

This is a preprint.
A single-cell transcriptional timelapse of mouse embryonic development, from gastrula to pup
- PMID: 37066300
- PMCID: PMC10104014
- DOI: 10.1101/2023.04.05.535726
A single-cell transcriptional timelapse of mouse embryonic development, from gastrula to pup
Update in
-
A single-cell time-lapse of mouse prenatal development from gastrula to birth.Nature. 2024 Feb;626(8001):1084-1093. doi: 10.1038/s41586-024-07069-w. Epub 2024 Feb 14. Nature. 2024. PMID: 38355799 Free PMC article.
Abstract
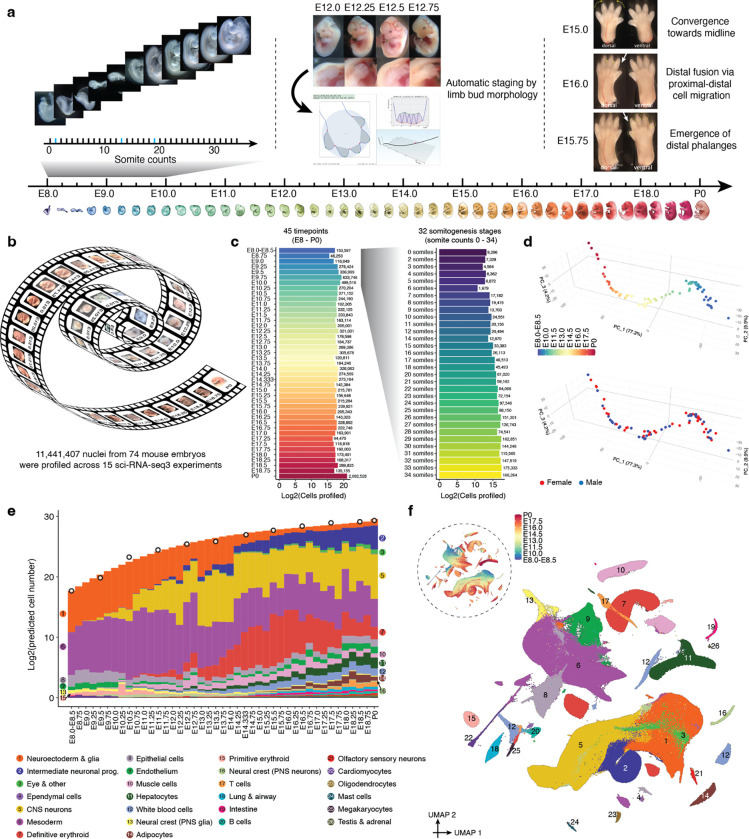
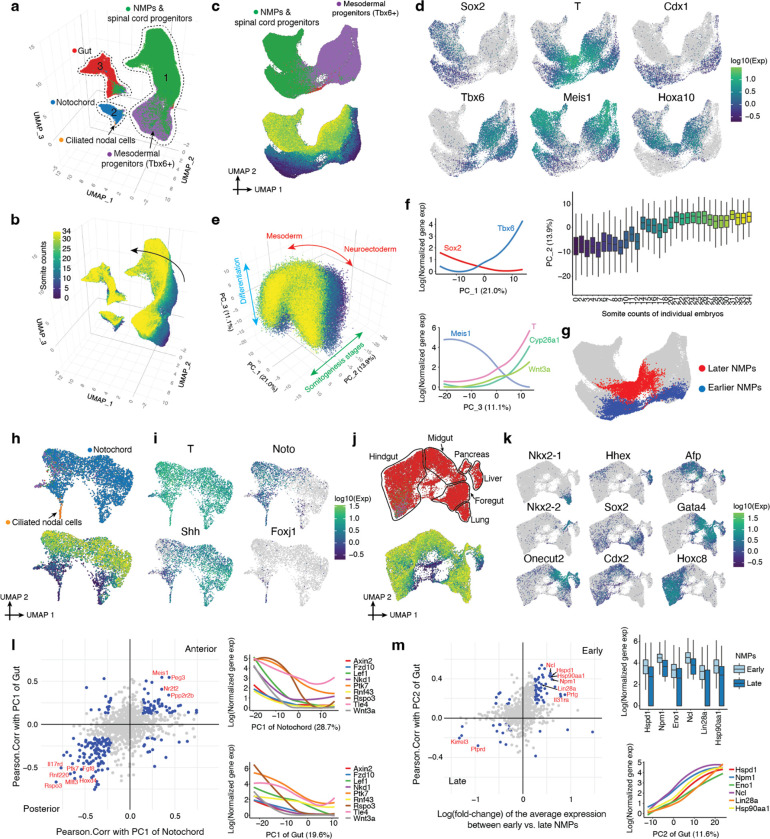
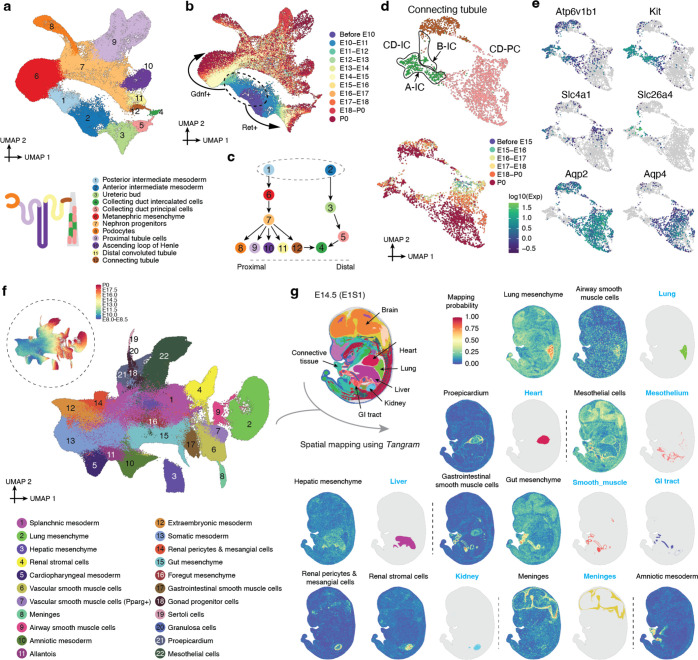
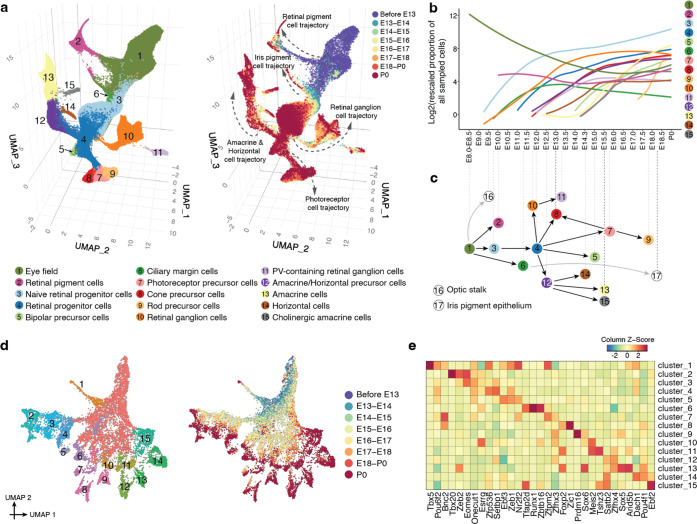
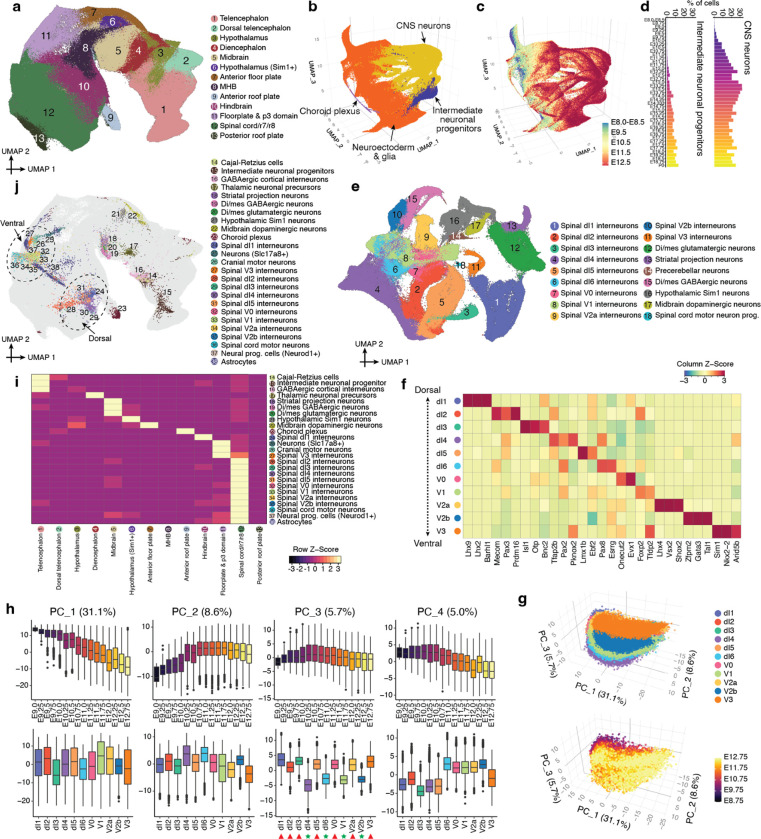
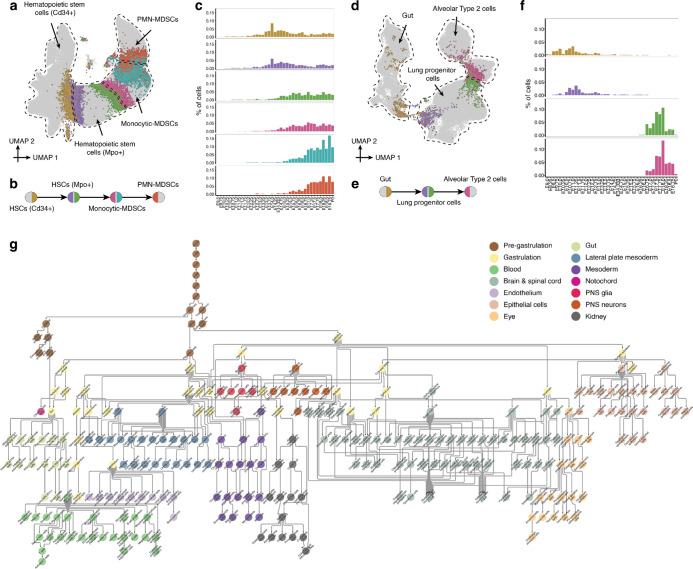
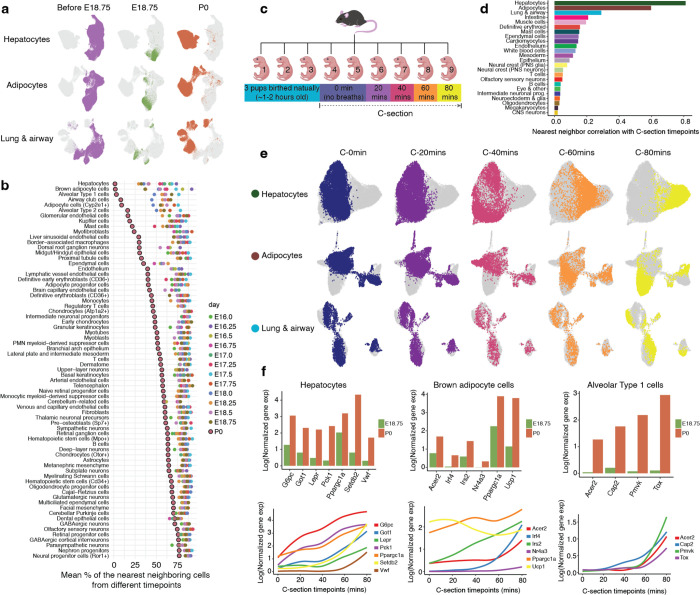
The house mouse, Mus musculus, is an exceptional model system, combining genetic tractability with close homology to human biology. Gestation in mouse development lasts just under three weeks, a period during which its genome