

Deep learning-based polygenic risk analysis for Alzheimer's disease prediction
- PMID: 37024668
- PMCID: PMC10079691
- DOI: 10.1038/s43856-023-00269-x
Deep learning-based polygenic risk analysis for Alzheimer's disease prediction
Abstract
Background: The polygenic nature of Alzheimer's disease (AD) suggests that multiple variants jointly contribute to disease susceptibility. As an individual's genetic variants are constant throughout life, evaluating the combined effects of multiple disease-associated genetic risks enables reliable AD risk prediction. Because of the complexity of genomic data, current statistical analyses cannot comprehensively capture the polygenic risk of AD, resulting in unsatisfactory disease risk prediction. However, deep learning methods, which capture nonlinearity within high-dimensional genomic data, may enable more accurate disease risk prediction and improve our understanding of AD etiology. Accordingly, we developed deep learning neural network models for modeling AD polygenic risk.
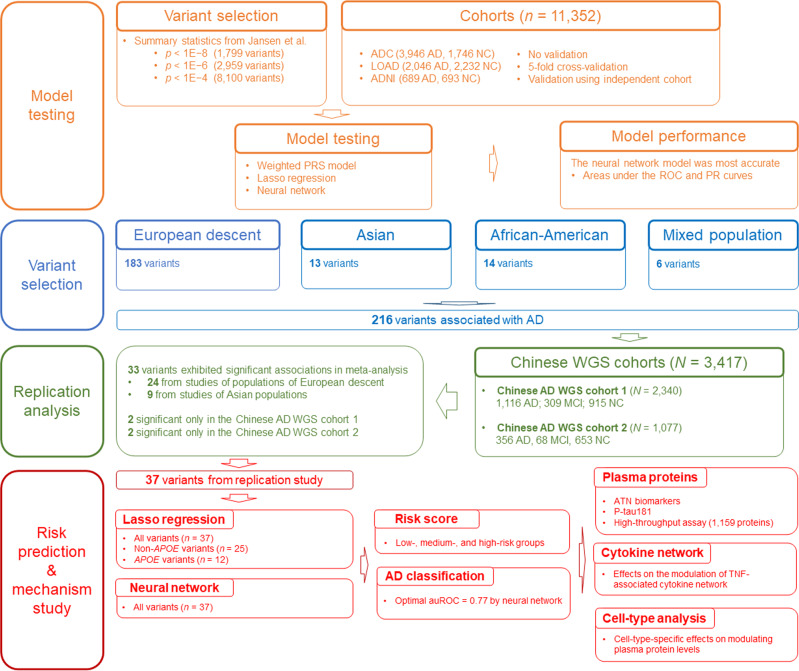
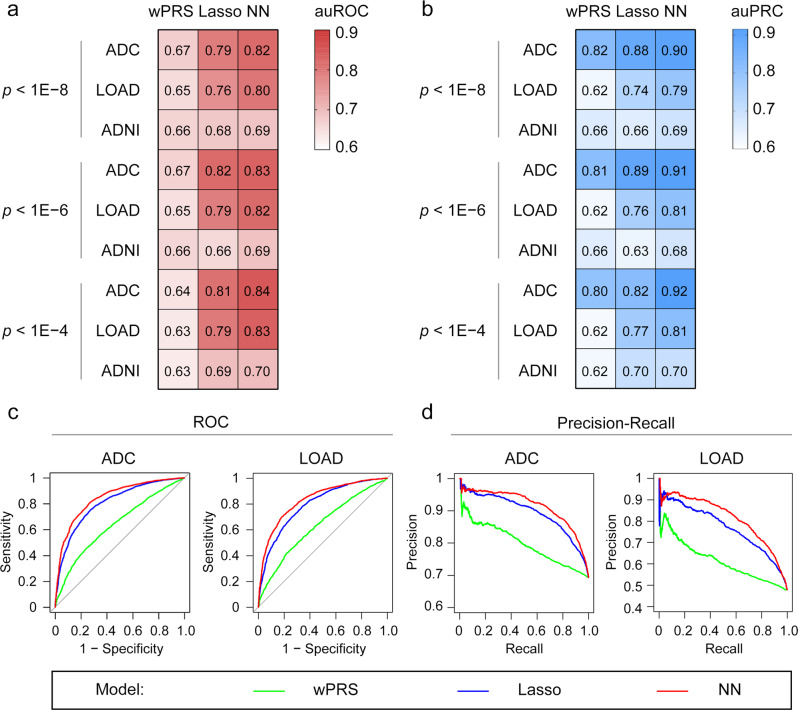
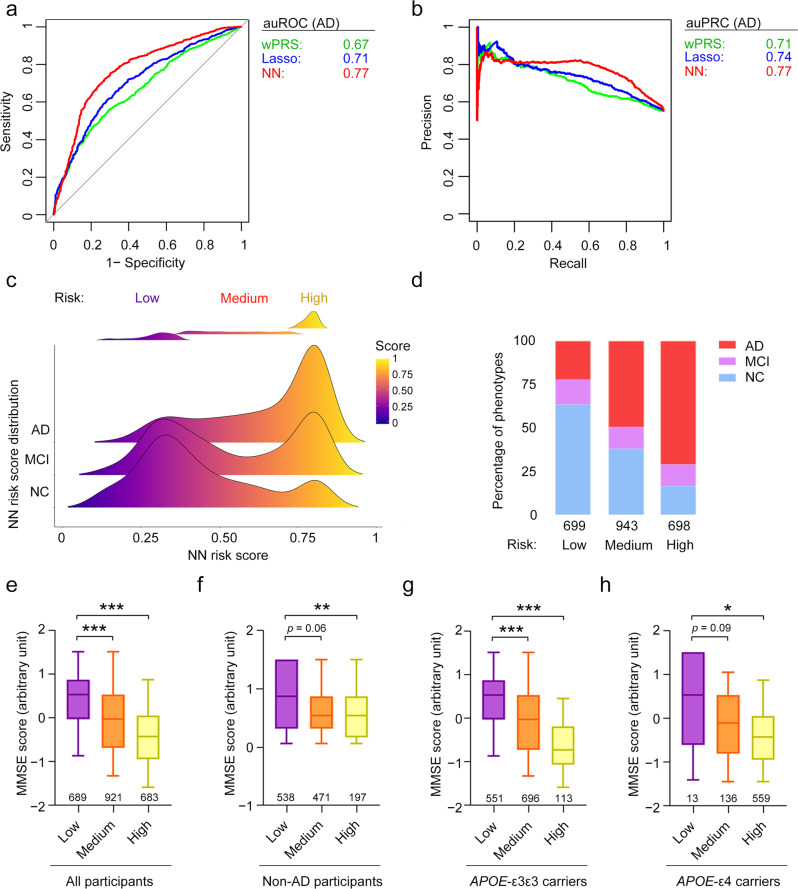
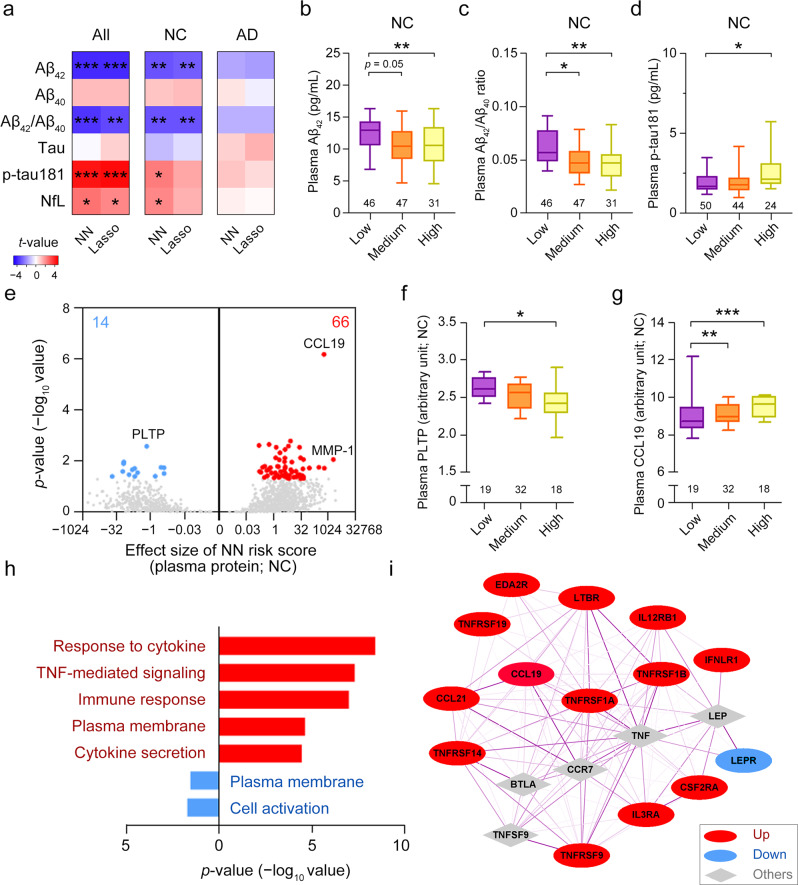
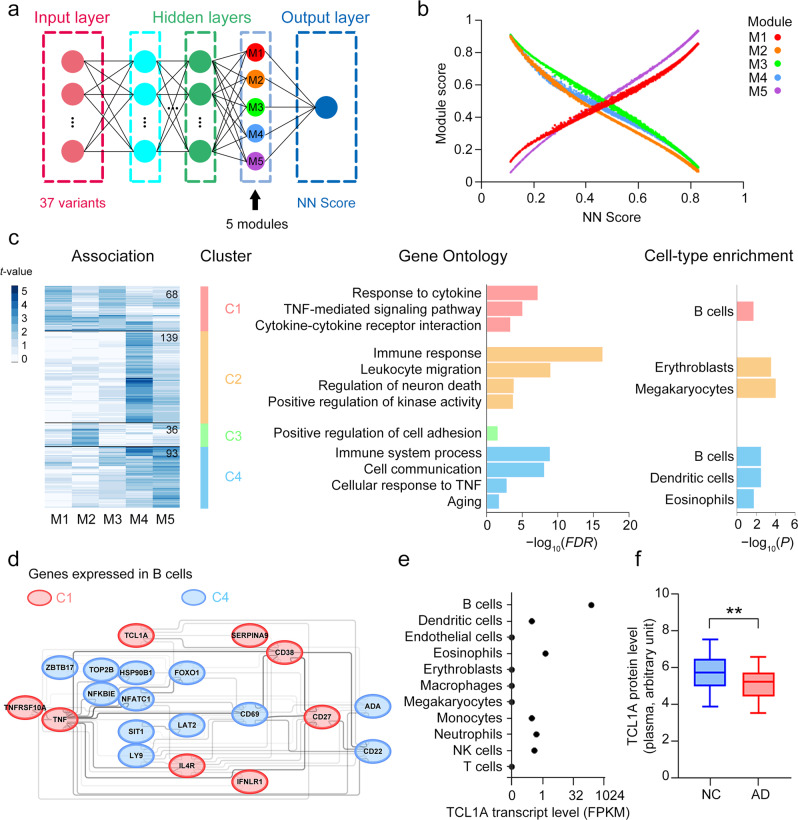
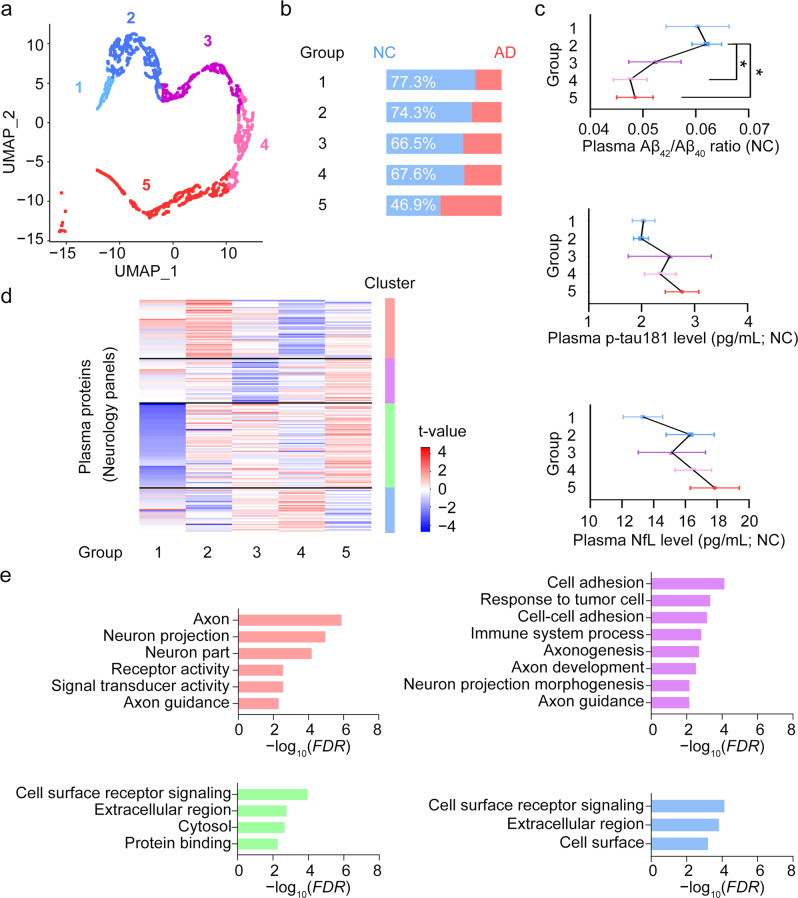
Methods: We constructed neural network models to model AD polygenic risk and compared them with the widely used weighted polygenic risk score and lasso models. We conducted robust linear regression analysis to investigate the relationship between the AD polygenic risk derived from deep learning methods and AD endophenotypes (i.e., plasma biomarkers and individual cognitive performance). We stratified individuals by applying unsupervised clustering to the outputs from the hidden layers of the neural network model.
Results: The deep learning models outperform other statistical models for modeling AD risk. Moreover, the polygenic risk derived from the deep learning models enables the identification of disease-associated biological pathways and the stratification of individuals according to distinct pathological mechanisms.
Conclusion: Our results suggest that deep learning methods are effective for modeling the genetic risks of AD and other diseases, classifying disease risks, and uncovering disease mechanisms.
Plain language summary
Polygenic diseases, such as Alzheimer’s disease (AD), are those caused by the interplay between multiple genetic risk factors. Statistical models can be used to predict disease risk based on a person’s genetic profile. However, there are limitations to existing methods, while emerging methods such as deep learning may improve risk prediction. Deep learning involves computer-based software learning from patterns in data to perform a certain task, e.g. predict disease risk. Here, we test whether deep learning models can help to predict AD risk. Our models not only outperformed existing methods in modeling AD risk, they also allow us to estimate an individual’s risk of AD and determine the biological processes that may be involved in AD. With further testing and optimization, deep learning may be a useful tool to help accurately predict risk of AD and other diseases.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Hardy J. The amyloid hypothesis of Alzheimer’s disease: progress and problems on the road to therapeutics. Science (1979) 2002;297:353–356. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
