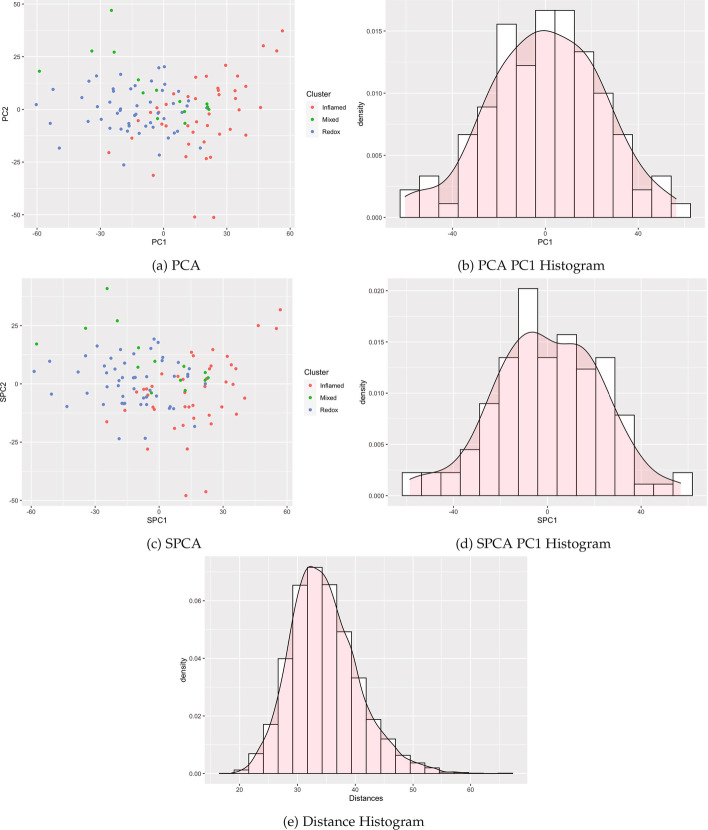
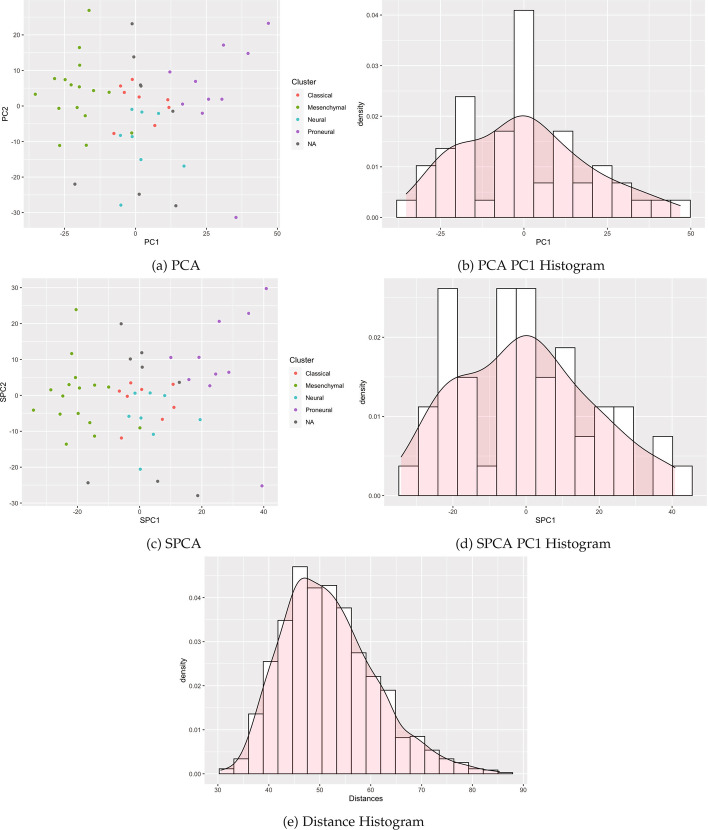
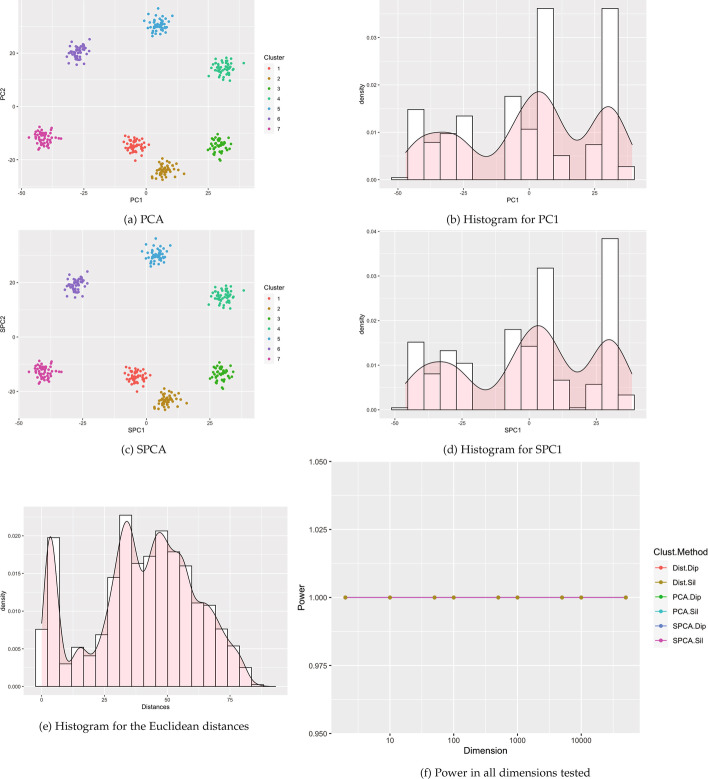
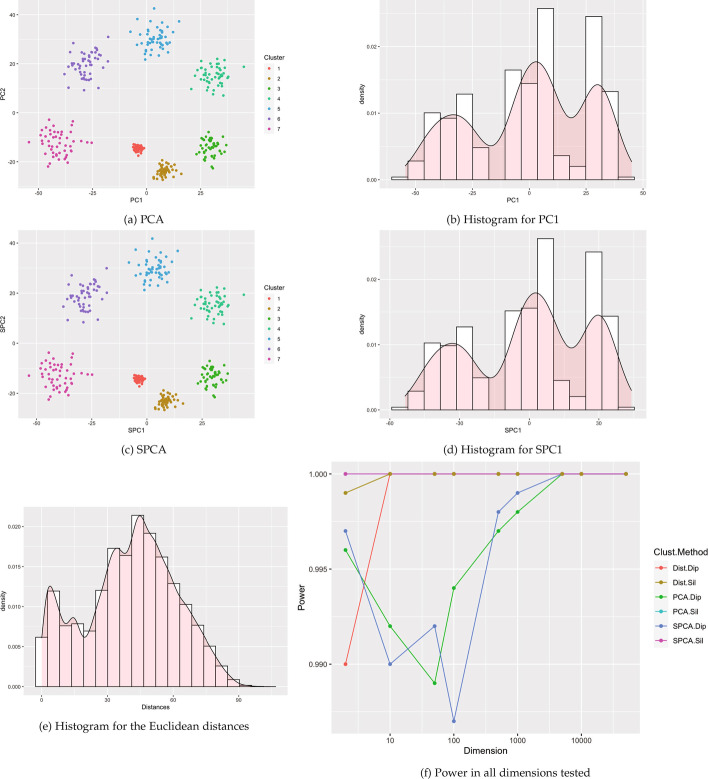
Results: This paper proposes methods for clusterability testing designed for high-dimensional data by utilizing sparse principal component analysis. Type I error and power of the clusterability tests are evaluated using simulated data with different types of cluster structure in high dimensions. Empirical performance of the new methods is evaluated and compared with prior methods on gene expression, microarray, and shotgun proteomics data. Our methods had reasonably low Type I error and maintained power for many datasets with a variety of structures and dimensions. Cluster structure was not detectable in other datasets with spatially close clusters.
Conclusion: This is the first analysis of clusterability testing on both simulated and real-world high-dimensional data.
Keywords: Big data; Cluster analysis; Cluster tendency; Clustering; Dimension reduction; Distance metrics; Multimodality testing; Principal component analysis; Sparsity.
© 2023. The Author(s).
