

Aggregating Different Scales of Attention on Feature Variants for Tomato Leaf Disease Diagnosis from Image Data: A Transformer Driven Study
- PMID: 37050811
- PMCID: PMC10099258
- DOI: 10.3390/s23073751
Aggregating Different Scales of Attention on Feature Variants for Tomato Leaf Disease Diagnosis from Image Data: A Transformer Driven Study
Abstract
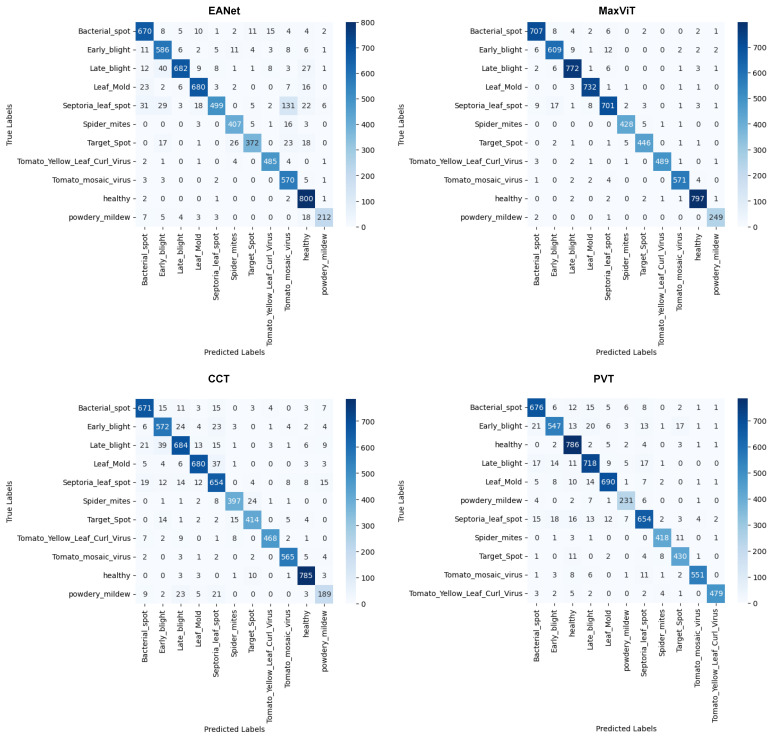
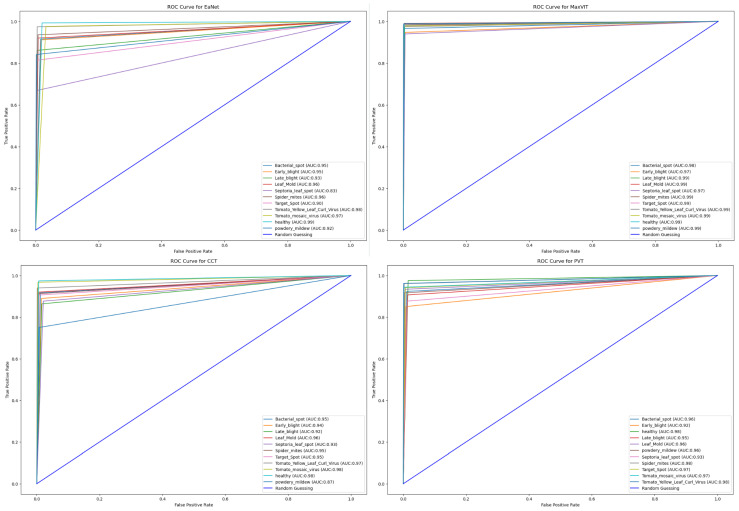
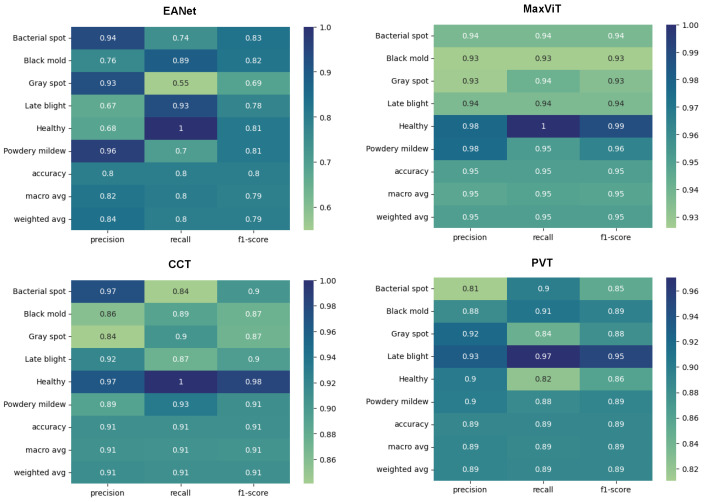
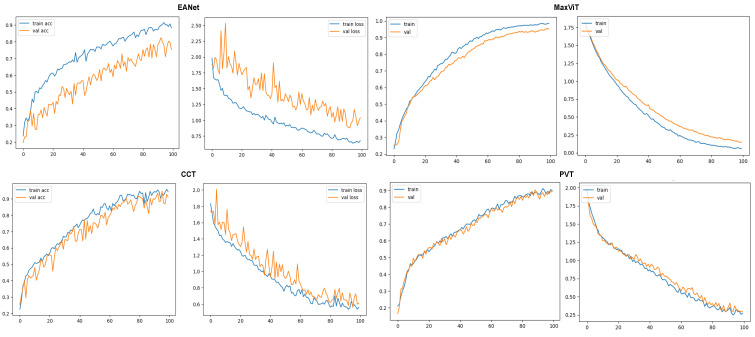
Tomato leaf diseases can incur significant financial damage by having adverse impacts on crops and, consequently, they are a major concern for tomato growers all over the world. The diseases may come in a variety of forms, caused by environmental stress and various pathogens. An automated approach to detect leaf disease from images would assist farmers to take effective control measures quickly and affordably. Therefore, the proposed study aims to analyze the effects of transformer-based approaches that aggregate different scales of attention on variants of features for the classification of tomato leaf diseases from image data. Four