

EnsMOD: A Software Program for Omics Sample Outlier Detection
- PMID: 37042708
- PMCID: PMC10282819
- DOI: 10.1089/cmb.2022.0243
EnsMOD: A Software Program for Omics Sample Outlier Detection
Abstract
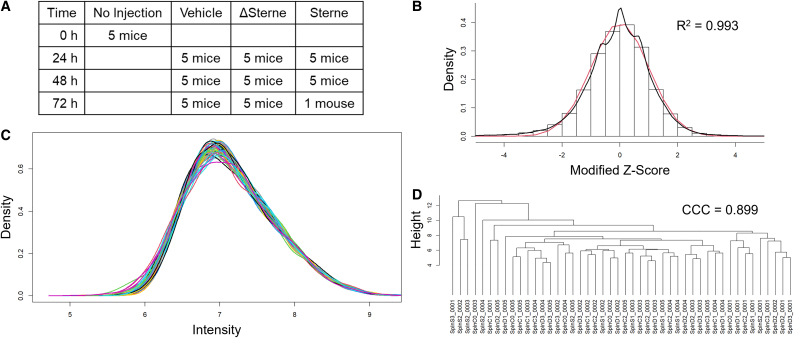
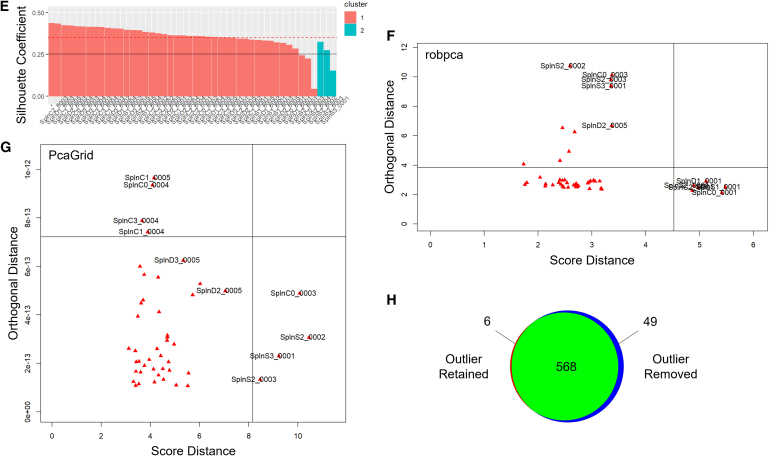
Detection of omics sample outliers is important for preventing erroneous biological conclusions, developing robust experimental protocols, and discovering rare biological states. Two recent publications describe robust algorithms for detecting transcriptomic sample outliers, but neither algorithm had been incorporated into a software tool for scientists. Here we describe Ensemble Methods for Outlier Detection (EnsMOD) which incorporates both algorithms. EnsMOD calculates how closely the quantitation variation follows a normal distribution, plots the density curves of each sample to visualize anomalies, performs hierarchical cluster analyses to calculate how closely the samples cluster with each other, and performs robust principal component analyses to statistically test if any sample is an outlier. The probabilistic threshold parameters can be easily adjusted to tighten or loosen the outlier detection stringency. EnsMOD can be used to analyze any omics dataset with normally distributed variance. Here it was used to analyze a simulated proteomics dataset, a multiomic (proteome and transcriptome) dataset, a single-cell proteomics dataset, and a phosphoproteomics dataset. EnsMOD successfully identified all of the simulated outliers, and subsequent removal of a detected outlier improved data quality for downstream statistical analyses.
Keywords: hierarchical cluster analysis; multivariate; omics; outlier detection; proteomics; robust principal component analysis.
Conflict of interest statement
The authors declare they have no conflicting financial interests.
Figures
References
-
- Aggarwal CC. Outlier Analysis, 2nd ed. Springer International Publishing AG: Cham, Switzerland; 2017; doi: 10.1007/978-3-319-47578-3 - DOI
-
- Charrad M, Ghazzali N, Boiteau V, et al. . NbClust: An R package for determining the relevant number of clusters in a data set. J Stat Softw 2014;61:1–36; doi: 10.18637/jss.v061.i06 - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
