

Decision heuristics in contexts integrating action selection and execution
- PMID: 37081031
- PMCID: PMC10119283
- DOI: 10.1038/s41598-023-33008-2
Decision heuristics in contexts integrating action selection and execution
Abstract
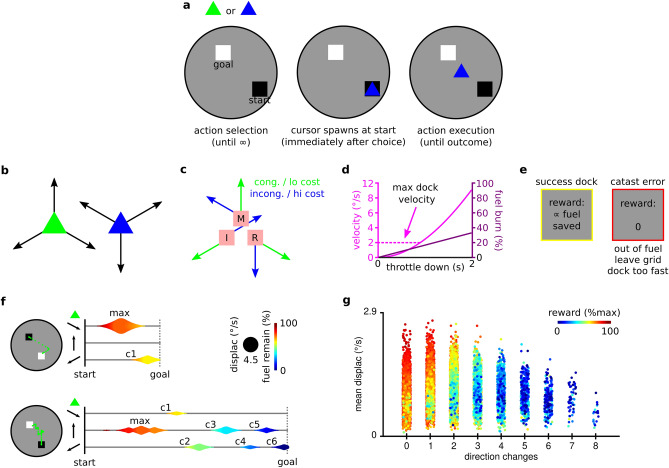
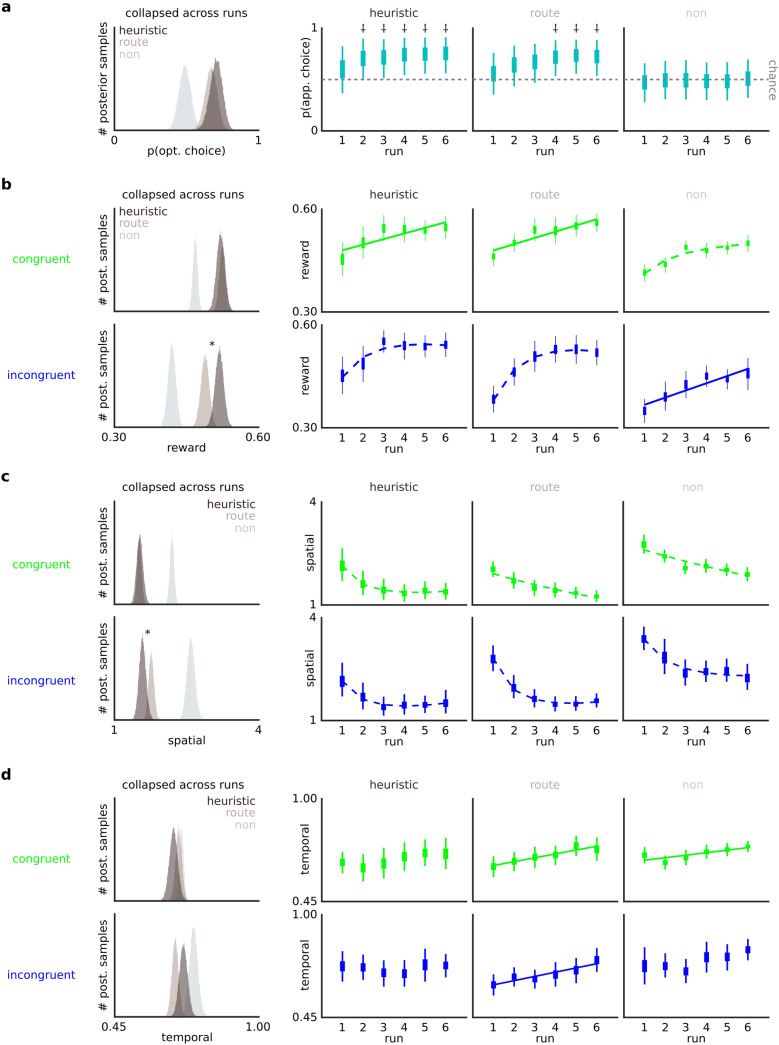
Heuristics can inform human decision making in complex environments through a reduction of computational requirements (accuracy-resource trade-off) and a robustness to overparameterisation (less-is-more). However, tasks capturing the efficiency of heuristics typically ignore action proficiency in determining rewards. The requisite movement parameterisation in sensorimotor control questions whether heuristics preserve efficiency when actions are nontrivial. We developed a novel action selection-execution task requiring joint optimisation of action selection and spatio-temporal skillful execution. State-appropriate choices could be determined by a simple spatial heuristic, or by more complex planning. Computational models of action selection parsimoniously distinguished human participants who adopted the heuristic from those using a more complex planning strategy. Broader comparative analyses then revealed that participants using the heuristic showed combined decisional (selection) and skill (execution) advantages, consistent with a less-is-more framework. In addition, the skill advantage of the heuristic group was predominantly in the core spatial features that also shaped their decision policy, evidence that the dimensions of information guiding action selection might be yoked to salient features in skill learning.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Gilovich T, Griffin D, Kahneman D, editors. Heuristics and Biases: The Psychology of Intuitive Judgment. Cambridge: Cambridge University Press; 2002.