state-of-the-art transformer-based models, namely, External Attention Transformer (EANet), Multi-Axis Vision Transformer (MaxViT), Compact Convolutional Transformers (CCT), and Pyramid Vision Transformer (PVT), are trained and tested on a multiclass tomato disease dataset. The result analysis showcases that MaxViT comfortably outperforms the other three transformer models with 97% overall accuracy, as opposed to the 89% accuracy achieved by EANet, 91% by CCT, and 93% by PVT. MaxViT also achieves a smoother learning curve compared to the other transformers. Afterwards, we further verified the legitimacy of the results on another relatively smaller dataset. Overall, the exhaustive empirical analysis presented in the paper proves that the MaxViT architecture is the most effective transformer model to classify tomato leaf disease, providing the availability of powerful hardware to incorporate the model.
Keywords: CCT; EANet; MaxViT; PVT; attention; tomato leaf disease; transformers.
Conflict of interest statement
The authors declare no conflict of interest.
Figures


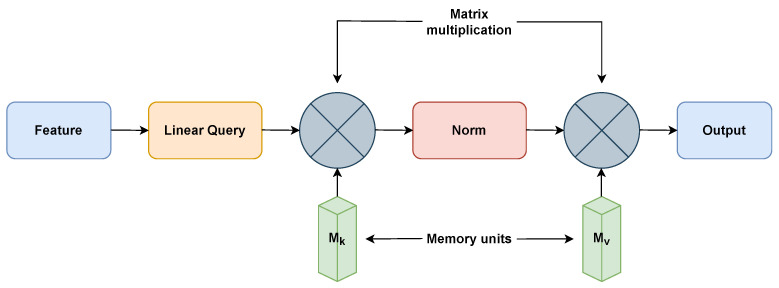
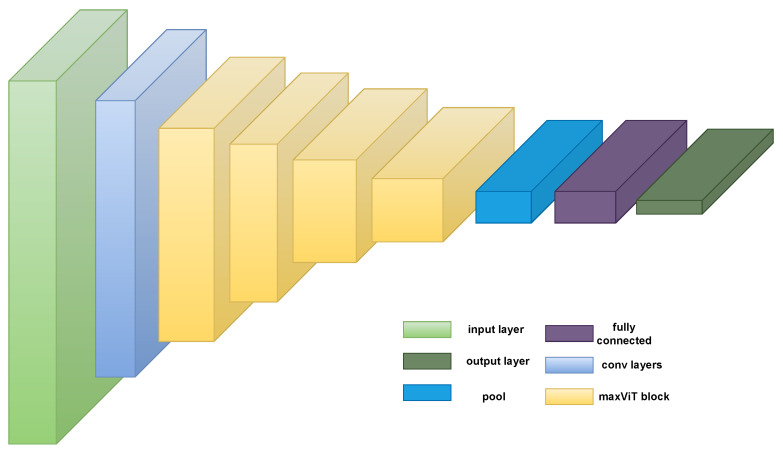