orchestrates the astonishing transformation of a single cell zygote into a free-living pup composed of >500 million cells. Towards a global framework for exploring mammalian development, we applied single cell combinatorial indexing (sci-*) to profile the transcriptional states of 12.4 million nuclei from 83 precisely staged embryos spanning late gastrulation (embryonic day 8 or E8) to birth (postnatal day 0 or P0), with 2-hr temporal resolution during somitogenesis, 6-hr resolution through to birth, and 20-min resolution during the immediate postpartum period. From these data (E8 to P0), we annotate dozens of trajectories and hundreds of cell types and perform deeper analyses of the unfolding of the posterior embryo during somitogenesis as well as the ontogenesis of the kidney, mesenchyme, retina, and early neurons. Finally, we leverage the depth and temporal resolution of these whole embryo snapshots, together with other published data, to construct and curate a rooted tree of cell type relationships that spans mouse development from zygote to pup. Throughout this tree, we systematically nominate sets of transcription factors (TFs) and other genes as candidate drivers of the in vivo differentiation of hundreds of mammalian cell types. Remarkably, the most dramatic shifts in transcriptional state are observed in a restricted set of cell types in the hours immediately following birth, and presumably underlie the massive changes in physiology that must accompany the successful transition of a placental mammal to extrauterine life.
Conflict of interest statement
Competing Financial Interests Statement J.S. is a scientific advisory board member, consultant and/or co-founder of Scale Biosciences, Prime Medicine, Cajal Neuroscience, Guardant Health, Maze Therapeutics, Camp4 Therapeutics, Phase Genomics, Adaptive Biotechnologies, Sixth Street Capital and Pacific Biosciences. C.T. is a co-founder of Scale Biosciences. All other authors declare no competing interests.
Figures
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases