

Trialling a Large Language Model (ChatGPT) in General Practice With the Applied Knowledge Test: Observational Study Demonstrating Opportunities and Limitations in Primary Care
- PMID: 37083633
- PMCID: PMC10163403
- DOI: 10.2196/46599
Trialling a Large Language Model (ChatGPT) in General Practice With the Applied Knowledge Test: Observational Study Demonstrating Opportunities and Limitations in Primary Care
Abstract
Background: Large language models exhibiting human-level performance in specialized tasks are emerging; examples include Generative Pretrained Transformer 3.5, which underlies the processing of ChatGPT. Rigorous trials are required to understand the capabilities of emerging technology, so that innovation can be directed to benefit patients and practitioners.
Objective: Here, we evaluated the strengths and weaknesses of ChatGPT in primary care using the Membership of the Royal College of General Practitioners Applied Knowledge Test (AKT) as a medium.
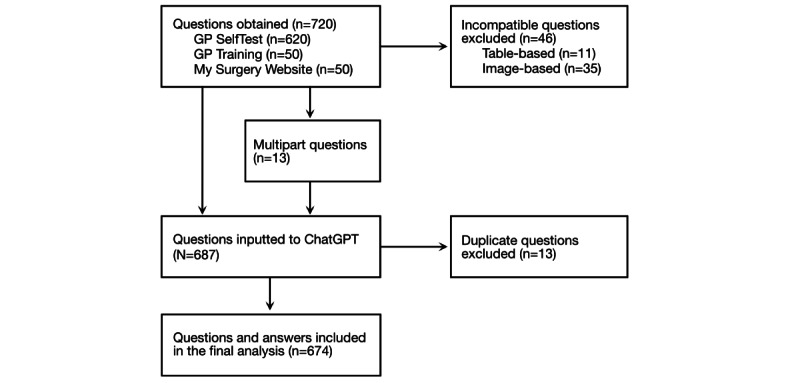
Methods: AKT questions were sourced from a web-based question bank and 2 AKT practice papers. In total, 674 unique AKT questions were inputted to ChatGPT, with the model's answers recorded and compared to correct answers provided by the Royal College of General Practitioners. Each question was inputted twice in separate ChatGPT sessions, with answers on repeated trials compared to gauge consistency. Subject difficulty was gauged by referring to examiners' reports from 2018 to 2022. Novel explanations from ChatGPT-defined as information provided that was not inputted within the question or multiple answer choices-were recorded. Performance was analyzed with respect to subject, difficulty, question source, and novel model outputs to explore ChatGPT's strengths and weaknesses.
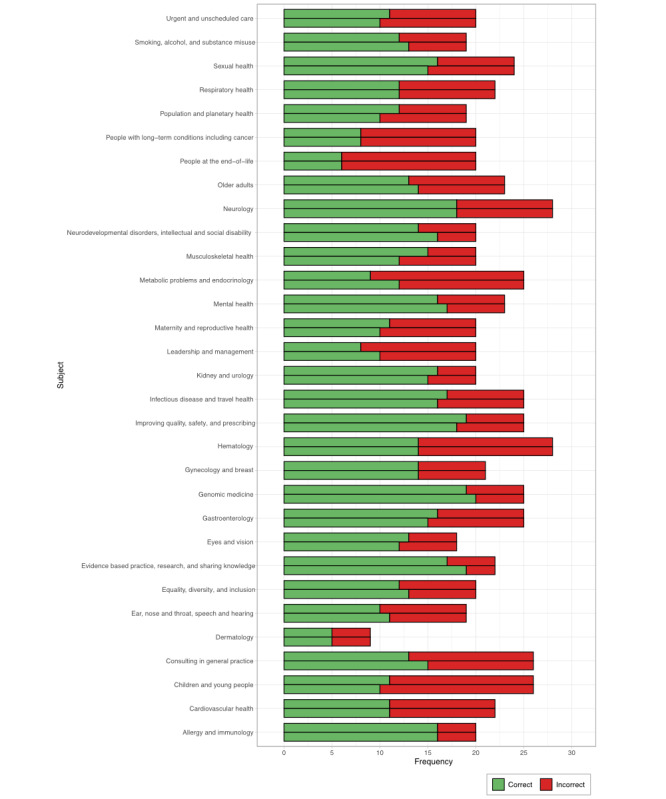
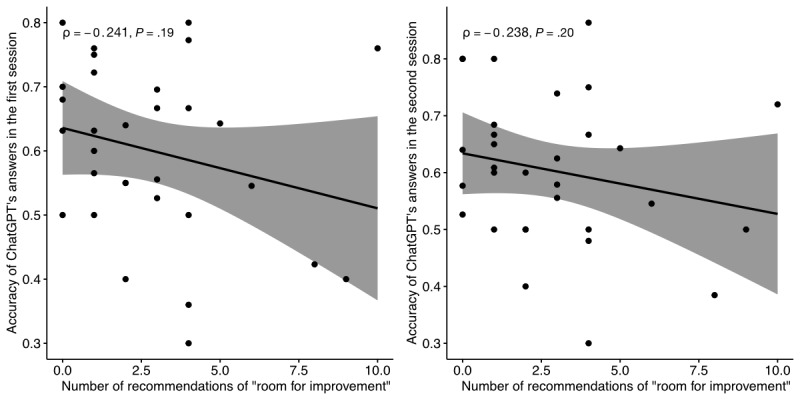
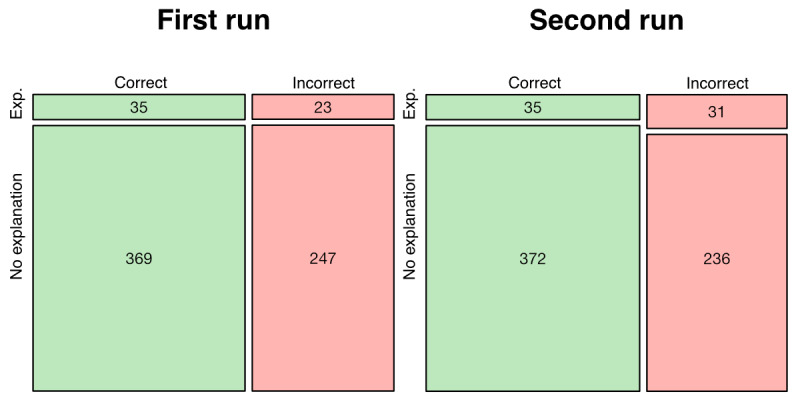