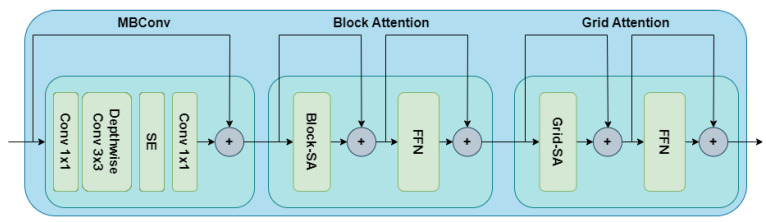
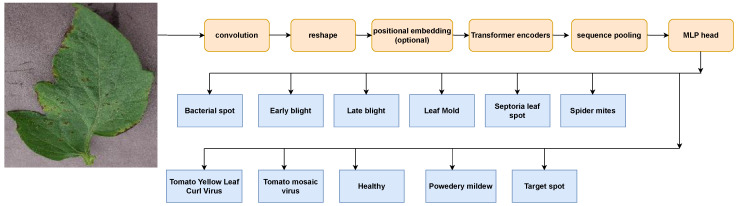
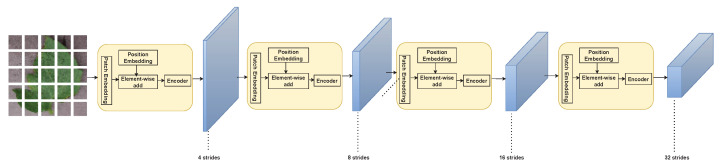
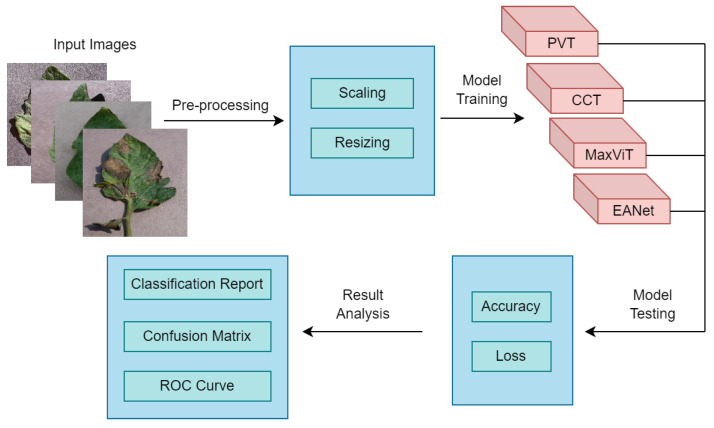
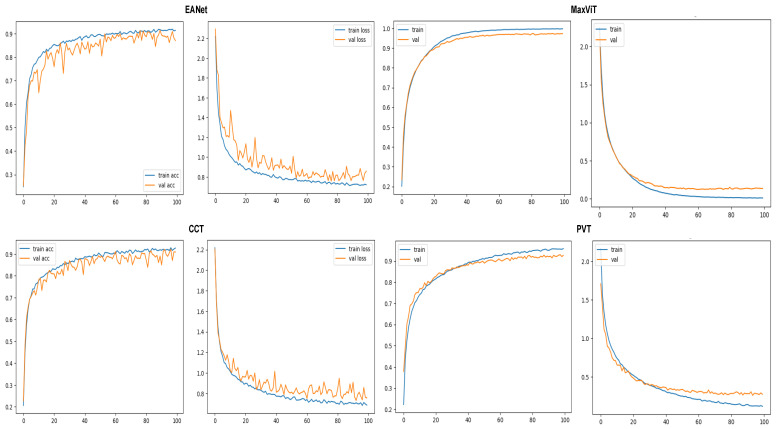
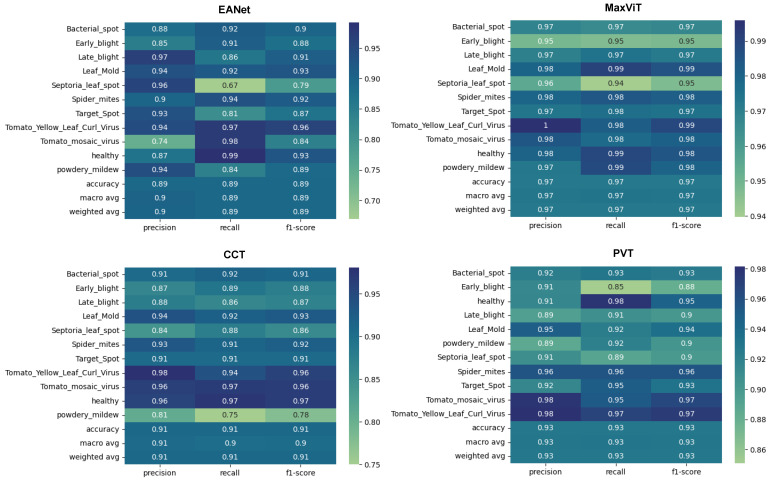

References
-
- Kaselimi M., Voulodimos A., Daskalopoulos I., Doulamis N., Doulamis A. A Vision Transformer Model for Convolution-Free Multilabel Classification of Satellite Imagery in Deforestation Monitoring. IEEE Trans. Neural Netw. Learn. Syst. Early Access. 2022:1–9. doi: 10.1109/TNNLS.2022.3144791. - DOI - PubMed
-
- Wang L., Fang S., Meng X., Li R. Building Extraction With Vision Transformer. IEEE Trans. Geosci. Remote Sens. 2022;60:1–11. doi: 10.1109/TGRS.2022.3186634. - DOI
-
- Meng X., Wang N., Shao F., Li S. Vision Transformer for Pansharpening. IEEE Trans. Geosci. Remote Sens. 2022;60:1–11. doi: 10.1109/TGRS.2022.3168465. - DOI
-
- Wang T., Gong L., Wang C., Yang Y., Gao Y., Zhou X., Chen H. ViA: A Novel Vision-Transformer Accelerator Based on FPGA. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2022;41:4088–4099. doi: 10.1109/TCAD.2022.3197489. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
