

The ENCODE Imputation Challenge: a critical assessment of methods for cross-cell type imputation of epigenomic profiles
- PMID: 37072822
- PMCID: PMC10111747
- DOI: 10.1186/s13059-023-02915-y
The ENCODE Imputation Challenge: a critical assessment of methods for cross-cell type imputation of epigenomic profiles
Erratum in
-
Publisher Correction: The ENCODE Imputation Challenge: a critical assessment of methods for cross-cell type imputation of epigenomic profiles.Genome Biol. 2025 Feb 13;26(1):31. doi: 10.1186/s13059-025-03494-w. Genome Biol. 2025. PMID: 39948633 Free PMC article. No abstract available.
Abstract
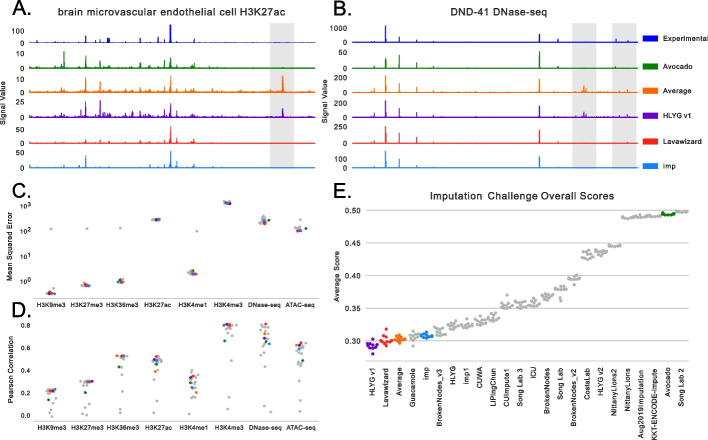
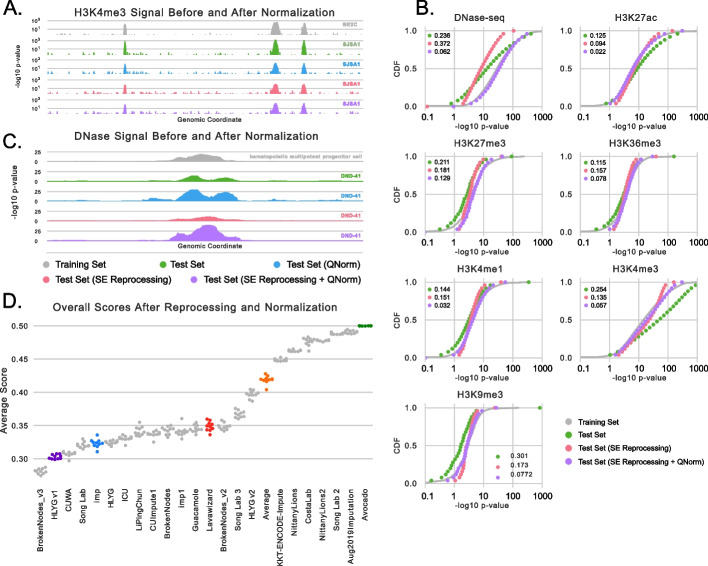
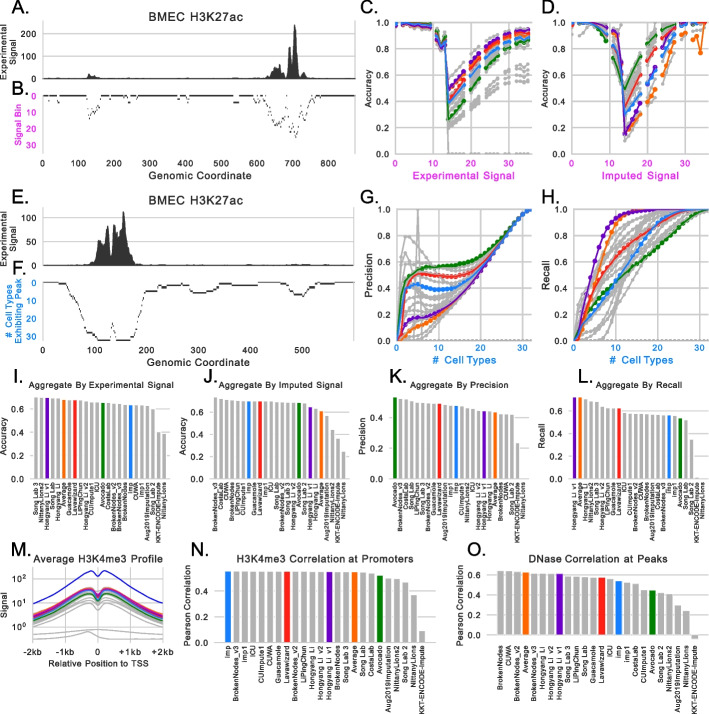
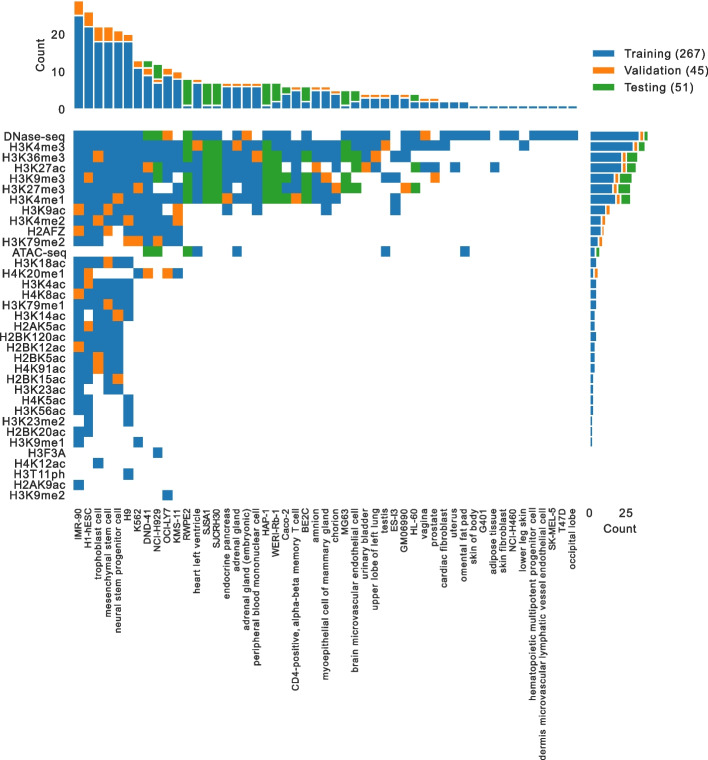
A promising alternative to comprehensively performing genomics experiments is to, instead, perform a subset of experiments and use computational methods to impute the remainder. However, identifying the best imputation methods and what measures meaningfully evaluate performance are open questions. We address these questions by comprehensively analyzing 23 methods from the ENCODE Imputation Challenge. We find that imputation evaluations are challenging and confounded by distributional shifts from differences in data collection and processing over time, the amount of available data, and redundancy among performance measures. Our analyses suggest simple steps for overcoming these issues and promising directions for more robust research.
© 2023. The Author(s).
Conflict of interest statement
A.K. is a scientific co-founder of Ravel Biotechnology Inc., is on the scientific advisory board of PatchBio Inc., SerImmune Inc., AINovo Inc., TensorBio Inc. and OpenTargets, is a consultant with Illumina Inc., and owns shares in DeepGenomics Inc., Immuni Inc., and Freenome Inc. M.S. is a cofounder and scientific advisor of Personalis, SensOmics, Qbio, January AI, Fodsel, Filtricine, Protos, RTHM, Iollo, Marble Therapeutics, and Mirvie. He is a scientific advisor of Genapsys, Jupiter, Neuvivo, Swaza, and Mitrix. The remaining authors declare no competing interests.
Figures
References
-
- Stunnenberg HG, International Human Epigenome Consortium, Hirst M. The International Human Epigenome Consortium: a blueprint for scientific collaboration and discovery. Cell. 2016;167(5):1145–1149. - PubMed
-
- GTEx Consortium, Laboratory, Data Analysis &Coordinating Center (LDACC)—Analysis Working Group, Statistical Methods groups—Analysis Working Group, Enhancing GTEx (eGTEx) groups, NIH Common Fund, NIH/NCI, et al. Genetic effects on gene expression across human tissues. Nature. 2017;550(7675):204–213. - PMC - PubMed
Publication types
MeSH terms
Grants and funding
- U24 HG009397/HG/NHGRI NIH HHS/United States
- R01 HG008155/HG/NHGRI NIH HHS/United States
- UM1 HG009444/HG/NHGRI NIH HHS/United States
- R35 GM134922/GM/NIGMS NIH HHS/United States
- R35 GM124952/GM/NIGMS NIH HHS/United States
- R01 HG011466/HG/NHGRI NIH HHS/United States
- R35 GM133346/GM/NIGMS NIH HHS/United States
- T32 HG000044/HG/NHGRI NIH HHS/United States
- U24 HG009446/HG/NHGRI NIH HHS/United States
- UM1 HG009442/HG/NHGRI NIH HHS/United States
- UM1 HG009390/HG/NHGRI NIH HHS/United States
- U01 HG012069/HG/NHGRI NIH HHS/United States
LinkOut - more resources
Full Text Sources