Results: Average overall performance of ChatGPT was 60.17%, which is below the mean passing mark in the last 2 years (70.42%). Accuracy differed between sources (P=.04 and .06). ChatGPT's performance varied with subject category (P=.02 and .02), but variation did not correlate with difficulty (Spearman ρ=-0.241 and -0.238; P=.19 and .20). The proclivity of ChatGPT to provide novel explanations did not affect accuracy (P>.99 and .23).
Conclusions: Large language models are approaching human expert-level performance, although further development is required to match the performance of qualified primary care physicians in the AKT. Validated high-performance models may serve as assistants or autonomous clinical tools to ameliorate the general practice workforce crisis.
Keywords: AI; ChatGPT; artificial intelligence; chatbot; decision support techniques; deep learning; family medicine; general practice; large language model; natural language processing; primary care.
©Arun James Thirunavukarasu, Refaat Hassan, Shathar Mahmood, Rohan Sanghera, Kara Barzangi, Mohanned El Mukashfi, Sachin Shah. Originally published in JMIR Medical Education (https://mededu.jmir.org), 21.04.2023.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, Agarwal S, Herbert-Voss A, Krueger G, Henighan T, Child R, Ramesh A, Ziegler D, Wu J, Winter C, Hesse C, Chen M, Sigler E, Litwin M, Gray S, Chess B, Clark J, Berner C, McCandlish S, Radford A, Sutskever I, Amodei D. Language models are few-shot learners. 34th Conference on Neural Information Processing Systems (NeurIPS 2020); December 6-12, 2020; Vancouver, BC. 2020. https://papers.nips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bf...
-
- Kung TH, Cheatham M, Medenilla A, Sillos C, De Leon L, Elepaño Camille, Madriaga M, Aggabao R, Diaz-Candido G, Maningo J, Tseng V. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLOS Digit Health. 2023 Feb 9;2(2):e0000198. doi: 10.1371/journal.pdig.0000198. https://europepmc.org/abstract/MED/36812645 PDIG-D-22-00371 - DOI - PMC - PubMed
LinkOut - more resources
Full Text Sources