Conflict of interest statement
NCB served as an ad hoc reviewer in 2020 for the American Cancer Society, for which she received sponsored travel during the review meeting and a stipend of US $300. NCB received a series of small awards for conference and travel support, including US $500 from the Statistical Consulting Section of the American Statistical Association (ASA) for Best Paper Award at the 2019 Joint Statistical Meetings. Currently, NCB serves as the Vice President for the Florida Chapter of the ASA and Section Representative for the ASA Statistical Consulting Section, and on the Regional Committee for the Eastern North American Region of the International Biometrics Society. Previously, NCB served as the Florida ASA Chapter Representative, as the mentoring subcommittee chair for the Regional Advisory Board of the Eastern North American Region of the International Biometrics Society, and on the Scientific Review Board at Moffitt Cancer Center. JL is the Information Officer for the ASA Florida Chapter. YAC currently serves on the Scientific Review Board at Moffitt Cancer Center.
Figures




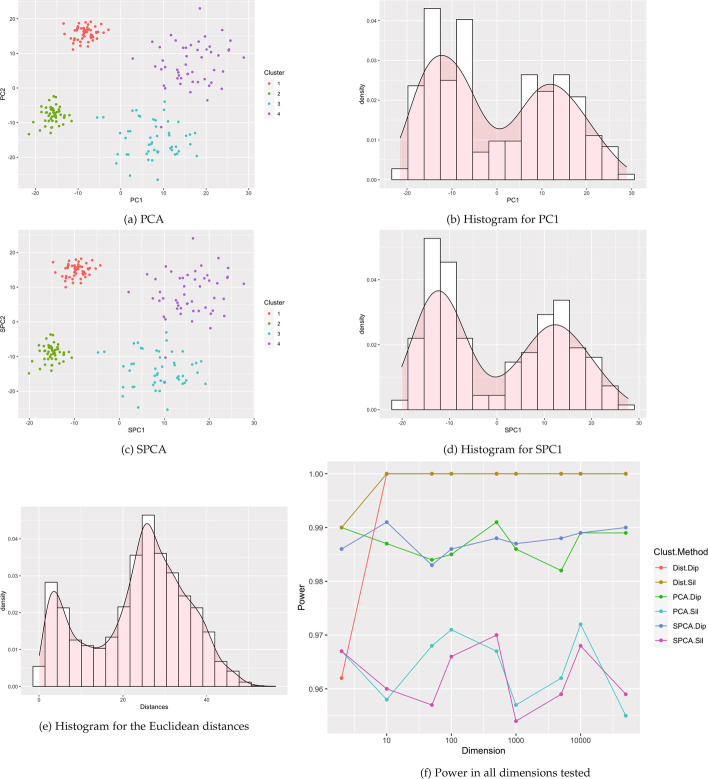

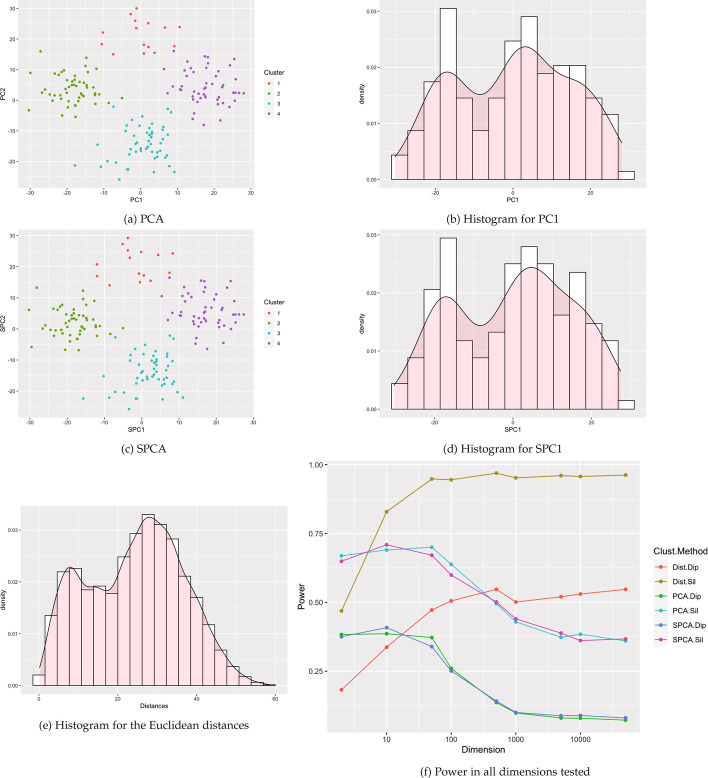

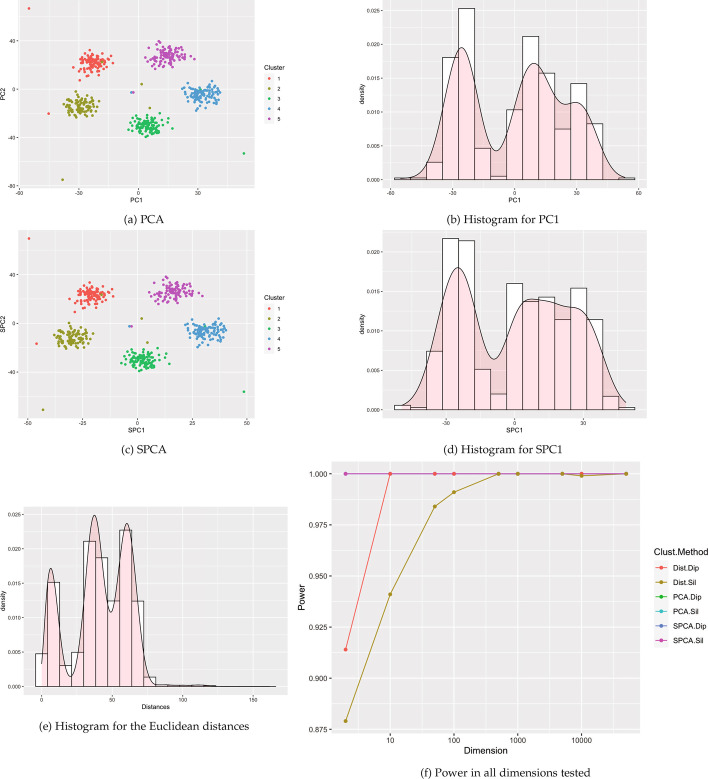
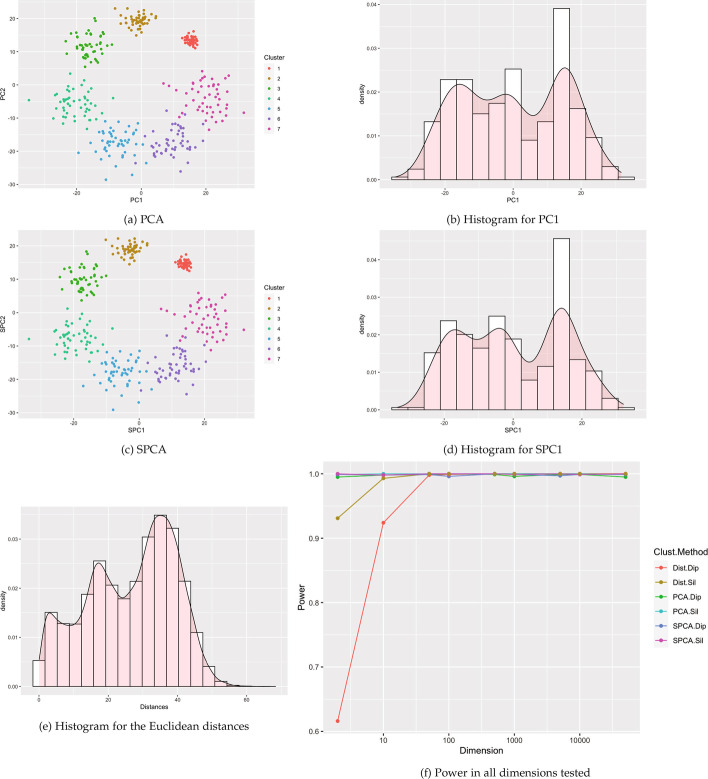
References
-
- Adolfsson A, Ackerman M, Brownstein NC. To cluster, or not to cluster: an analysis of clusterability methods. Pattern Recognit. 2019;88:13–26. doi: 10.1016/j.patcog.2018.10.026. - DOI
-
- Zou H, Hastie T, Tibshirani R. Sparse principal component analysis. J Comput Graph Stat. 2006;15(2):265–286. doi: 10.1198/106186006X113430. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
